目 录
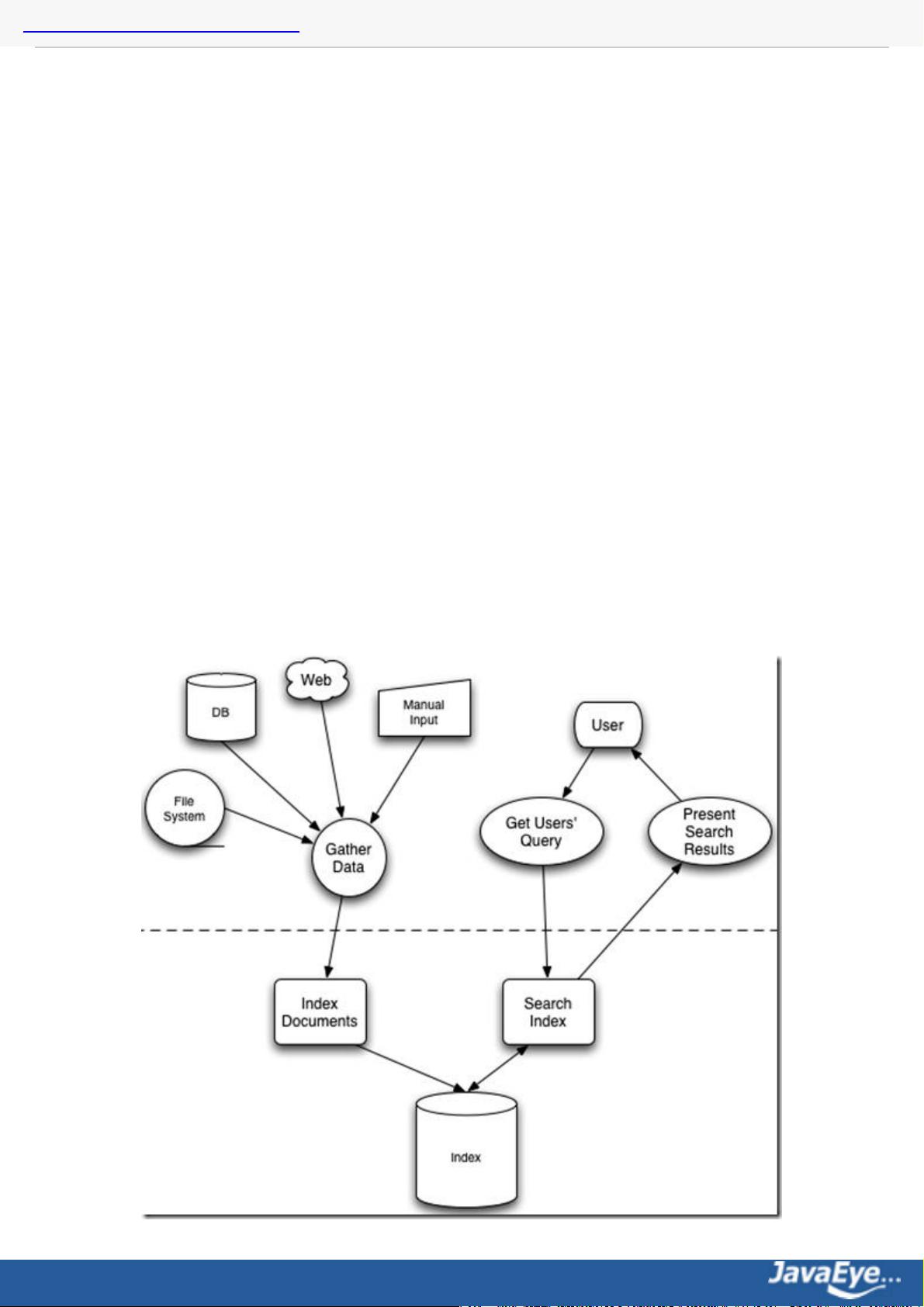
1. Lucene 学习总结
1.1 Lucene学习总结之一:全文检索的基本原理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Lucene学习总结之二:Lucene的总体架构 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .22
1.3 Lucene学习总结之三:Lucene的索引文件格式 (1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
1.4 Lucene学习总结之三:Lucene的索引文件格式 (2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .34
1.5 Lucene学习总结之三:Lucene的索引文件格式 (3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .60
1.6 Lucene学习总结之四:Lucene索引过程分析(1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .71
1.7 Lucene学习总结之四:Lucene索引过程分析(2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .90
1.8 Lucene学习总结之四:Lucene索引过程分析(3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .116
1.9 Lucene学习总结之四:Lucene索引过程分析(4) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
1.10 Lucene学习总结之五:Lucene段合并(merge)过程分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .160
1.11 Lucene学习总结之六:Lucene打分公式的数学推导 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .200
1.12 Lucene学习总结之七:Lucene搜索过程解析(1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .206
1.13 Lucene学习总结之七:Lucene搜索过程解析(2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .208
1.14 Lucene学习总结之七:Lucene搜索过程解析(3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .223
1.15 Lucene学习总结之七:Lucene搜索过程解析(4) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .246
1.16 Lucene学习总结之七:Lucene搜索过程解析(5) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .255
1.17 Lucene学习总结之七:Lucene搜索过程解析(6) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .275
1.18 Lucene学习总结之七:Lucene搜索过程解析(7) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .286
1.19 Lucene学习总结之七:Lucene搜索过程解析(8) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .306
http://forfuture1978.javaeye.com
第 2 / 550 页