

US Naval Research Laboratory Technical Report 5510-026
A DISCIPLINED APPROACH TO NEURAL NETWORK
HYPER-PARAMETERS: PART 1 – LEARNING RATE,
BATCH SIZE, MOMENTUM, AND WEIGHT DECAY
Leslie N. Smith
US Naval Research Laboratory
Washington, DC, USA
leslie.smith@nrl.navy.mil
ABSTRACT
Although deep learning has produced dazzling successes for applications of im-
age, speech, and video processing in the past few years, most trainings are with
suboptimal hyper-parameters, requiring unnecessarily long training times. Setting
the hyper-parameters remains a black art that requires years of experience to ac-
quire. This report proposes several efficient ways to set the hyper-parameters that
significantly reduce training time and improves performance. Specifically, this
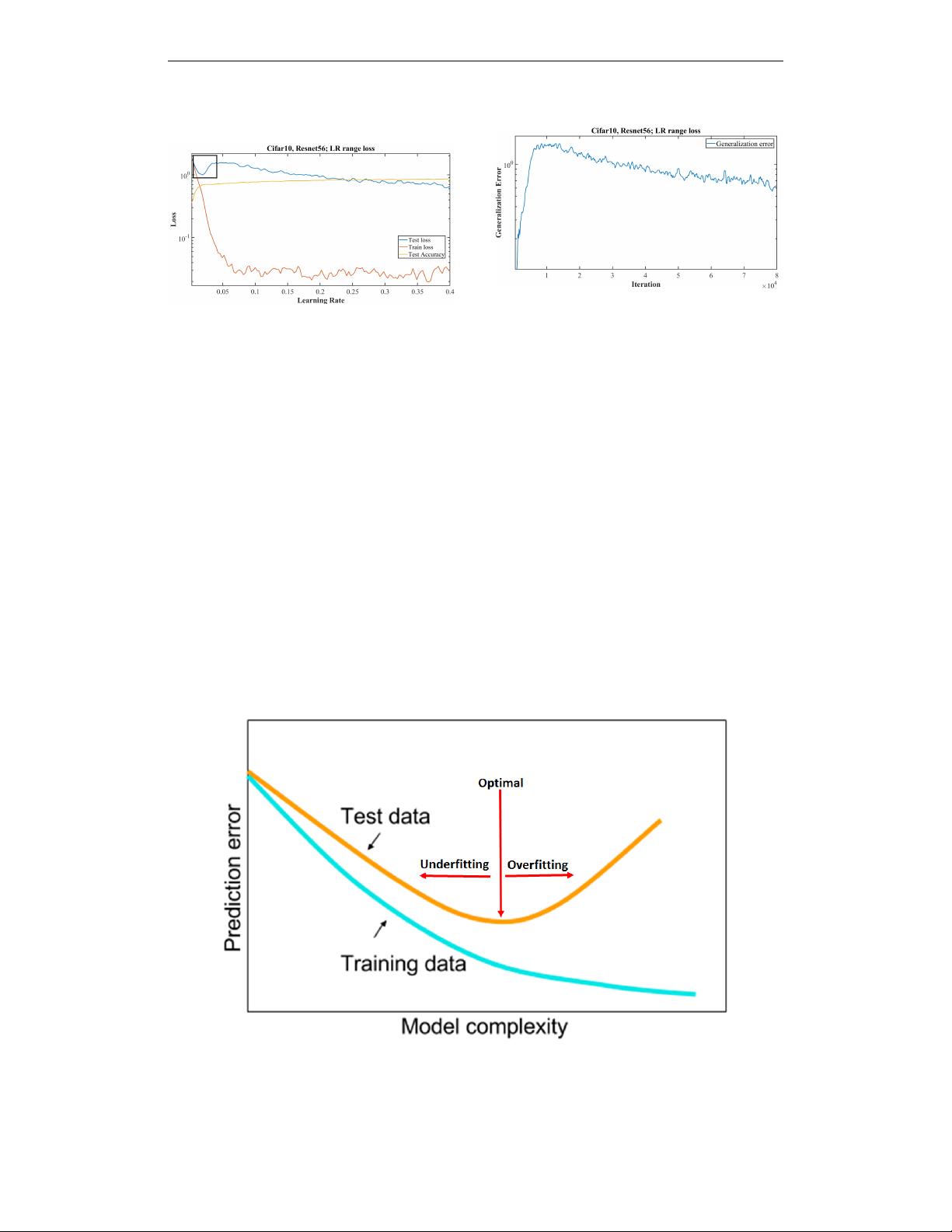
report shows how to examine the training validation/test loss function for subtle
clues of underfitting and overfitting and suggests guidelines for moving toward
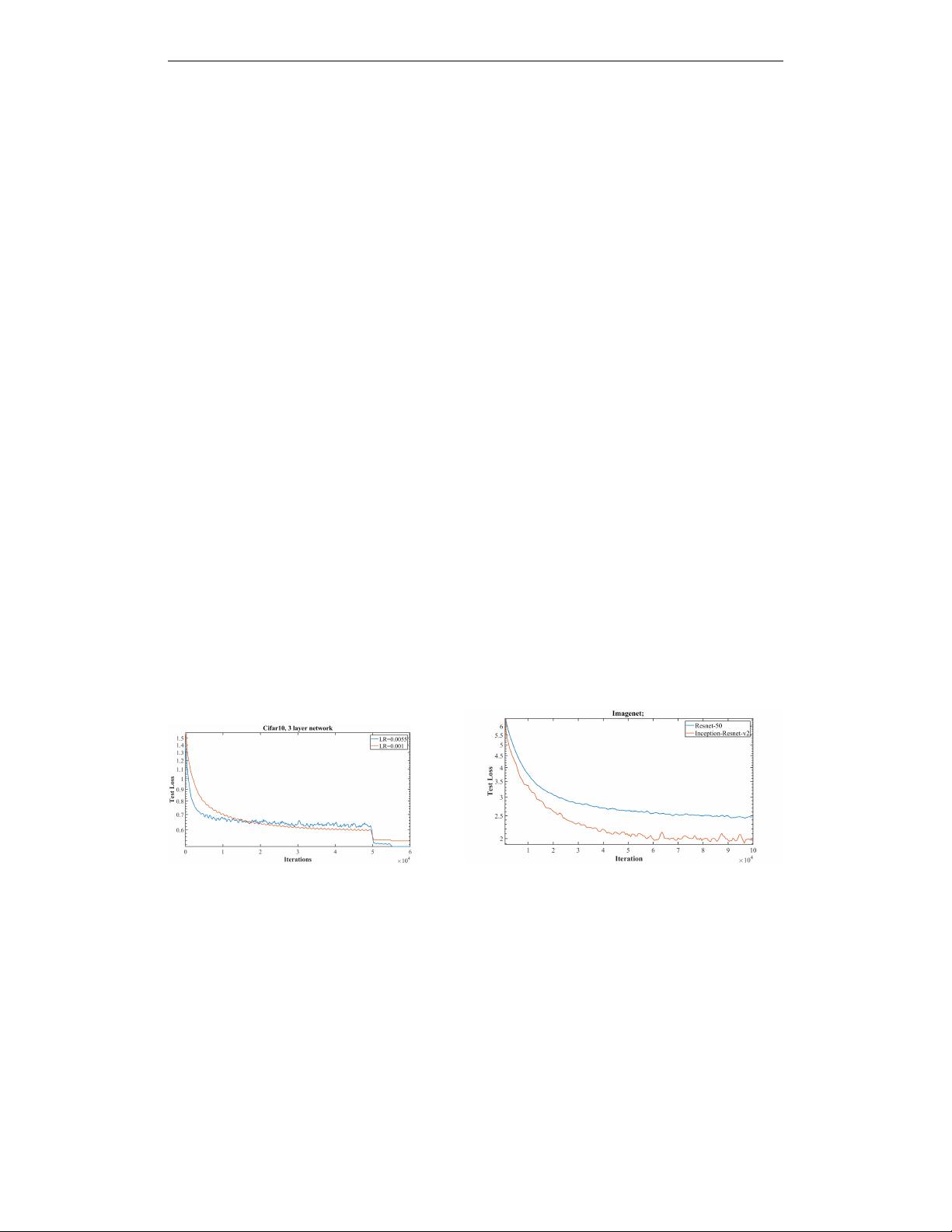
the optimal balance point. Then it discusses how to increase/decrease the learning
rate/momentum to speed up training. Our experiments show that it is crucial to
balance every manner of regularization for each dataset and architecture. Weight
decay is used as a sample regularizer to show how its optimal value is tightly
coupled with the learning rates and momentum. Files to help replicate the results
reported here are available at https://github.com/lnsmith54/hyperParam1.
