大数据处理技术是现代信息技术领域的重要组成部分,特别是在互联网和企业信息化日益发展的今天,处理海量数据的能力已经成为企业竞争力的关键因素。本文将深入探讨其中一种备受推崇的大数据处理利器——Hadoop,以及大数据处理的基本特点。
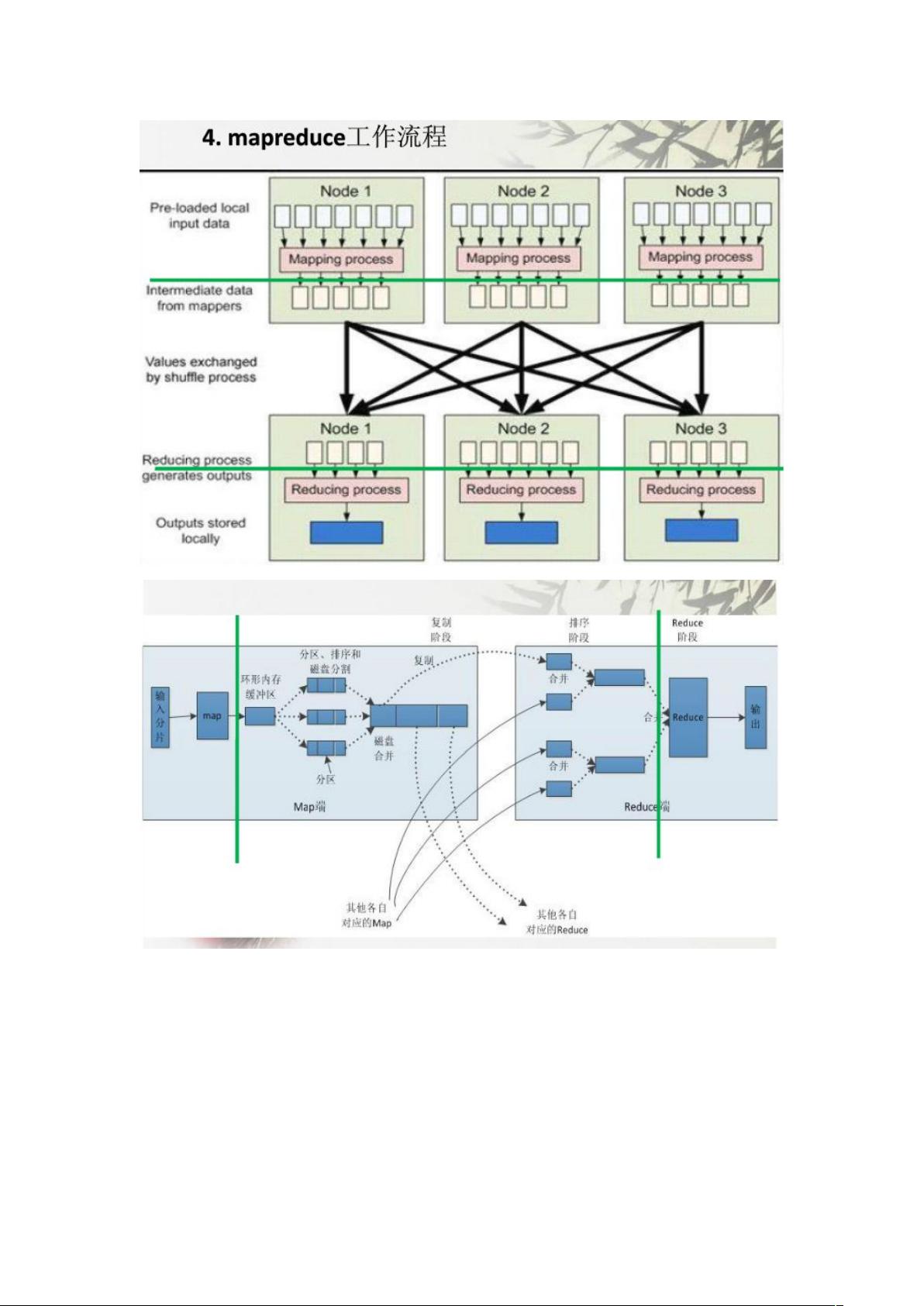
Hadoop 是一个开源项目,由Apache软件基金会维护,它主要解决了大数据的存储和处理问题。Hadoop 的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。HDFS是分布式文件系统,用于存储大规模的数据集;MapReduce则是一种编程模型,用于处理和生成大数据集。
**高可扩展性**是Hadoop的一大亮点。它能够通过横向扩展,即增加廉价的服务器节点,构建大规模的数据集群,实现数据的分布式存储和处理。这种可扩展性使得企业可以应对不断增长的数据量,而无需担心系统的性能瓶颈。
**成本效益**是Hadoop的另一个显著优点。传统的RDBMS(关系型数据库管理系统)在处理大量数据时可能会面临高昂的成本,而Hadoop通过向外扩展的架构,允许企业以较低的成本存储和处理PB级别的数据。这使得企业能够保留更多的历史数据,用于未来分析和挖掘,从而实现更大的商业价值。
**灵活性**是Hadoop的另一大特征。它能适应各种数据类型,无论是结构化、半结构化还是非结构化数据,都可以进行有效的分析。Hadoop可以应用于社交媒体分析、电子邮件挖掘、点击流分析等多个领域,帮助企业发现新的商业机会。
**快速处理**能力也是Hadoop的核心优势之一。通过将数据处理工具与数据存储在同一服务器上,Hadoop实现了快速的数据处理。对于非结构化数据的处理,Hadoop可以在几分钟内完成TB级别的数据处理,远超传统系统的效率。
**容错能力**是Hadoop保证系统稳定性的关键。数据在存储时会被复制到多个节点,当某个节点出现故障,其他节点的副本可以无缝接管,确保数据的完整性和服务的连续性。
大数据处理的特点包括**数据量大(Volume)**,指的是处理的数据规模达到PB级别甚至更高;**数据种类多样(Variety)**,涵盖了结构化、半结构化和非结构化数据;还有**速度(Velocity)**,即数据的生成和处理速度极快;**价值密度低(Value)**,大量的数据中蕴含着少量的有价值信息;以及**真实性(Veracity)**,数据的质量和准确性至关重要。
Hadoop作为大数据处理的关键技术,凭借其高可扩展性、成本效益、灵活性、快速处理和容错能力,成为了企业和组织应对大数据挑战的理想选择。随着大数据应用场景的不断扩展,掌握Hadoop及相关技术将成为IT专业人士必备的技能之一。同时,理解大数据处理的特性,可以帮助企业更好地利用数据资源,提升业务效率和创新能力。