Linux代码分析 本文详细分析了 2.6.x 内核中链表结构的实现,并通过实例对每个链表操作接口进行了详尽的讲解。
需积分: 3 6 浏览量
2010-01-08
17:37:32
上传
评论
收藏 91KB DOC 举报

本文详细分析了 内核中链表结构的实现,并通过实例对每个链表操作接口进行了详尽的讲解。
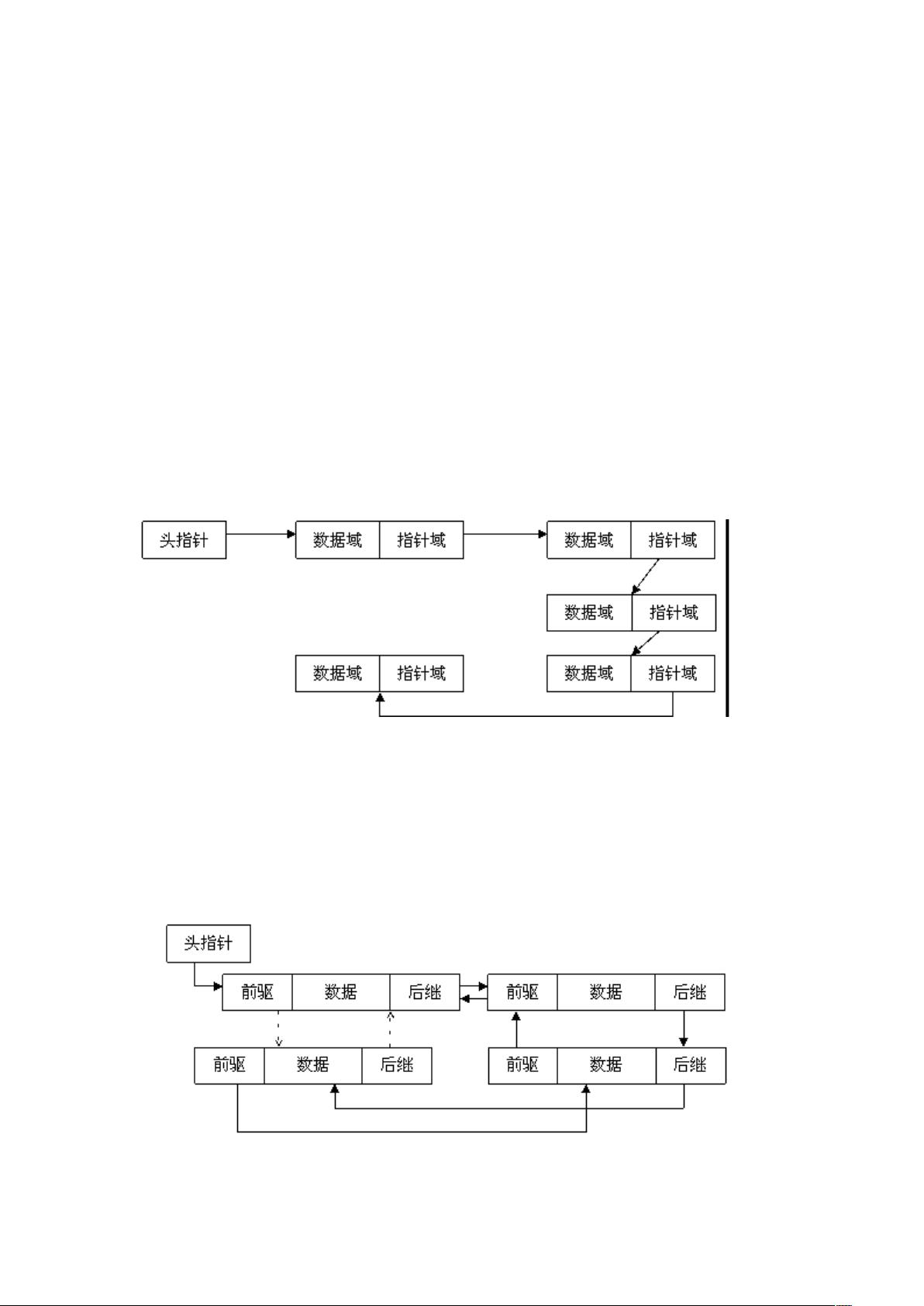
一、 链表数据结构简介
链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连接成一条数据链,是线性表
的一种重要实现方式。相对于数组,链表具有更好的动态性,建立链表时无需预先知道数据总量,可以随
机分配空间,可以高效地在链表中的任意位置实时插入或删除数据。链表的开销主要是访问的顺序性和组
织链的空间损失。
通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建立与下一个
节点的联系。按照指针域的组织以及各个节点之间的联系形式,链表又可以分为单链表、双链表、循环链
表等多种类型,下面分别给出这几类常见链表类型的示意图:
1. 单链表
图 1 单链表
单链表是最简单的一类链表,它的特点是仅有一个指针域指向后继节点(),因此,对单链表的遍
历只能从头至尾(通常是 空指针)顺序进行。
2. 双链表
图 2 双链表

剩余10页未读,继续阅读
资源评论













