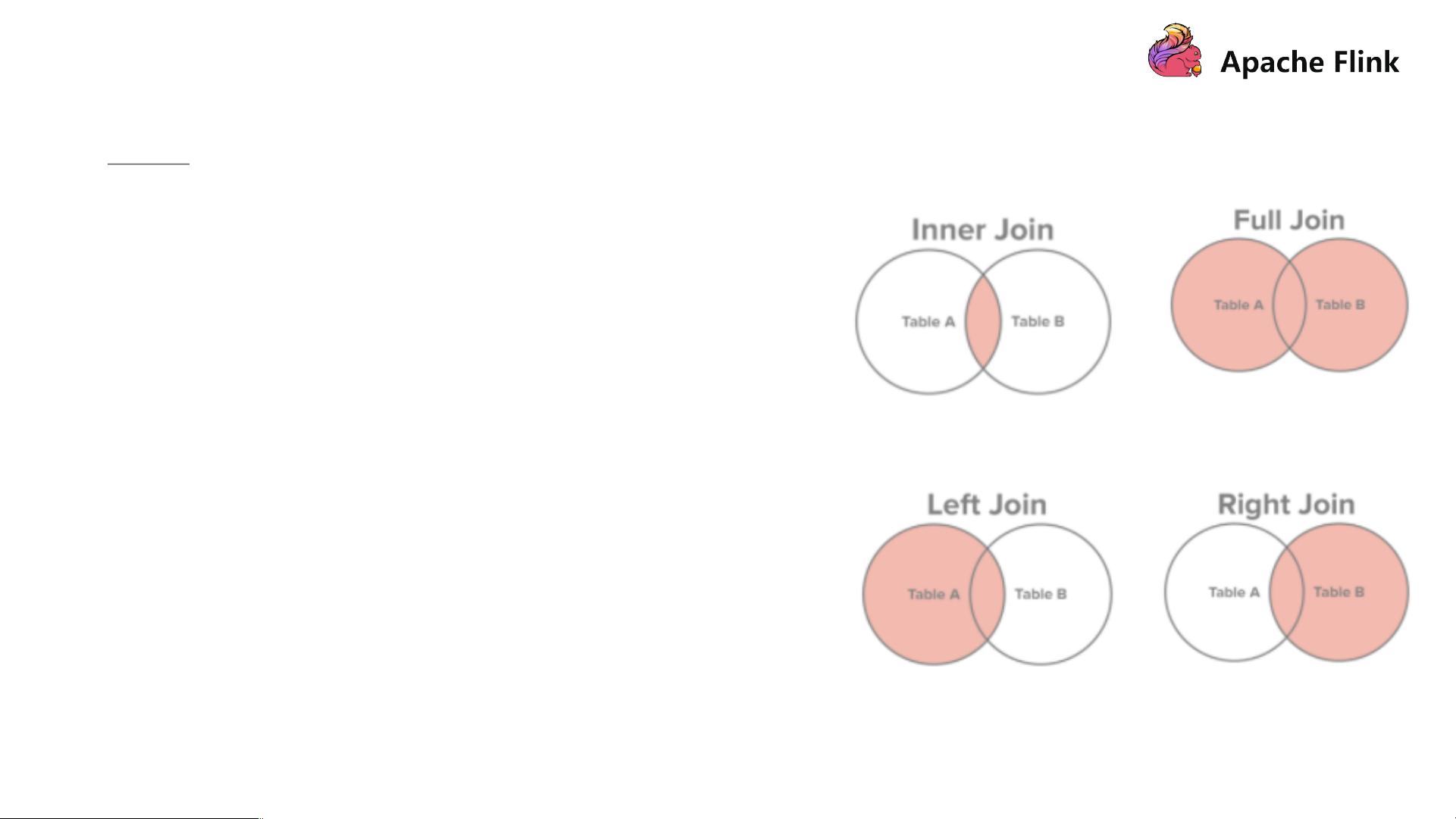
Apache Flink 维表关联实战 Apache Flink 是一个流处理引擎,它支持实时数据处理和批处理。Apache Flink 中的 Join 操作是指将两个或多个表根据某些公共列合并成一个新的表。Join 操作是数据库查询中最基本和最重要的操作之一。 Join 的概念 ---------------- Join 是一种将两个或多个表根据某些公共列合并成一个新的表的操作。Join 操作可以将多个表的数据合并成一个新的表,以便进行更复杂的数据分析和处理。 Join 的特点 ------------- 1. 业务使用频繁:Join 操作是数据库查询中最基本和最重要的操作之一,几乎所有的数据库查询都涉及到 Join 操作。 2. 优化规则复杂:Join 操作的优化规则非常复杂,需要考虑到多个表的数据结构、索引、统计信息等各种因素。 Join 的类型 ------------- 1. Cross Join(交叉连接):计算笛卡尔积,生成的表的行数是两个表的行数的乘积。 2. Inner Join(内连接):只有当两个表的公共列的值相同时,才将行合并到结果表中。 3. Left Outer Join(左外连接):返回左表所有行,右表不存在的行补空。 4. Right Outer Join(右外连接):返回右表所有行,左表不存在的行补空。 5. Full Outer Join(全外连接):返回左表和右表的并集,不存在的一边补空。 Join 的实现 ------------- 1. Nested Loop Join:最为简单直接,将两个数据集加载到内存,并用内嵌遍历的方式来逐个比较两个数据集内的元素是否符合 Join 条件。 2. Sort-Merge Join:分为 Sort 和 Merge 阶段,首先将两个数据集分别排序,然后对两个有序数据集分别进行遍历和匹配,类似于归并排序的合并。 3. Hash Join:先将一个数据集转换为 Hash Table,然后遍历另外一个数据集元素并与 Hash Table 内的元素进行匹配。 Flink SQL Join ---------------- Flink SQL Join 是 Flink 中的 Join 操作,支持 Streaming SQL Join 和 Batch SQL Join。Streaming SQL Join 面向无界数据集的 SQL,无法缓存历史所有数据,因此像 Sort-Merge Join 需要对数据进行排序是无法做到的,Nested-loop Join 和 Hash Join 经过一定的改良则可以满足实时 SQL 的要求。 Flink 中的 Join 实现 --------------------- Flink 中的 Join 实现主要有三种:Nested Join、Sort-Merge Join 和 Hash Join。Nested Join 在实时 Join 的实现中起着重要的作用,可以满足实时 SQL 的要求。 问题和改进措施 ------------------- 问题:需要保存两个数据源表的内容,随着时间的增长,需要保存的历史数据无止境地增长,导致很不方便的数据管理问题。 改进措施: * 使用 Flink 的窗口函数来实现数据的聚合和处理。 * 使用 Flink 的 Cache 机制来减少数据的存储空间。 * 使用 Flink 的 Checkpoint 机制来确保数据的一致性和可靠性。 Apache Flink 中的 Join 操作是实时数据处理和批处理的重要组成部分,需要根据实际情况选择合适的 Join 实现方式和优化策略,以提高数据处理效率和可靠性。
剩余42页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~