

Where we are ?
22/5/11
1
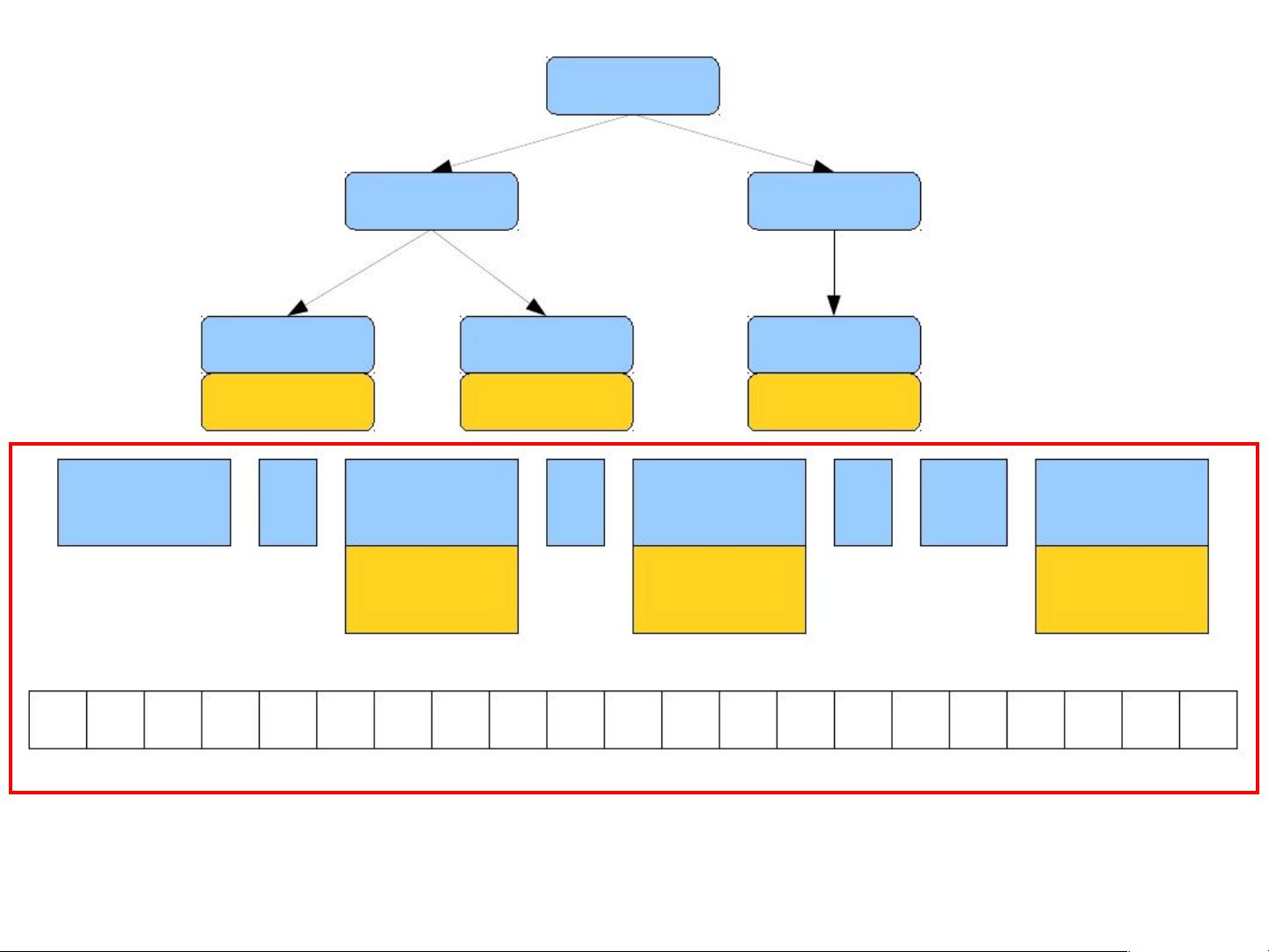
Lexical Analysis
Syntax Analysis
Semantic Analysis
IR Generation
IR Optimization
Code Generation
Optimization
Source
Code
Machine
Code

剩余63页未读,继续阅读
资源评论


wxg520cxl
- 粉丝: 25
- 资源: 3万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- (源码)基于Spring Boot和Vue的高性能售票系统.zip
- (源码)基于Windows API的USB设备通信系统.zip
- (源码)基于Spring Boot框架的进销存管理系统.zip
- (源码)基于Java和JavaFX的学生管理系统.zip
- (源码)基于C语言和Easyx库的内存分配模拟系统.zip
- (源码)基于WPF和EdgeTTS的桌宠插件系统.zip
- (源码)基于PonyText的文本排版与预处理系统.zip
- joi_240913_8.8.0_73327_share-2EM46K.apk
- Library-rl78g15-fpb-1.2.1.zip
- llvm-17.0.1.202406-rl78-elf.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


