





This paper is included in the Proceedings of the
19th USENIX Conference on File and Storage Technologies.
February 23–25, 2021
978-1-939133-20-5
Open access to the Proceedings
of the 19th USENIX Conference on
File and Storage Technologies
is sponsored by USENIX.
CNSBench: A Cloud Native Storage Benchmark
Alex Merenstein, Stony Brook University; Vasily Tarasov, Ali Anwar, and
Deepavali Bhagwat, IBM Research–Almaden; Julie Lee, Stony Brook University;
Lukas Rupprecht and Dimitris Skourtis, IBM Research–Almaden; Yang Yang
and Erez Zadok, Stony Brook University
https://www.usenix.org/conference/fast21/presentation/merens tein

CNSBench: A Cloud Native Storage Benchmark
Alex Merenstein
1
, Vasily Tarasov
2
, Ali Anwar
2
, Deepavali Bhagwat
2
, Julie Lee
1
,
Lukas Rupprecht
2
, Dimitris Skourtis
2
, Yang Yang
1
, and Erez Zadok
1
1
Stony Brook University and
2
IBM Research–Almaden
Abstract
Modern hybrid cloud infrastructures require software to be easily
portable between heterogeneous clusters. Application container-
ization is a proven technology to provide this portability for the
functionalities of an application. However, to ensure performance
portability, dependable verification of a cluster’s performance
under realistic workloads is required. Such verification is usually
achieved through benchmarking the target environment and its
storage in particular, as I/O is often the slowest component in an
application. Alas, existing storage benchmarks are not suitable
to generate cloud native workloads as they do not generate any
storage control operations (e.g., volume or snapshot creation),
cannot easily orchestrate a high number of simultaneously
running distinct workloads, and are limited in their ability to
dynamically change workload characteristics during a run.
In this paper, we present the design and prototype for
the first-ever Cloud Native Storage Benchmark—
CNSBench
.
CNSBench
treats control operations as first-class citizens and al-
lows to easily combine traditional storage benchmark workloads
with user-defined control operation workloads. As
CNSBench
is
a cloud native application itself, it natively supports orchestration
of different control and I/O workload combinations at scale. We
built a prototype of
CNSBench
for Kubernetes, leveraging sev-
eral existing containerized storage benchmarks for data and meta-
data I/O generation. We demonstrate
CNSBench
’s usefulness
with case studies of Ceph and OpenEBS, two popular storage
providers for Kubernetes, uncovering and analyzing previously
unknown performance characteristics.
1 Introduction
The past two decades have witnessed an unprecedented growth of
cloud computing [54]. By 2020, many businesses have opted to
run a significant portion of their workloads in public clouds [43]
while the number of cloud providers has multiplied, creating a
broad and diverse marketplace [1,17,18,25]. At the same time,
it became evident that, in the foreseeable future, large enterprises
will continue (i) running certain workloads on-premises (e.g.,
due to security concerns), and (ii) employing multiple cloud
vendors (e.g., to increase cost-effectiveness or to avoid vendor
lock-in). These hybrid multicloud deployments [41] offer the
much needed flexibility to large organizations.
One of the main challenges in operating in a hybrid multicloud
is workload portability—allowing applications to easily move
between public and private clouds, and on-premises data
centers [52]. Software containerization [10] and the larger
cloud native [7] ecosystem is considered to be the enabler for
providing seamless application portability [44]. For example,
a container image [40] includes all user-space dependencies
of an application, allowing it to be deployed on any container-
enabled host while container orchestration frameworks such as
Kubernetes [22] provide the necessary capabilities to manage
applications across different cloud environments. Kubernetes’s
declarative nature [23] lets users abstract application and service
requirements from the underlying site-specific resources. This
allows users to move applications across different Kubernetes
deployments—and therefore across clouds—without having to
consider the underlying infrastructure.
An essential step for reliably moving an application from one
location to another is validating its performance on the destination
infrastructure. One way to perform such validation is to replicate
the application on the target site and run an application-level
benchmark. Though reliable, such an approach requires a
custom benchmark for every application. To avoid this extra
effort, organizations typically resort to using component-specific
benchmarks. For instance, for storage, an administrator might run
a precursory I/O benchmark on the projected storage volumes.
