

一、自我介绍(目前不知道怎么做)
您好,我叫 xxx,毕业于 xxx 学校,因为在大学里学过 javase、mysql、web、
数据结构与算法等计算机基础知识,在一份软件测试的实习中接触到数据仓库、
用户画像、推荐系统等这些概念,让我对大数据非常感兴趣,经过各种了解之后,
觉得大数据非常有发展潜力,因此确定要进入发展。
我比较喜欢大数据这个行业,很看好大数据未来的发展潜力,就学习了相关
的技术,像 hadoop,hive,flume,kafka,spark,hbase ,还有当下流行的 flink,
刚进到公司的时候,自己的经验并没有多么的丰富,也是在不断的学习研究之后,
才对大数据有了一个更深的了解。
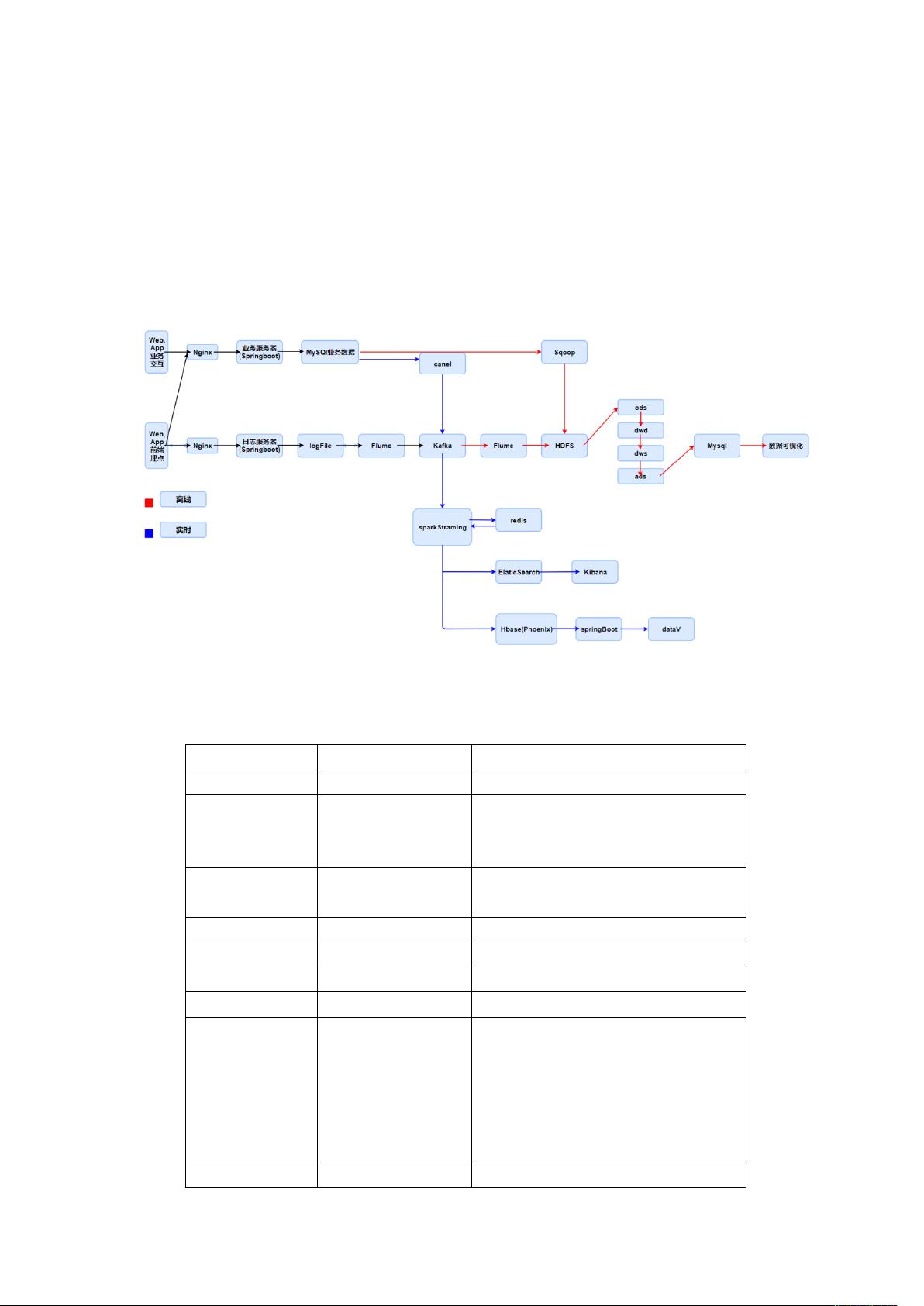
在上一份工作中,我参与并完成的一个项目是一个电商数仓项目,我们这个
项主要包含三部分内容:
(1)数据平台搭建;
(2)数据仓库搭建及离线计算系统;
(3)实时计算系统;
二、从服务器购买开始规划大数据(目标 10 台)
1.确定主机的规模
1.1 物理机 vs 云主机
公司选型:阿里云主机
12 台物理机:128G 内存,8T 机械硬盘,2T 固态硬盘,20 核 40 线程,惠普 4
万多一台。
对比云服务器,同样的配置,阿里云 5W/年。
物理机需要有专门的运维人员,云主机由阿里云完成。
我们公司综合各种情况之后使用的是云主机。


剩余34页未读,继续阅读
资源评论



AIMaynor
- 粉丝: 7w+
- 资源: 173

下载权益

C知道特权

VIP文章

课程特权
开通VIP











