Python 获得 pdf 中的文字、图片文字方法。
OCR,全称 Optical character recognition,中文译名叫做光学文字识别。它把图像中的字
符,转换为机器编码的文本的一种方法。OCR 技术在印刷行业应用得非常多,也广泛用于识
别图片中的文字数据 – 比如护照,支票,银行声明,收据,统计表单,邮件等。
pytesseract,即 Python-tesseract,是 Google Tesseract ORC 引擎的封装。首次于 2014 年
提出,支持的图片格式有’JPEG’, ‘PNG’, ‘PBM’, ‘PGM’, ‘PPM’, ‘TIFF’, ‘BMP’, ‘GIF’,只需要简短的
代码就能够提取图片中的字符合文字了,极大方便文字工作。
一、准备工作
1,安装 pillow 或者 PIL,主要用来打开本地图片
pip install PIL
pip install pillow
2,安装 pytesseract,主要用来将图片里面文字转化字符串或者 pdf
pip install pytesseract
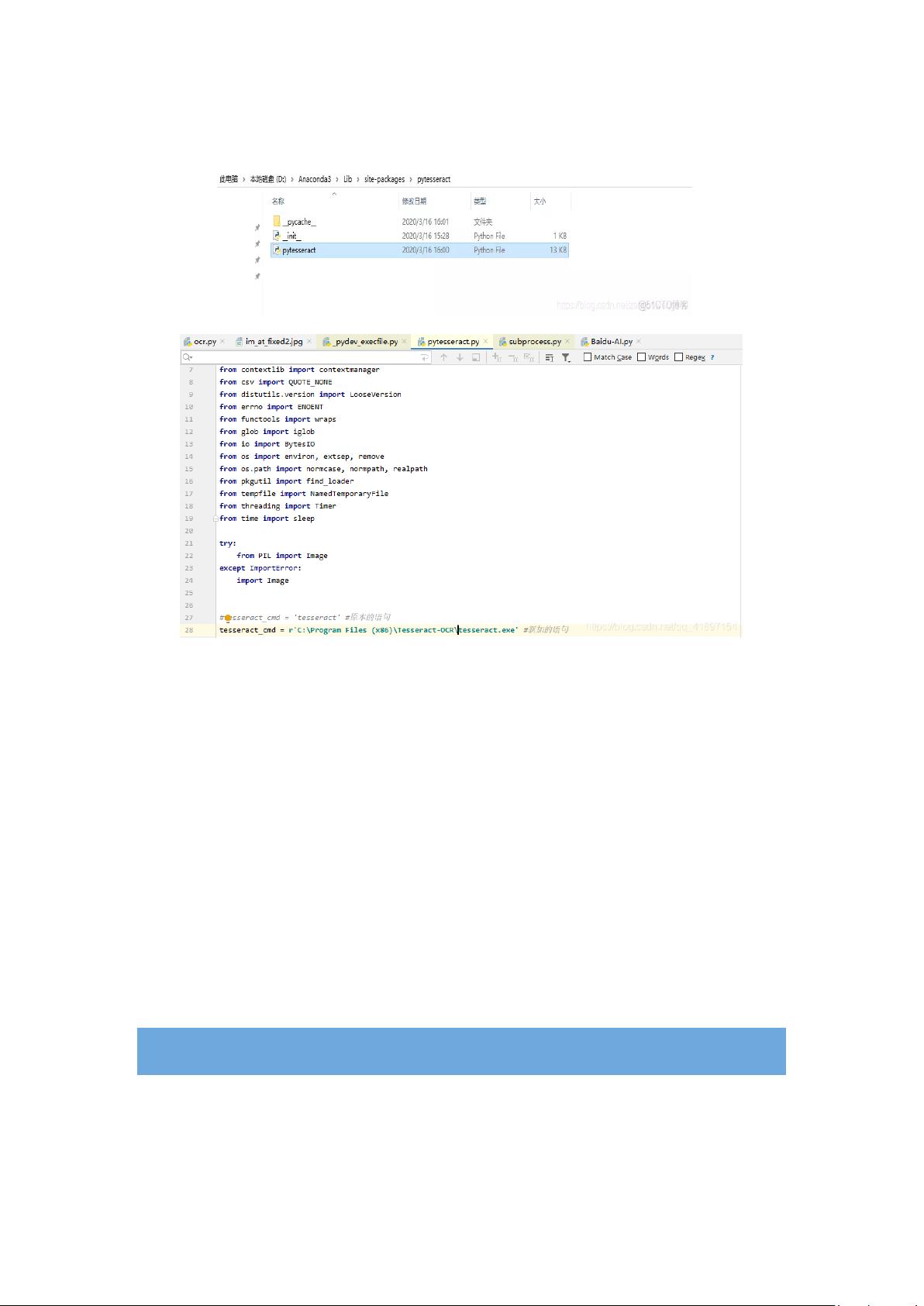
3,安装 Tesseract-OCR 应用程序
进入 https://pan.baidu.com/s/1qXumxdltxOnb0geaE_1U-Q
下载 tesseract-ocr-w64-v5.0.0.exe
设置环境变量:新增系统变量 TESSDATA_PREFIX
新增 PATH 路径: