def _ensure_initialized(cls, instance=None, gateway=None,
conf=None):""" Checks whether a SparkContext is initialized
or not. Throws error if a SparkContext is already running.
"""with SparkContext._lock:if not SparkContext._gateway:
SparkContext._gateway = gateway or launch_gateway(conf)
SparkContext._jvm = SparkContext._gateway.jvm
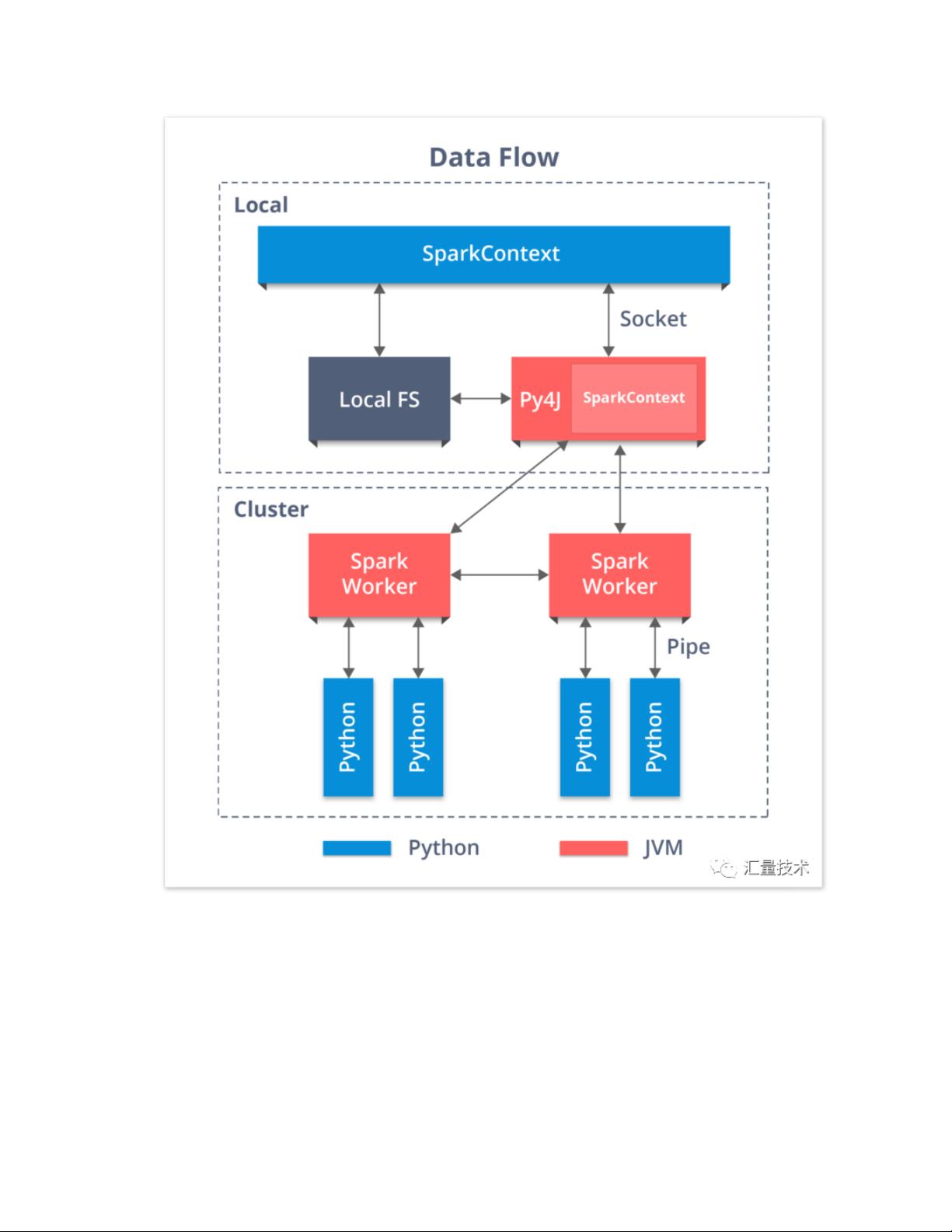
在 launch_gateway (python/pyspark/java_gateway.py)中,首先启动 JVM 进程
:
SPARK_HOME = _find_spark_home()# Launch the Py4j gateway using
Spark's run command so that we pick up the# proper classpath and
settings from spark-env.shon_windows = platform.system() ==
"Windows"script = "./bin/spark-submit.cmd" if on_windows else
"./bin/spark-submit"command = [os.path.join(SPARK_HOME, script)]
然后创建 JavaGateway 并 import 一些关键的 class:
gateway = JavaGateway(
gateway_parameters=GatewayParameters(port=gateway_port,
auth_token=gateway_secret,
auto_convert=True))# Import the classes used by
PySparkjava_import(gateway.jvm,
"org.apache.spark.SparkConf")java_import(gateway.jvm,
"org.apache.spark.api.java.*")java_import(gateway.jvm,
"org.apache.spark.api.python.*")java_import(gateway.jvm,
"org.apache.spark.ml.python.*")java_import(gateway.jvm,
"org.apache.spark.mllib.api.python.*")# TODO(davies): move into
sqljava_import(gateway.jvm,
"org.apache.spark.sql.*")java_import(gateway.jvm,
"org.apache.spark.sql.api.python.*")java_import(gateway.jvm,
"org.apache.spark.sql.hive.*")java_import(gateway.jvm,
"scala.Tuple2")
拿到 JavaGateway 对象,即可以通过它的 jvm 属性,去调用 Java 的类了,例
如: