
1 Apriori 介绍
Apriori 算法使用频繁项集的先验知识,使用一种称作逐层搜索的迭代方法, k 项集用
于探索 (k+1) 项集。首先,通过扫描事务(交易)记录,找出所有的频繁 1 项集,该集合记
做 L
1,然后利用 L1 找频繁 2 项集的集合 L2 ,L2 找 L3,如此下去, 直到不能再找到任何频繁
k 项集。最后再在所有的频繁集中找出强规则,即产生用户感兴趣的关联规则。
其中,Apriori 算法具有这样一条 性质 :任一频繁项集的所有非空子集也必须是频繁的。
因为假如 P(I)< 最小支持度阈值,当有元素 A 添加到 I 中时,结果项集( A∩ I)不可能比 I
出现次数更多。因此 A ∩I 也不是频繁的。
2 连接步和剪枝步
在上述的关联规则挖掘过程的两个步骤中,第一步往往是总体性能的瓶颈。 Apriori 算
法采用连接步和剪枝步两种方式来找出所有的频繁项集。
1) 连接步
为找出 L
k
(所有的频繁 k 项集的集合),通过将 L
k-1
(所有的频繁 k-1 项集的集合)与
自身连接产生候选 k 项集的集合。候选集合记作 C
k
。设 l
1
和 l
2
是 L
k-1
中的成员。记 l
i
[j] 表示
li 中的第 j 项。假设 Apriori 算法对事务或项集中的项按字典次序排序,即对于( k-1)项集
l
i
,l
i
[1]<l
i
[2]< ……… .<l
i
[k-1] 。将 L
k-1
与自身连接, 如果 (l
1
[1]=l
2
[1])&&( l
1
[2]=l
2
[2])&& …… ..&&
(l
1
[k-2]=l
2
[k-2])&&(l
1
[k-1]<l
2
[k-1]) ,那认为 l
1
和 l
2
是可连接。连接 l
1
和 l
2
产生的结果是
{l 1[1],l 1[2], …… ,l1[k-1],l 2[k-1]} 。
2) 剪枝步
C
K
是 L
K
的超集,也就是说, C
K
的成员可能是也可能不是频繁的。通过扫描所有的事
务(交易),确定 C
K 中每个候选的计数,判断是否小于最小支持度计数,如果不是,则认
为该候选是频繁的。 为了压缩 C
k,可以利用 Apriori 性质:任一频繁项集的所有非空子集也必
须是频繁的,反之, 如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从
而可以将其从 C
K
中删除。
(Tip:为什么要压缩 C
K
呢?因为实际情况下事务记录往往是保存在外存储上, 比如数
据库或者其他格式的文件上, 在每次计算候选计数时都需要将候选与所有事务进行比对, 众
所周知,访问外存的效率往往都比较低,因此 Apriori 加入了所谓的剪枝步,事先对候选集
进行过滤,以减少访问外存的次数。)
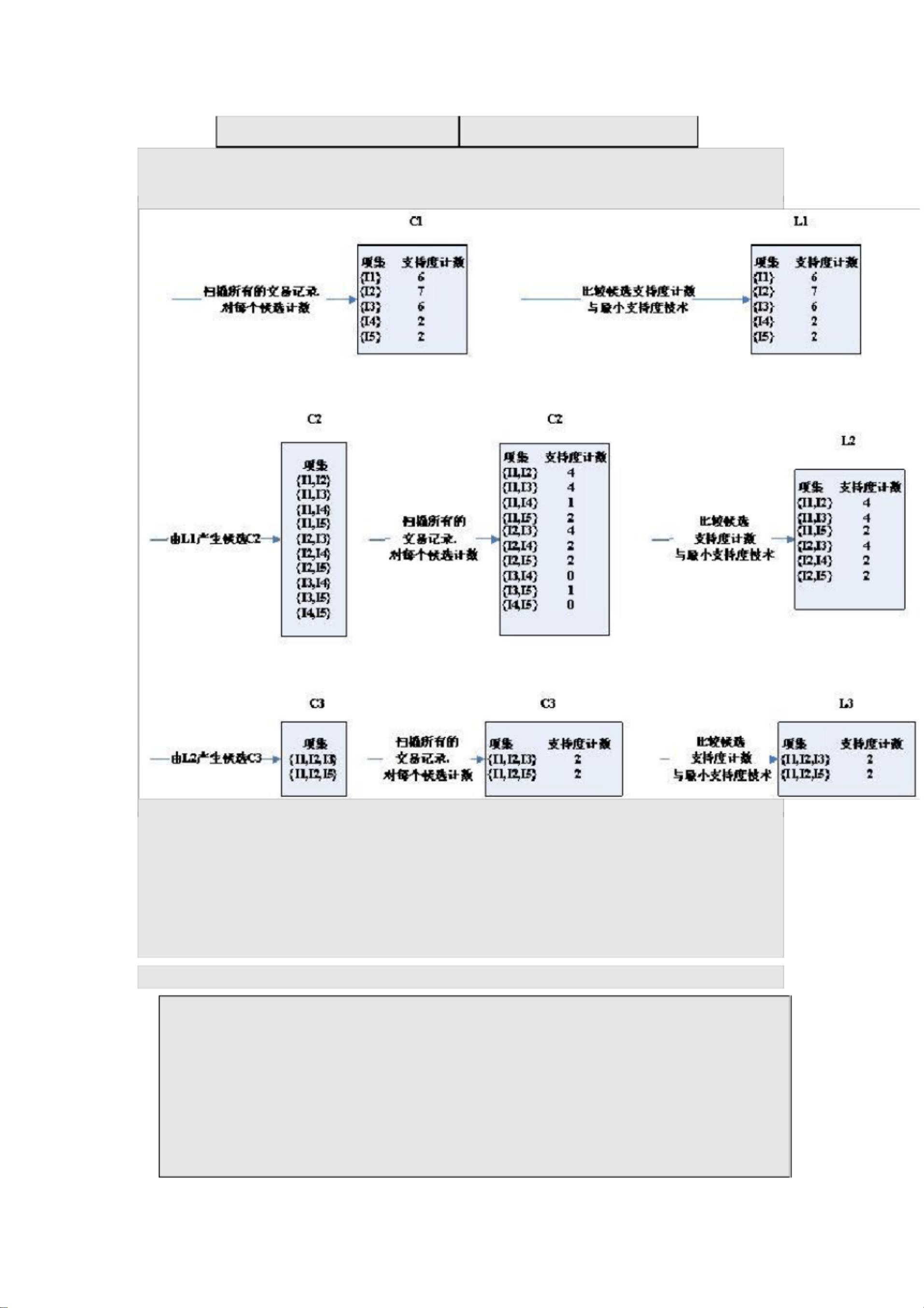
3 Apriori 算法实例
交易 ID 商品 ID 列表
T100 I1,I2,I5
T200 I2,I4
T300
I2,I3
T400 I1,I2,I4
T500
I1,I3
T600 I2,I3
T700
I1,I3
T800 I1,I2,I3,I5

剩余10页未读,继续阅读

wxj15659998286
- 粉丝: 1
- 资源: 10万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0
最新资源