




资源评论


wuscar0703
- 粉丝: 1
- 资源: 25









最新资源
- 磁共振测试机工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- pyqt编写界面,打开笔记本摄像头,支持缩放拖拽,并标记位置
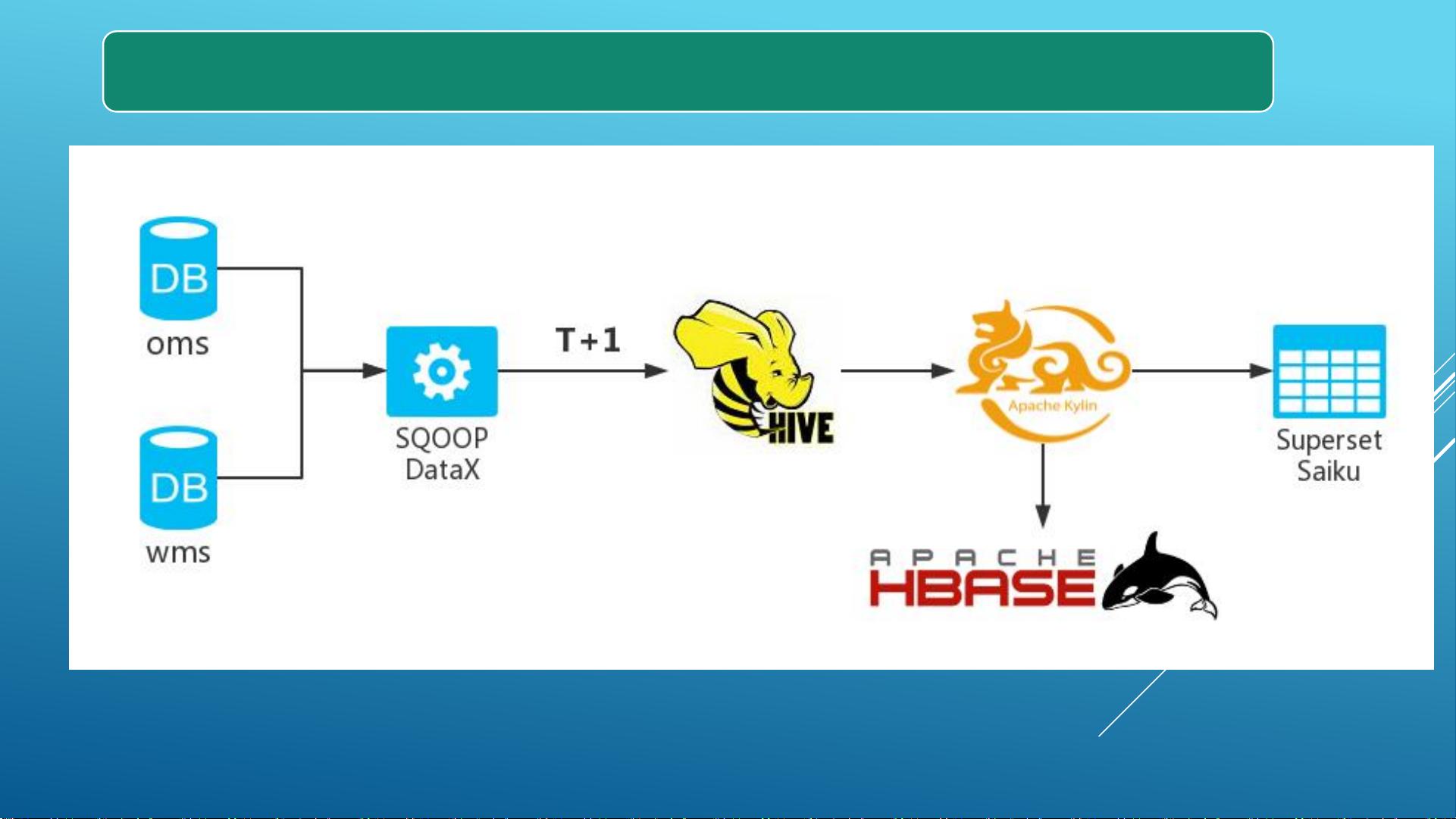
- UI页面布局分析(5)- 评分弹窗的实现
- CentOS7与欧拉系统中达梦8数据库安装手册
- 1、C++SOCKET同步阻塞、异步非阻塞通信服务端、客户端代码,支持多个客户端连接 2、断线重连(服务端或客户端没有启动顺序要求,先开启的等待另一端连接); 3、服务端支持同时连接多个客户端;
- VMware虚拟机安装指南:下载、配置与启动操作详解
- gamebox.h-C++头文件,1.0版本
- 使用mysql存储过程和触发器实现审计日志记录.zip
- 计算机科学教育-数据结构课程设计目标与实践
- 磁环组装自动压合平衡测试设备工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- 医疗器械质量管理体系内审员试卷考题,GBT42061,ISO13485
- 三相交错LLC谐振仿真闭环,Y型联接(图1主回路图),自均流(图2三相谐振电流波形),软开关(图3是原边mos的驱动和DS和电流波形),每相移相120度(图4驱动波形),图5输出电压电流波形 ,送对
- VSCode下C/C++开发环境配置指南
- MATLAB语音识别 matlab语音识别,可以识别数字0-9,有gui界面,注释齐全,有报告 (本程序测试版本为Matlab 2019b,低于此版本的请安装新版,以免无法运行) 链接为电子资料
- Java开发IDE-IntelliJ IDEA的下载与安装指南
- 线控转向系统Carsim和Simulink联合仿真模型,带Carsim数据库,C级车 【正向建模,利用三环PID控制算法控制无刷直流电机获得前轮转角】 主要根据Carsim自带的转向系统,查出小齿轮
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


