





题目:xxxxxxxxxx
学院:
姓名:
班级:
学号:
二 ○ 二 二 年 十二 月
一.项目概况
1 项目介绍
说明:描述该数据集分析的背景和意义
这次我使用的是人口收入调查,里面会有每个人的教育程度、每周工时、职业、性别等数据
预测个人收入
2 问题描述和解决方案
说明:描述该问题要解决的问题是什么,主要解决思路
先选择分类模型与多个特征建立模型,观察模型预测的好坏,再选择最好的预测。

首先查看数据的情况,分析一下数据,然后用回归模型拟合数据,预测房价
3 研究方法
说明:描述解决该问题要用的方法有哪些,比如变量相关性分析、线性回归模型等,可
以对方法做一个简要介绍。
首先,看一下数据的分布,和数据的相关性分析,再进行数据标准化,再使用分类建模
二.数据概况
说明:数据类型、数据描述性统计、数据量等
,可发现该数据集一共有 32 561 条样本数据,共有 15 个数据变量,其中 9 个离散型变量,
6 个数值型变量。数据项主要包括:年龄,工作类型,受教育程度,收入等,具体可见下面
两个图:

三.数据清洗与处理
一、重复值、缺失值及异常值处理
(1)重复值
说明:查看重复值的情况,以及重复值处理情况说明
没有重复值

(2)缺失值
说明:查看缺失值的情况,以及缺失值处理情况说明
在 jupyter notebook 中导入相应包,读取数据,进行预处理。在上述数据集中,有许多
变量都是离散型的,如受教育程度、婚姻状态、职业、性别等。通常数据拿到手后,都
需要对其进行清洗,例如检查数据中是否存在重复观测、缺失值、异常值等,而且,如
果建模的话,还需要对字符型的离散变量做相应的重编码。
从上面的结果可以发现,居民的收入数据集中有 3 个变量存在数值缺失,分别是居民的
工作类型(离散型)缺 1836、职业(离散型)缺 1843 和国籍(离散型)缺 583。缺失
值的存在一般都会影响分析或建模的结果,所以需要对缺失数值做相应的处理。
缺失值的处理一般采用三种方法:
1.删除法,缺失的数据较少时适用;
2.替换法,用常数替换缺失变量,离散变量用众数,数值变量用均值或中位数;
3.插补法:用未缺失的预测该缺失变量。
根据上述方法,三个缺失变量都为离散型,可用众数替换。pandas 中 fillna()方法,
能够使用指定的方法填充 NA/NaN 值。
函数形式:
fillna(value=None, method=None, axis=None, inplace=False, limit=None,
downcast=None, **kwargs)
参数:
value:用于填充的空值的值。(该处为字典)
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。
定义了填充空值的方法, pad/ffill 表示用前面行/列的值,填充当前行/列的空值,
backfill / bfill 表示用后面行/列的值,填充当前行/列的空值。
axis:轴。0 或’index’,表示按行删除;1 或’columns’,表示按列删除。
inplace:是否原地替换。布尔值,默认为 False。如果为 True,则在原 DataFrame 上
进行操作,返回值为 None。
limit:int,default None。如果 method 被指定,对于连续的空值,这段连续区域,最
多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如
果 method 未被指定, 在该 axis 下,最多填充前 limit 个空值(不论空值连续区间是
否间断)
downcast:dict, default is None,字典中的项,为类型向下转换规则。或者为字符
串“infer”,此时会在合适的等价类型之间进行向下转换,比如 float64 to int64 if
possible。
(3)异常值
说明:查看异常值的情况,以及异常值处理情况说明
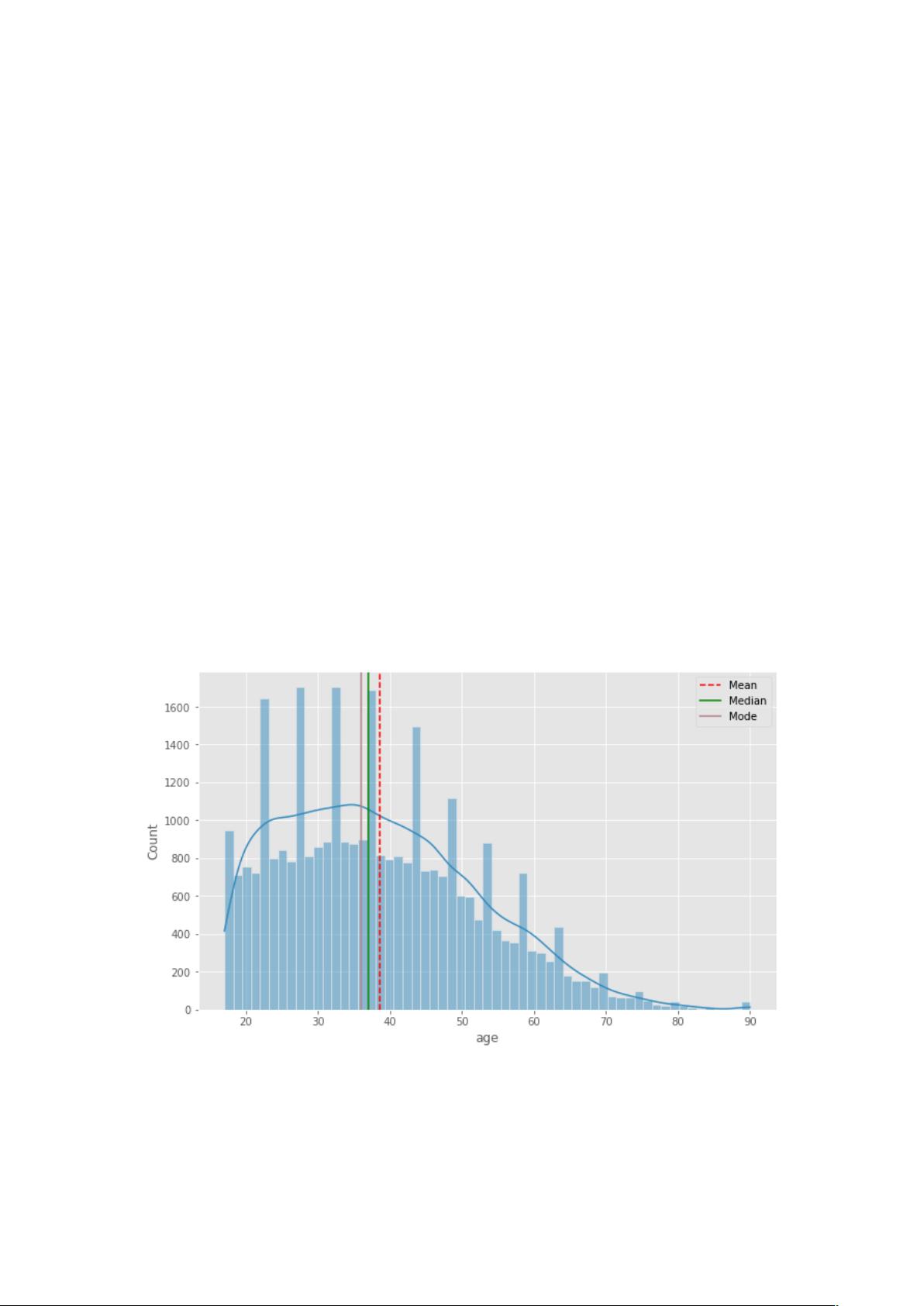
看一下每一列的数据分布情况
四.数据探索
1 变量分布
说明:单变量的频数频率分析表或者图的展示
看一下每一列的数据分布情况,发下每一列都有异常值
年龄分布:
收入分布:













