
Hadoop 1.XX 安装部署
一、 介绍
简介
软件库是一个框架,允许在集群服务器上使
用简单的编程模型对大数据集进行分布式处理。 被设计成
能够从单台服务器扩展到数以千计的服务器,每台服务器都有本地
的计算和存储资源。 的高可用性并不依赖硬件,其代码库
自身就能在应用层侦测并处理硬件故障,因此能基于服务器集群提
供高可用性的服务。
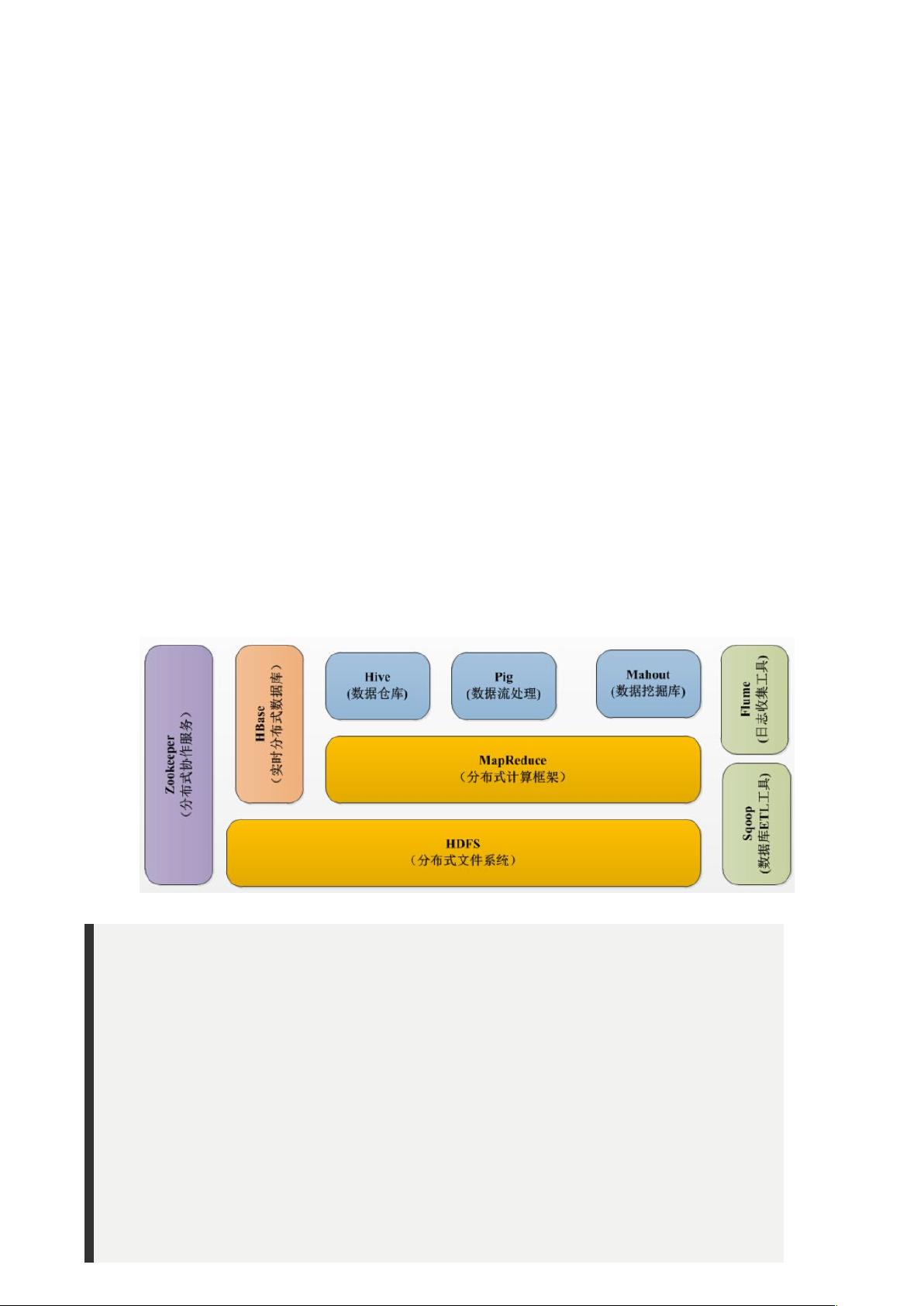
生态系统
经过多年的发展形成了 生态系统,其结构如下图所示:
生态圈的基本组成部分是 分布式文件系统()。
是一种数据分布式保存机制,数据被保存在计算机集群上, 为 等工具提
供了基础。
的主要执行框架是 ,它是一个分布式、并行处理
的编程模型, 把任务分为 映射阶段和 化简。由于
工作原理的特性, 能以并行的方式访问数据,从而实现快速访问
数据。
是一个建立在 之上,面向列的 数据库,用于快速读 写大
量数据。 使用 !" 进行管理,确保所有组件都正常运行。
!"用于 的分布式协调服务。 的许多组件依赖于
!",它运行在计算机集群上面,用于管理 操作。
#$%它是 编程的复杂性的抽象。#$% 平台包括运行环境和用于分析
数据集的脚本语言#$%&$'。其编译器将 #$%&$' 翻译成 程
序序列。

剩余15页未读,继续阅读
资源评论