A fundamental requirement for such a benchmark is the
ability to generate realistic workloads, so that the experimental
results reflect an application’s actual post-move performance.
However, existing storage benchmarks are inadequate to generate
workloads characteristic of modern cloud native environments
due to three main shortcomings.
First, cloud native storage workloads include a high number
of control operations, such as volume creation, snapshotting,
etc. These operations have become much more frequent in
cloud native environments as users, not admins [13,24], directly
control storage for their applications. As large clusters have
many users and frequent deployment cycles, the number of
control operations is high [4,51,55].
Second, a typical containerized cluster hosts a high number
of diverse, simultaneously running workloads. Although this
workload property, to some extent, was present before in
VM-based environments, containerization drives it to new
levels. This is partly due to higher container density per
node, fueled by the cost effectiveness of co-locating multiple
tenants in a shared infrastructure and the growing popularity of
microservice architectures [57, 62]. To mimic such workloads,
one needs to concurrently run a large number of distinct storage
benchmarks across containers and coordinate their progress,
which currently involves a manual and laborious process that
becomes impractical in large-scale cloud native environments.
Third, applications in cloud native environments are highly
USENIX Association 19th USENIX Conference on File and Storage Technologies 263

dynamic. They frequently start, stop, scale, failover, update,
rollback, and more. This leads to various changes in workload
behavior over short time periods as the permutation of workloads
running on each host change. Although existing benchmarks
allow one to configure separate runs of a benchmark to generate
different phases of workloads [47,48], such benchmarks do not
provide a versatile way to express dynamicity within a single run.
In this paper we present
CNSBench
—the first open-source
Cloud Native Storage Benchmark capable of (i) generating
realistic control operations; (ii) orchestrating a large variety
of storage workloads; and (iii) dynamically morphing the
workloads as part of a benchmark run.
CNSBench
incorporates a library of existing data and
metadata benchmarks (e.g., fio [15], Filebench [60], YCSB [46])
and allows users to extend the library with new containerized I/O
generators. To create realistic control operation patterns, a user
can configure
CNSBench
to generate different control operations
following variable (over time) operation rates.
CNSBench
can
therefore be seen as both (i) a framework used for coordinating
the execution of large number of containerized I/O benchmarks
and (ii) a benchmark that generates control operations. Crucially,
CNSBench
bridges these two roles by generating the control
operations to act on the storage used by the applications, thereby
enabling the realistic benchmarking of cloud native storage.
As an example, consider an administrator evaluating storage
provider performance under a load that includes frequent snap-
shotting. Conducting an evaluation manually requires the ad-
ministrator to create multiple storage volumes, run a complex
workload that will use that volumes (e.g., a MongoDB database
with queries generated by YCSB), and then take snapshots of
the volumes while the workload runs. The same evaluation with
CNSBench
requires just that the administrator specify which
workload to run, which storage provider to use, and the rate with
which snapshots should be taken.
CNSBench
handles instantiat-
ing each component of the workload (i.e., the storage volume, the
MongoDB database, and the YCSB client) and then executing the
control operations to snapshot the volume as the workload runs.
While developing
CNSBench
, we have also been building out
a library of pre-defined workloads. The previous example uses
one such workload, which consists of YCSB running against
a MongoDB instance. If the administrator instead wanted to
instantiate a workload not found in our library, it is easy to
package an existing application into a workload that can be
used by
CNSBench
. In that case, we would also encourage
the administrator to contribute their new workload back to our
library so that it could be used by a broader community.
To demonstrate
CNSBench
’s versatility, we conducted a
study comparing cloud native storage providers. We pose three
questions in our evaluation: (A) How fast are different cloud
storage solutions under common control operations? (B) How do
control operations impact the performance of user applications?