1 INTRODUCTION
The rise of deep learning (DL) has the potential to transform our future as a human race even more
than it already has and perhaps more than any other technology. Deep learning has already created
significant improvements in computer vision, speech recognition, and natural language processing,
which has led to deep learning based commercial products being ubiquitous in our society and in
our lives.
In spite of this success, the application of deep neural networks remains a black art, often requiring
years of experience to effectively choose optimal hyper-parameters, regularization, and network
architecture, which are all tightly coupled. Currently the process of setting the hyper-parameters,
including designing the network architecture, requires expertise and extensive trial and error and is
based more on serendipity than science. On the other hand, there is a recognized need to make the
application of deep learning as easy as possible.
Currently there are no simple and easy ways to set hyper-parameters – specifically, learning rate,
batch size, momentum, and weight decay. A grid search or random search (Bergstra & Bengio,
2012) of the hyper-parameter space is computationally expensive and time consuming. Yet train-
ing time and final performance is highly dependent on good choices. In addition, practitioners
often choose one of the standard architectures (such as residual networks (He et al., 2016)) and the
hyper-parameter files that are freely available in a deep learning framework’s “model zoo” or from
github.com but these are often sub-optimal for the practitioner’s data.
This report proposes several methodologies for finding optimal settings for several hyper-
parameters. A comprehensive approach of all hyper-parameters is valuable due to the interdepen-
dence of all of these factors. Part 1 of this report examines learning rate, batch size, momentum, and
weight decay and Part 2 will examine the architecture, regularization, dataset and task. The goal is to
provide the practitioner with practical advice that saves time and effort, yet improves performance.
1
arXiv:1803.09820v2 [cs.LG] 24 Apr 2018

剩余20页未读,继续阅读
资源评论


大饼博士X
- 粉丝: 4091
- 资源: 9









最新资源
- VID_20250103_144816_970.mp4
- VID_20250103_141709_050.mp4
- -9214195356454737604_235797052
- szg_1682_50001_0b53s4aaaaaaj4aicy3kz5tvdf6daclqaaca.f633.mp4
- 感应电机转子磁场定向FOC仿真,异步电机调速控制仿真 电机参数是山河智能SWFE15型起重量1.5吨电动叉车使用的实际电机 采用转速电流双闭环,防饱和PI调节器,SVPWM发波,通过iq电流查表实
- szg_4578_50001_0b537qabeaaalmaebx3lentvd7gdcl6aaesa.f206513.mp4
- 机械设计双层自动上料倍数链输送机sw18可编辑非常好的设计图纸100%好用.zip
- szg_9837_50001_0b536mabmaaaoaakua3tlztvd46dc3zqafsa.f104101.mp4
- ZeroBasedOne-EXE
- IMG_20250103_145430_206.jpg
- IMG_20250103_145750_179.jpg
- IMG_20250103_145807_306.jpg
- 加速度测量系统.pdf
- 电机控制器,IGBT结温估算(算法+模型)国际大厂机密算法,多年实际应用,准确度良好 能够同时对IGBT内部6个三极管和6个二极管温度进行估计,并输出其中最热的管子对应温度 可用于温度保护,降额,提
- Simplorer与Maxwell电机联合仿真,包含搭建好的Simplorer电机场路耦合主电路与控制算法(矢量控制SVPWM),包含电路与算法搭建的详细教程视频 电机模型可替
- 大学学生信息管理系统,个人学习整理,仅供参考
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


