twitter stream的创始人 Nathan Marz 在2012.3.16号的培训课件,详细讲解了stream 的架构和工作原理。
Summary
Nathan Marz discusses Storm concepts –streams, spouts, bolts, topologies-, explaining how to use Storms’ Clojure DSL for real-time stream processing, distributed RPS and continuous computations.
Bio
Nathan Marz is Lead Engineer on Twitter's Publisher Analytics team. Previously Nathan was the lead engineer of BackType which was acquired by Twitter in July of 2011. He is a major believer in the power of open source and has authored some significant Clojure-based open source projects, including Cascalog, ElephantDB, and Storm.
About the conference
Clojure/West is a new conference bringing the Clojure community together to discuss techniques, tools, and the state of the Clojure ecosystem March 16-17th for three tracks of sessions. Prior to the conference, register for three days of training by the Clojure experts.
### Storm: 分布式与容错实时计算
#### 概述
Storm 是一款开源的分布式实时计算系统,由 Twitter 的流处理技术创始人 Nathan Marz 开发,并于2012年发布。它能够处理大量的数据流,实现低延迟的数据处理,并提供容错机制确保数据处理的可靠性。Storm 的设计目标是简化大数据实时处理过程中的复杂性,通过提供一种高级抽象层,使得开发者可以专注于业务逻辑而无需过多关注底层细节。
#### 基本信息
- **开源时间**:2012年9月19日。
- **代码规模**:实现仅包含大约15,000行代码。
- **用户范围**:截至当时已经被超过25家公司采用。
- **社区活跃度**:在GitHub上拥有超过2,700个关注者(当时为所有JVM项目中最受欢迎的);邮件列表中有超过2,300条消息和超过670名成员。
#### 之前的方法:问题与不足
在 Storm 出现之前,通常使用队列结合多个工作进程的方式来处理实时数据流。这种方式存在诸多问题:
- **扩展性差**:每次扩展都需要重新配置或重新部署整个系统。
- **容错性差**:一旦某个工作节点出现故障,整个系统的稳定性会受到很大影响。
- **编码复杂**:开发人员需要手动处理许多细节,例如消息传递、错误恢复等,这增加了编码的难度和出错的可能性。
#### Storm 的设计理念
针对上述问题,Storm 提出了以下设计理念:
- **数据处理的保证**:确保每个数据项都能被正确处理。
- **水平扩展性**:能够轻松地横向扩展到更多的节点。
- **容错性**:自动处理节点故障,保证数据不丢失且系统持续运行。
- **无中间消息代理**:减少额外的中间件依赖,提高性能和降低复杂性。
- **高级抽象**:提供比简单的消息传递更高级的抽象接口,方便开发者快速构建应用。
- **易用性**:“开箱即用”,简单高效。
#### 关键概念
- **流(Stream)**:一个无限的数据元组序列。
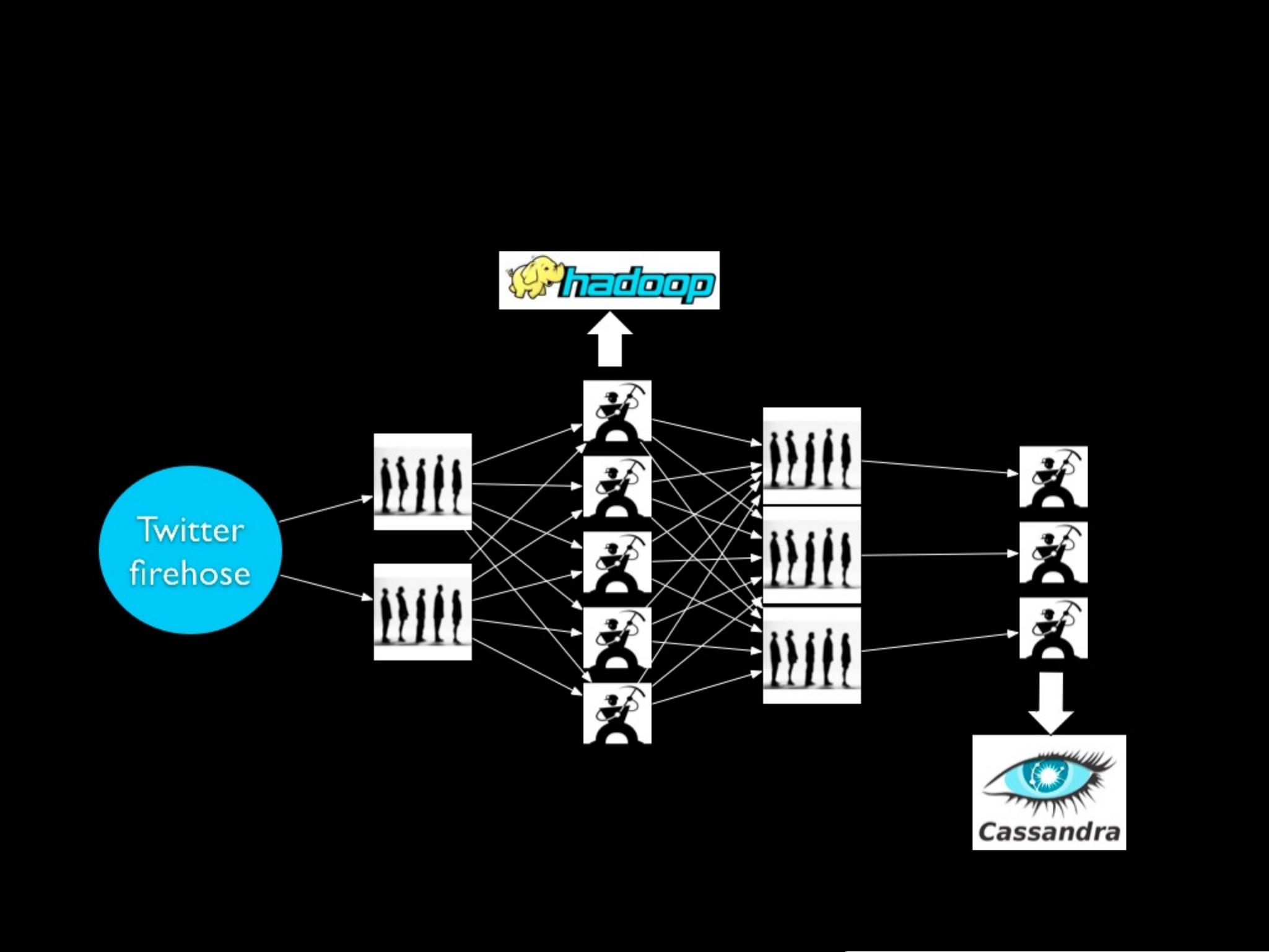
- **源头(Spout)**:数据流的源头,负责从外部数据源读取数据并发送到 Storm 的处理管道中。
- **处理器(Bolt)**:接收输入流并生成新的输出流的组件。它可以执行各种操作,如函数计算、过滤、聚合等。