(C) How do different workloads perform when run alongside
other workloads? We use Ceph [5] and OpenEBS [28] in
our case study as sample storage providers. Our results show
that control operations can vary significantly between storage
providers (e.g., up to 8.5
×
higher Pod creation rates) and that
they can slow down I/O workloads by up to 38%.
In summary, this paper makes the following contributions:
1.
We identify the need and unique requirements for cloud
native storage benchmarking.
2.
We present the design and implementation of
CNSBench
,
a benchmark that fulfills the above requirements and allows
users to conveniently benchmark cloud native storage
solutions with realistic workloads at scale.
3.
We use
CNSBench
to study the performance of two storage
solutions for Kubernetes (Ceph and OpenEBS) under
previously not studied workloads.
CNSBench
is open-source and available for download from
https://github.com/CNSBench.
2 Kubernetes Background
We implemented our benchmark for Kubernetes and so in
the following sections we use many Kubernetes concepts to
contextualize
CNSBench
’s design and use cases. Therefore, we
begin with a brief background on how Kubernetes operates.
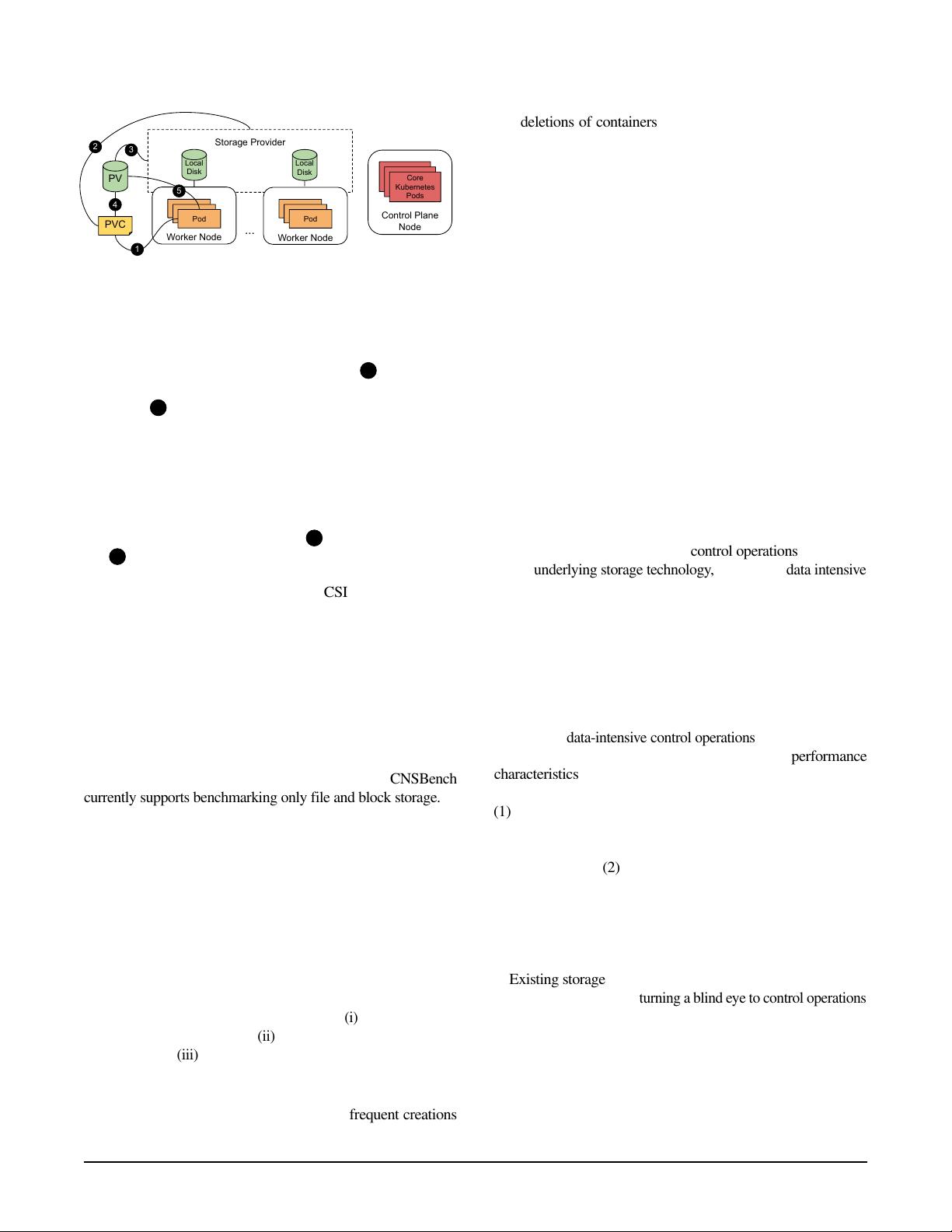
Overview.
