
Get PDF for Microsoft DP-203 Exam
Including Answers & Discussions
Download PDF - $49.99
- Expert Veried, Online,
Free
.
Custom View Settings
Topic 1 - Question Set 1
Topic 1
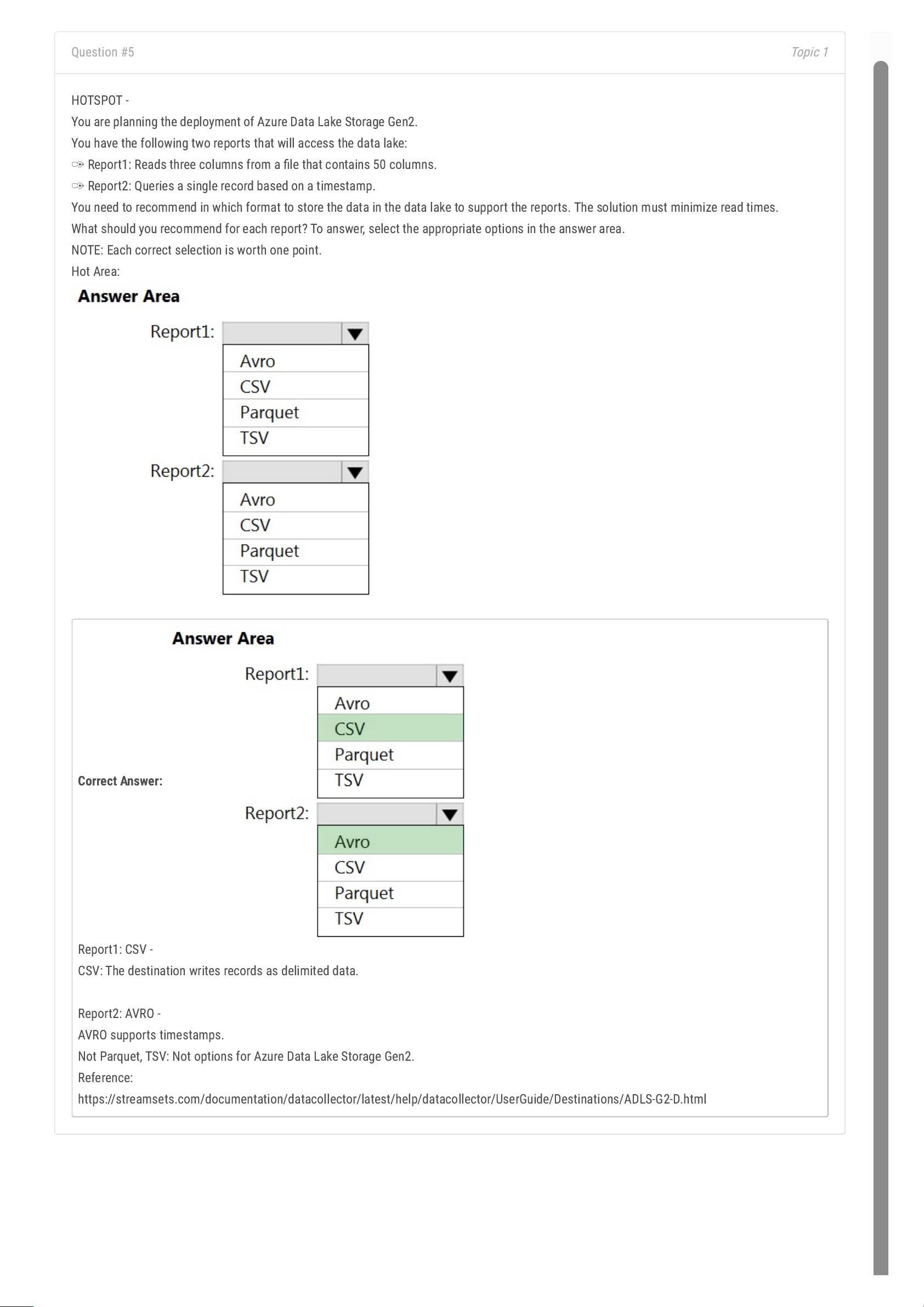
Question #1
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.
You need to alter the table to meet the following requirements:
✑
Ensure that users can identify the current manager of employees.
✑
Support creating an employee reporting hierarchy for your entire company.
✑
Provide fast lookup of the managers' attributes such as name and job title.
Which column should you add to the table?
A. [ManagerEmployeeID] [smallint] NULL
B. [ManagerEmployeeKey] [smallint] NULL
C. [ManagerEmployeeKey] [int] NULL
D. [ManagerName] [varchar](200) NULL
Correct Answer:
C
We need an extra column to identify the Manager. Use the data type as the EmployeeKey column, an int column.
Reference:
https://docs.microsoft.com/en-us/analysis-services/tabular-models/hierarchies-ssas-tabular
Community vote distribution
C (100%)



剩余365页未读,继续阅读
资源评论


xueyunshengling
- 粉丝: 578
- 资源: 3169









最新资源
- 20241226_243237026.jpeg
- f81f7b71ce9eb640ab3b0707aaf789f2.PNG
- YOLOv10目标检测基础教程:从零开始构建你的检测系统
- 学生实验:计算机编程基础教程
- 软件安装与配置基础教程:从新手到高手
- IT类课程习题解析与实践基础教程
- 湖南大学大一各种代码:实验1-9,小班,作业1-10,开放题库 注:这是21级的,有问题不要找我,少了也不要找我
- 湖南大学大一计科小学期的练习题 注,有问题别找我
- unidbg一、符号调用、地址调用
- forest-http
- christmas-圣诞树代码
- platform-绿色创新理论与实践
- christmas-圣诞树
- 数据分析-泰坦尼克号幸存者预测
- 字符串-圣诞树c语言编程代码
- learning_coder-二叉树的深度
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