- **拓扑(Topology)**:由源头和处理器组成的网络结构,定义了数据处理的流程。
#### Stream 处理
- **连续计算(Continuous Computation)**:对不断流入的数据进行实时处理。
- **分布式远程过程调用(Distributed RPC)**:允许不同节点之间进行远程调用。
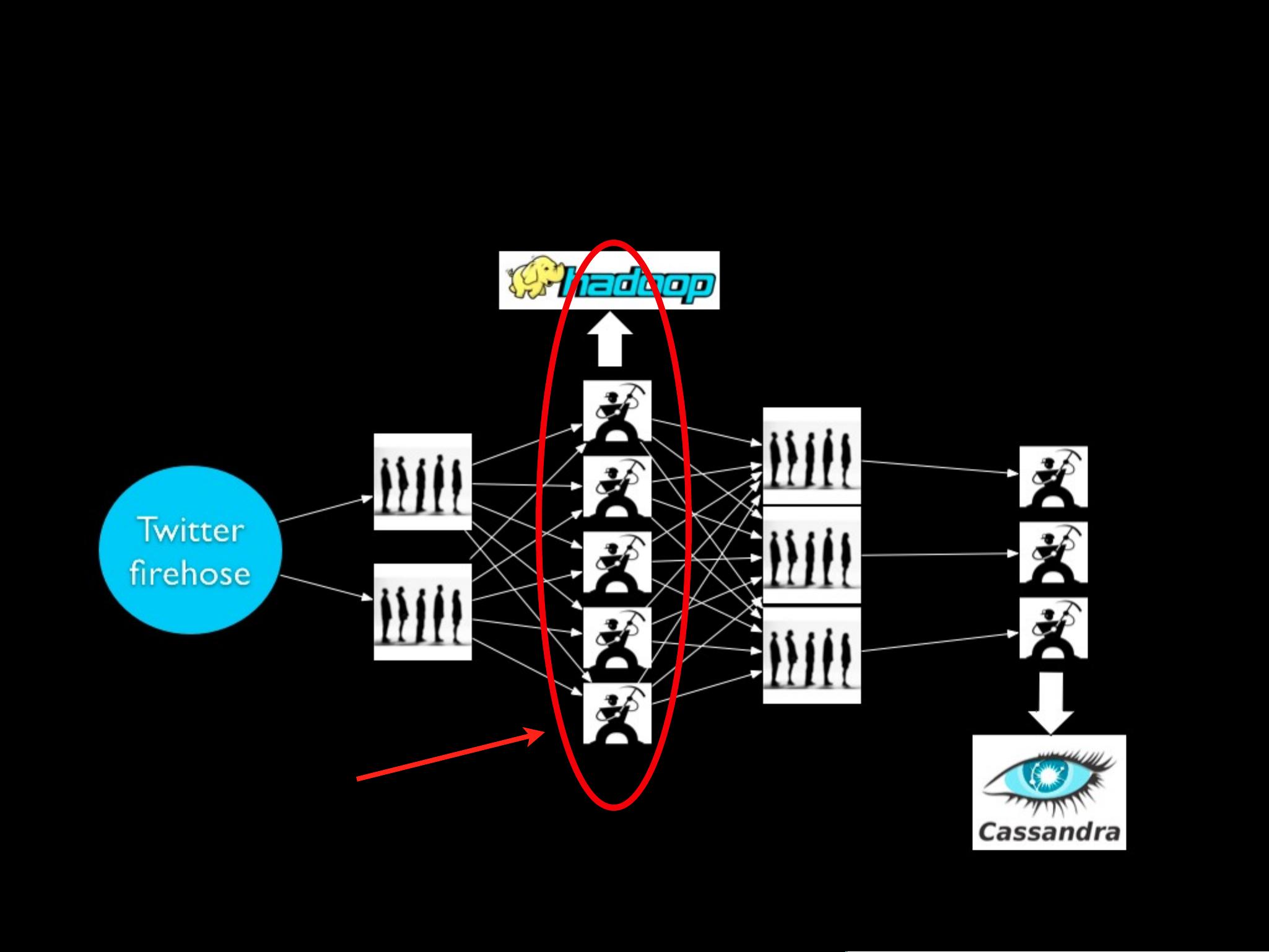
#### Storm 集群架构
- **主节点(Master Node)**:类似于 Hadoop 的 JobTracker,负责集群协调任务。
- **工作节点(Worker Node)**:执行实际的数据处理任务。
- **启动/停止拓扑**:用户可以通过控制台或者编程接口来启动或停止特定的拓扑结构。
#### Stream 组合
当一个元组被发送出去时,需要决定这个元组将被哪个任务处理。Storm 支持多种组合方式:
- **随机组合(Shuffle Grouping)**:随机选择一个任务。
- **字段组合(Field Grouping)**:根据元组中某些字段的哈希值来选择任务。
- **全部组合(All Grouping)**:将元组发送给所有相关的任务。
- **全局组合(Global Grouping)**:总是选择ID最小的任务。
#### 示例:流式单词计数
- 使用 TopologyBuilder 构建 Java 拓扑。
- 示例展示了如何通过 Storm 实现流式的单词计数功能。
#### 结论
Storm 以其强大的功能和简洁的设计,在实时数据处理领域占据了重要的位置。它不仅简化了实时计算系统的构建过程,还提高了系统的稳定性和扩展性,使得大规模实时数据分析成为可能。随着大数据处理需求的不断增加,Storm 的应用场景也将越来越广泛。





 uni2013-12-03匠心之作,强烈推荐
uni2013-12-03匠心之作,强烈推荐 oldratlee2014-11-25不错!可以看看了解。
oldratlee2014-11-25不错!可以看看了解。