A basic Kubernetes cluster is shown in Figure 1.
It consists of control plane nodes, worker nodes, and a storage
provider (among other components). Worker and control plane
nodes run Pods, the smallest unit of workload in Kubernetes
that consist of one or more containers. User workloads run on
the worker nodes, whereas core Kubernetes components run
on the control plane nodes. Core components include (1) the
API server, which manages the state of the Kubernetes cluster
and exposes HTTP endpoints for accessing the state, and (2) the
scheduler, which assigns Pods to nodes. Typically, a Kubernetes
cluster has multiple worker nodes and may also have multiple
control plane nodes for high availability.
The storage provider is responsible for provisioning persistent
storage in the form of volumes as required by individual Pods.
There are many architectures, but the “hyperconverged” model
is common in cloud environments. In this model, the storage
provider aggregates the storage attached to each worker node
into a single storage pool.
The state of a Kubernetes cluster, such as what workloads
are running on what hosts, is tracked using different kinds of
resources. A resource consists of a desired state (also referred
to as its specification) and a current state. It is the job of that re-
source’s controllers to reconcile a resource’s current and desired
states, for example, starting a Pod on node X if its desired state is
“running on Node X”. Pods and Nodes are examples of resources.
Persistent Storage.
Persistent storage in Kubernetes is
represented by resources called Persistent Volumes (PVs).
Access to a PV is requested by attaching the Pod to a resource
called a Persistent Volume Claim (PVC). Figure 1 depicts
this process:
1
A Pod that requires storage creates a PVC,
specifying how much storage space it requires and which storage
264 19th USENIX Conference on File and Storage Technologies USENIX Association
Pod
Pod
Local
Disk
Worker Node
Storage Provider
Local
Disk
...
Pod
Core
Kubernetes
Pods
Control Plane
Node
Pod
Pod
Worker Node
Pod
PV
PVC
4
1
3
5
2
Figure 1: Basic topology of a Kubernetes cluster, with a single
control plane node, multiple worker nodes, and a storage
provider which aggregates local storage attached to each worker
node. Also shows the operations and resources involved in
providing a Pod with storage.
provider the PV should be provisioned from.
2
If there is an
existing PV that will satisfy the storage request then it is used.
Otherwise,
3
a new PV is provisioned from the storage provider
specified in the PVC. A PVC specifies what storage provider
to use by referring to a particular Storage Class. This class is
a Kubernetes resource that combines a storage provider with a
set of configuration options. Examples of common configuration
options are what file system to format the PV with and whether
the PV should be replicated across different nodes.
Once the PV has been provisioned,
4
it is bound to the PVC,
and 5 the volume is mounted into the Pod’s file system.
Kubernetes typically communicates with the storage provider
using the Container Storage Interface (CSI) specification [9],
which defines a standard set of functions for actions such
as provisioning a volume and attaching a volume to a Pod.
Before CSI, Kubernetes had to be modified to add support for
individual storage providers. By standardizing this interface, a
new storage provider needs only to write a CSI driver according
to a well-defined API, to be used in any container orchetrator
supporting CSI (e.g., Kubernetes, Mesos, Cloud Foundry).
Although Kubernetes has good support for provisioning and
attaching file and block storage to pods via PVs and PVCs, no
such support exists for object storage. Therefore,
CNSBench
currently supports benchmarking only file and block storage.
