Unicode、GB2312、GBK 和 GB18030 中的汉字
2009-06-14 11:57
GB18030 有两个版本:GB18030-2000 和 GB18030-2005。GB18030-2000 是 GBK 的取代版本,它的主要特点是
在 GBK 基础上增加了 CJK 统一汉字扩充 A 的汉字。GB18030-2005 的主要特点是在 GB18030-2000 基础上增加了
统一汉字扩充 B 的汉字。本 文数一数 GB18030 中的汉字,也顺便看看其它标准中的汉字。
1 Unicode 中的汉字
在 Unicode 5.0 的 99089 个字符中,有 71226 个字符与汉字有关。它们的分布如下:
Block 名称 开始码位 结束码位 字符数
CJK 统一汉字
4E00 9FBB 20924
CJK 统一汉字扩充 A
3400 4DB5 6582
CJK 统一汉字扩充 B
20000 2A6D6 42711
CJK 兼容汉字
F900 FA2D 302
CJK 兼容汉字
FA30 FA6A 59
CJK 兼容汉字
FA70 FAD9 106
CJK 兼容汉字补充
2F800 2FA1D 542
如果不算兼容汉字,Unicode 目前支持的汉字总数是 20924+6582+42711=70217。
这里有一个细节。在早期的 Unicode 版本中,CJK 统一汉字区的范围是 0x4E00-0x9FA5,也就是我们经常提到的
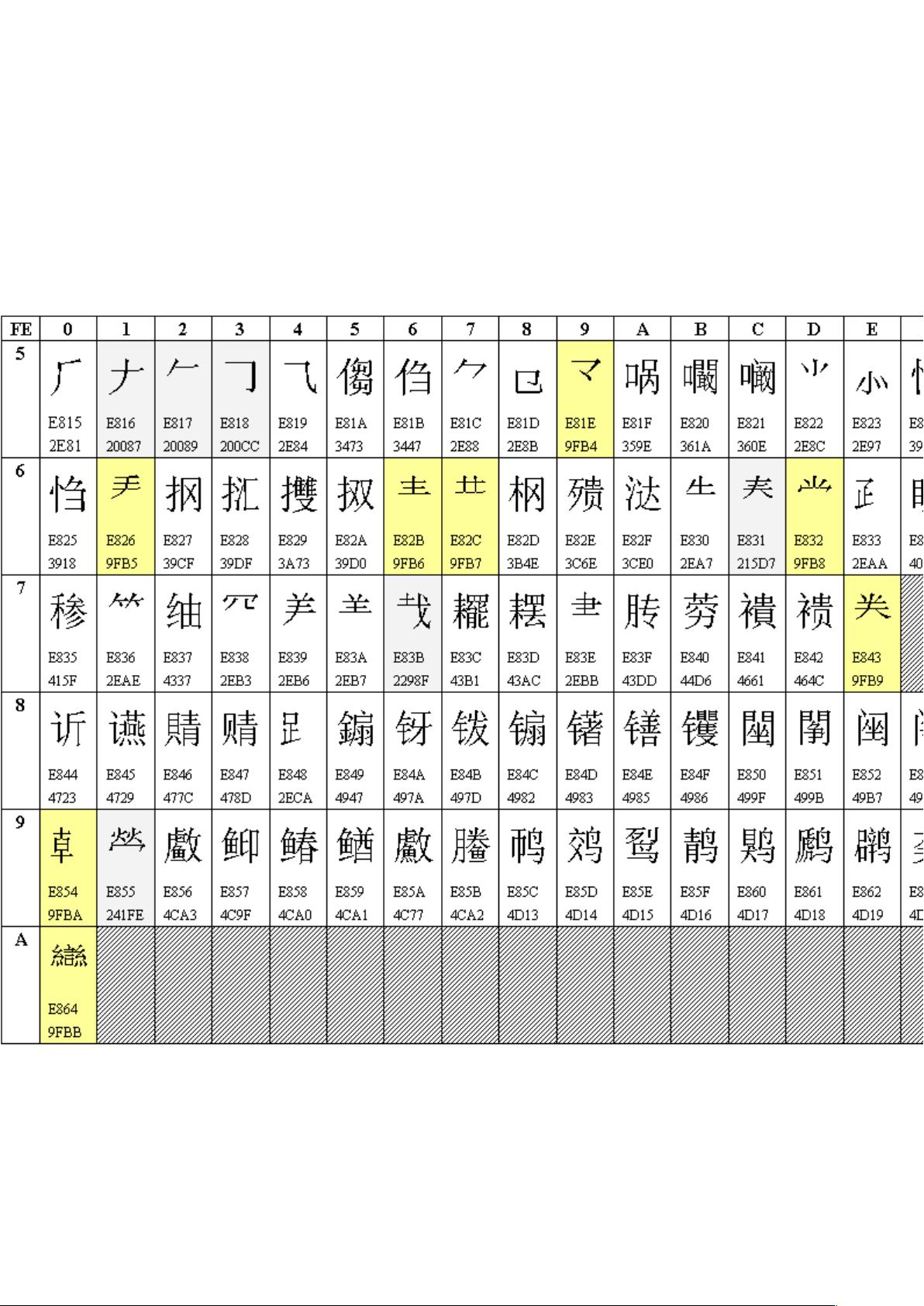
20902 个汉字。当前版本的 Unicode 增加了 22 个字符,码位是 0x9FA6-0x9FBB。它们是:
那么 GB18030 是否支持这 22 个字符?后面还会讨论。
2 GB2312
1980 年的 GB2312 一共收录了 7445 个字符,包括 6763 个汉字和 682 个其它符号。汉字区的内码范围高字节从
F7,低字节从 A1-FE,占用的码位是 72*94=6768。其中有 5 个空位是 D7FA-D7FE。
这 6763 个汉字在 Unicode 中不是连续的,分布在 CJK 统一汉字字符区(0x4E00-0x9FA5)的 20902 个汉字中。
3 GBK