




资源评论


xiaoj08
- 粉丝: 1
- 资源: 7









最新资源
- 基于java+springboot+vue+mysql的医院质控上报系统 源码+数据库+论文(高分毕业设计).zip
- 基于java+springboot+vue+mysql的悠扬乐器管理系统 源码+数据库+论文(高分毕业设计).zip
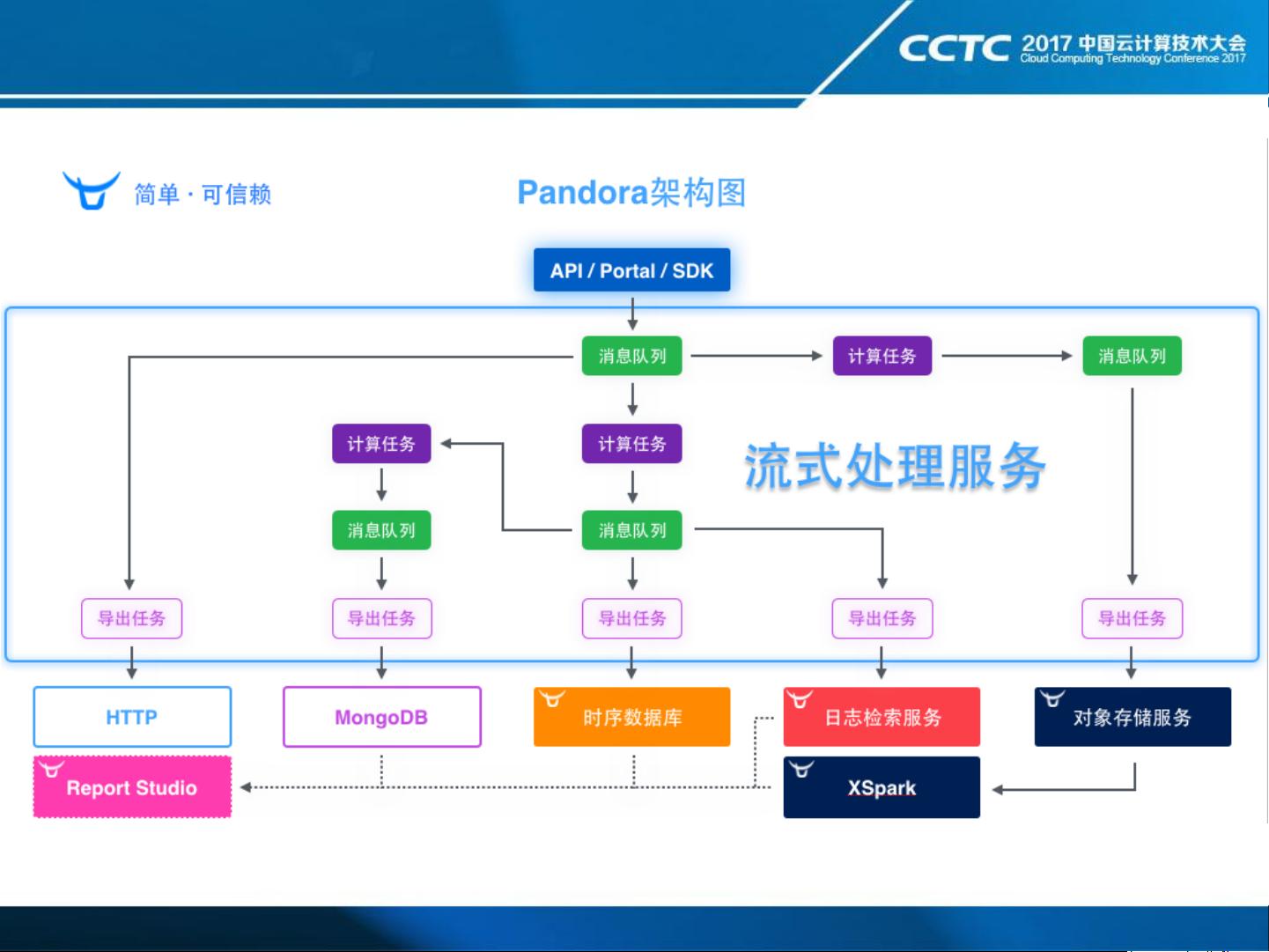
- 无标题WiFi Sensing with Channel State Information: A Survey-2
- 球罐预冷过程热力学计算
- 基于java+springboot+vue+mysql的预定点餐系统 源码+数据库+论文(高分毕业设计).zip
- 基于java+springboot+vue+mysql的郑州旅游景点智能推荐系统 源码+数据库+论文(高分毕业设计).zip
- matlab的KNN实现手写数字识别项目源码+实验报告+演示PPT(高分大作业)
- 毕业设计基于单片机的室内有害气体检测报警系统设计源代码+论文
- Android ,Java,KML文件详细解析,并显示出来 本文将详细解析KML文件,获取里面的数据并显示出来
- Python Flask API对接Docker容器执行脚本与错误处理(后端与前端通信)
- 基于Java的报表模块,支持自定义SQL和报表模板 -2025
- 将数据插入数据库(格式)
- 基于java+springboot+vue+mysql的智慧养老服务系统 源码+数据库+论文(高分毕业设计).zip
- 基于准PR控制的LCL三相并网逆变器仿真模型(带报告) 参考资料:附带自己写的一份报告,与仿真一一对应 ①包含详细LCL滤波器参数设计过程 ②仿真整体控制结构的设计 ③准PR控制器控制框图及传递函数等
- 基于java+springboot+vue+mysql的智慧农业专家远程指导系统 源码+数据库+论文(高分毕业设计).zip
- 浏览器插件-手机归属地查询
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