3 Need for Cloud Native Storage Benchmarking
In this section we begin with describing the properties of cloud
native workloads, which current storage benchmarks cannot
recreate. We then present the design requirements for a cloud
native storage benchmark.
3.1 New Workload Properties
The rise of containerized cloud native applications has created
a shift in workload patterns, which makes today’s environments
different from previous generations. This is particularly true for
storage workloads due to three main reasons: (i) the increased fre-
quency of control operations; (ii) the high diversity of individual
workloads; and (iii) the dynamicity of these workloads.
Control Operations.
Previously infrequent, control operations
became significantly more common in self-service cloud native
environments. As an example, consider the frequent creations
and deletions of containers in a cloud native environment. In
many cases, these containers require persistent storage in the
form of a storage volume and hence, several control operations
need to be executed: the volume needs to be created, prepared
for use (e.g., formatted with a file system), attached to the
host where the container will run (e.g., via iSCSI), and finally
mounted in the container’s file system namespace. Even if a
container only needs to access a volume that already exists, there
are still at least two operations that must be executed to attach
the volume to the node where the container will run and mount
the volume into the container.
To get a better idea of how many control operations can be
executed in a cloud native environment, consider these statistics
from one container cluster vendor: in 2019 they observed that
over half of the containers running on their platform had a life-
time of no more than five minutes [37]. In addition, they found
that each of their hosts were running a median of 30 containers.
Given these numbers, a modestly sized cluster of 20 nodes would
have a new container being created every second on average.
We are not aware of any public datasets that provide insight into
what ratio of these containers require storage volumes. However,
anecdotal evidence and recent development efforts [14] indicate
that many containers do in fact attach to storage volumes.
In addition to being abundant, control operations, depending
on the underlying storage technology, can also be data intensive.
This makes them slow and increases their impact on the I/O path
of running applications. For example, volume creation often
requires (i) time-consuming file system formatting; (ii) snapshot
creation or deletion, which, depending on storage design, may
consume a significant amount of I/O traffic; (iii) volume resizing,
which may require data migration and updates to many metadata
structures; and (iv) volume reattachment, which causes cache
flushes and warmups.
Now that data-intensive control operations are more common,
there is a new importance to understanding their performance
characteristics. In particular, there are two categories of
performance characteristic that are important to understand:
(1) How long does it take a storage provider to execute a
particular control operation? This is important because in
many cases, control operations sit on the critical path of the
container startup. (2) What impact does the execution have on
I/O workloads? This impact can be significant either due to the
increased load on the storage provider or the particular design
of the storage provider. For example, some storage providers
freeze I/O operations during a volume snapshot, which can lead
to a spike in latency for I/O operations [33].
Existing storage benchmarks and traces focus solely on data
and metadata operations, turning a blind eye to control operations.
Diversity and Specialization.
The lightweight nature of con-
tainers allows many different workloads to share a single server
or a cluster [37]. Workload diversity is fueled by a variety of
factors. First, projects such as Docker [11] and Kubernetes [22]
have made containerization and cloud native computing more
accessible to a wide range of users and organizations, which is
USENIX Association 19th USENIX Conference on File and Storage Technologies 265
apparent in the diversity of applications present in public reposito-
ries. For example, on Docker Hub [12] there are container images
for fields such as bioinformatics, data science, high-performance
computing, and machine learning—in addition to the more
traditional cloud applications such as web servers and databases.
Additionally, the popularity of microservice architectures has
caused traditionally monolithic applications to be split up into
many small, specialized components [62]. Finally, the increas-
ingly popular serverless architecture [3], where functions run
in dynamically created containers, takes workload specialization
even further through an even finer-grained split of application
components, each with their own workload characteristics.
The result of these factors is that the workloads running in a
typical shared cluster (and on each of its individual hosts) have a
highly diverse set of characteristics in terms of runtime, I/O pat-
terns, and resource usage. Understanding system performance in
such an environment requires benchmarks that recreate the prop-
erties of cloud native workloads. Currently, such benchmarks
do not exist. Hence, realistic workload generation is possible
only by manual selection, creation, and deployment of several
appropriate containers (e.g., running multiple individual storage
benchmarks that each mimic the characteristics of a single
workload). As more applications of all kinds adopt container-
ization and are broken into sets of specialized microservices, the
number of containers that must be selected to make up a realistic
workload continues to increase. Making this selection manually
has become infeasible in today’s cloud native environments.
