
基于 scrapy 的百度音乐抓取爬虫
1.scrapy 框架
1.1 scrapy 爬虫项目
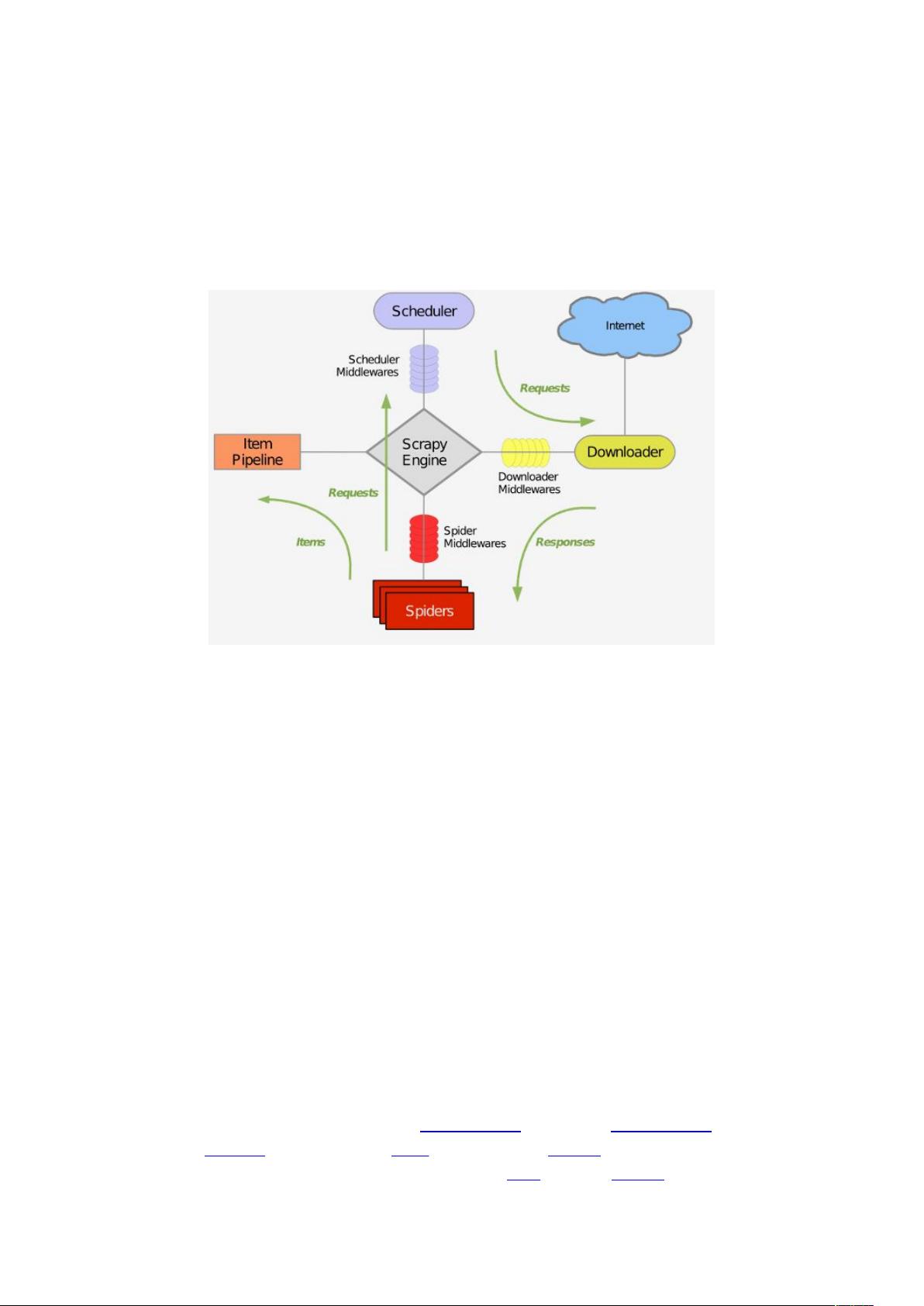
scrapy 是一个基于 Python 的爬虫框架,基本流程是从初始 URL 开始,发送请求给下载器,
下载器抓取网页并将内容返回给爬虫,结果中包含两种重要信息,一个是需要保存的数据
另一个是进一步抓取的链接。将要保存的数据送回 Item Pipeline 项目管道。整体构架如下
图,绿线为数据流向。
当 crapy 安装完成之后,命令行输入 scrapy startproject projectname,scrapy 自动建立一个名
为 projectname 的项目,目录结构:
projectname
projectname
__init__.py
items.py :定义需要提取的数据结构,类似于 python 中的字典结构
pipelines.py :管道,对 items 数据进一步处理,如保存到数据库等
settings.py :爬虫配置文件,设置爬虫深度,爬虫抓取频率等
spiders :爬虫脚本所在目录
__init__.py
spider.py 爬虫核心脚本
scrapy.cfg :项目配置文件
1.2 实现 spider
爬虫脚本在 spiders 文件夹下。首先需要设定爬虫名字,作为爬虫的唯一标识符。
然后需要定义爬虫开始的网址,即 start_url,爬虫会从 start_url 开始下载页面。爬虫脚
本中会自动生成一个 parse 方法,用来解析网页。用 xpath 表达式从网页中提取需要的
对象,赋值给 item 对象或作为进一步抓取的依据。爬取循环如下:
a) 以初始的 URL 初始化 Request,并设置回调函数。 当该 request 下载完毕并返回时,
将生成 response,并作为参数传给该回调函数。
spider 中的 request 是通过调用 start_requests()#来获取的。 start_requests()#读取
start_urls#中的 URL,并以 parse
为回调函数生成 Request#。
b) 在回调函数内分析返回的(网页)内容,返回 Item
对象或者 Request#或者一个包括二






评论2
最新资源