Elasticity and Dynamicity.
Cloud native applications are
usually designed to be elastic and agile. They automatically scale
to meet user demands, gracefully handle failed components, and
are frequently updated. Although some degree of elasticity and
dynamicity has always been a trait of cloud applications, the
cloud native approach takes it to another level.
In one example, when a company adopted cloud native
practices for building and operating their applications, their de-
ployment rate increased from rolling out a new version 2–3 times
per week to over 150 times in a single day [16]. Other examples
include companies utilizing cloud native architectures to achieve
rapid scalability in order to meet spikes in demand, for example
in response to breaking news [27] or the opening of markets [2].
Currently, benchmarks lack the capability to easily evaluate
application performance under these highly dynamic conditions.
In some cases, benchmark users resort to creating these condi-
tions manually to evaluate how applications will respond—for
example manually scaling the number of database instances [46].
However, the high degree of dynamicity and diversity found
in cloud native environments makes recreating these conditions
manually nearly impossible.
3.2 Design Requirements
The fundamental functionality gap in current storage benchmarks
is their inability to generate control-operation workloads
representative of cloud native environments. At the same time,
the I/O workload (data and metadata, not control operations)
remains an important component of cloud native workloads,
and is more diverse and dynamic than before. Therefore, the
primary goal for a cloud native storage benchmark is to enable
combining control-operation workloads and I/O workloads—to
better evaluate application and cluster performance. This goal
led us to define the following five core requirements:
1.
I/O workloads should be specified and created indepen-
dently from control workloads, to allow benchmarking
(i) an I/O workload’s performance under different control
workloads and (ii) a control workload’s performance with
different I/O workloads.
2.
It should be possible to orchestrate I/O and control work-
loads to emulate a dynamic environment that is representa-
tive of clouds today. In addition, it should be possible to gen-
erate control workloads that serve as microbenchmarks for
evaluating the performance of individual control operations.
3.
I/O workloads should be generated by running existing
tools or applications, either synthetic workload generators
like Filebench or real applications such as a web server
with a traffic generator.
4.
It should be possible for users to quickly configure and run
benchmarks, without sacrificing the customizability offered
to more advanced users.
5.
The benchmark should be able to aggregate unstructured
output from diverse benchmarks in a single, convenient
location for further analyses.
A benchmark which meets these requirements will allow a user
to understand the performance characteristics of their application
and their cluster under realistic cloud native conditions.
4 CNSBench Design and Implementation
To address the current gap in benchmarking capabilities in cloud
native storage, we have implemented the Cloud Native Storage
Benchmark—
CNSBench
. Next, we describe
CNSBench
’s
design and implementation. We first overview its architecture
and then describe the new Kubernetes Benchmark custom
resource and its corresponding controller in more detail.
Overview.
In Kubernetes, a user creates Pods (one of Kuber-
netes’ core resources) by specifying the Pod’s configuration in
a YAML file and passing that file to the
kubectl
command
line utility. Similarly, we want
CNSBench
users to launch
new instances by specifying
CNSBench
’s configuration in a
YAML file and passing that file to
kubectl
. To achieve that,
our
CNSBench
implementation follows the operator design
pattern, which is a standard mechanism for introducing new
functionality into a Kubernetes cluster [31]. In this pattern, a
developer defines an Operator that comprises a custom resource
and a controller for that resource. For our implementation of
CNSBench
, we defined a custom Benchmark resource and
implemented a corresponding Benchmark Controller. Together,
these two components form the
CNSBench
Operator. The
Benchmark resource specifies the I/O and control workloads,
which the controller is then responsible for running.
266 19th USENIX Conference on File and Storage Technologies USENIX Association













