【贝壳OLAP平台架构演进】的讲解涵盖了从初期阶段到多引擎支持的演变过程,主要涉及以下几个关键知识点:
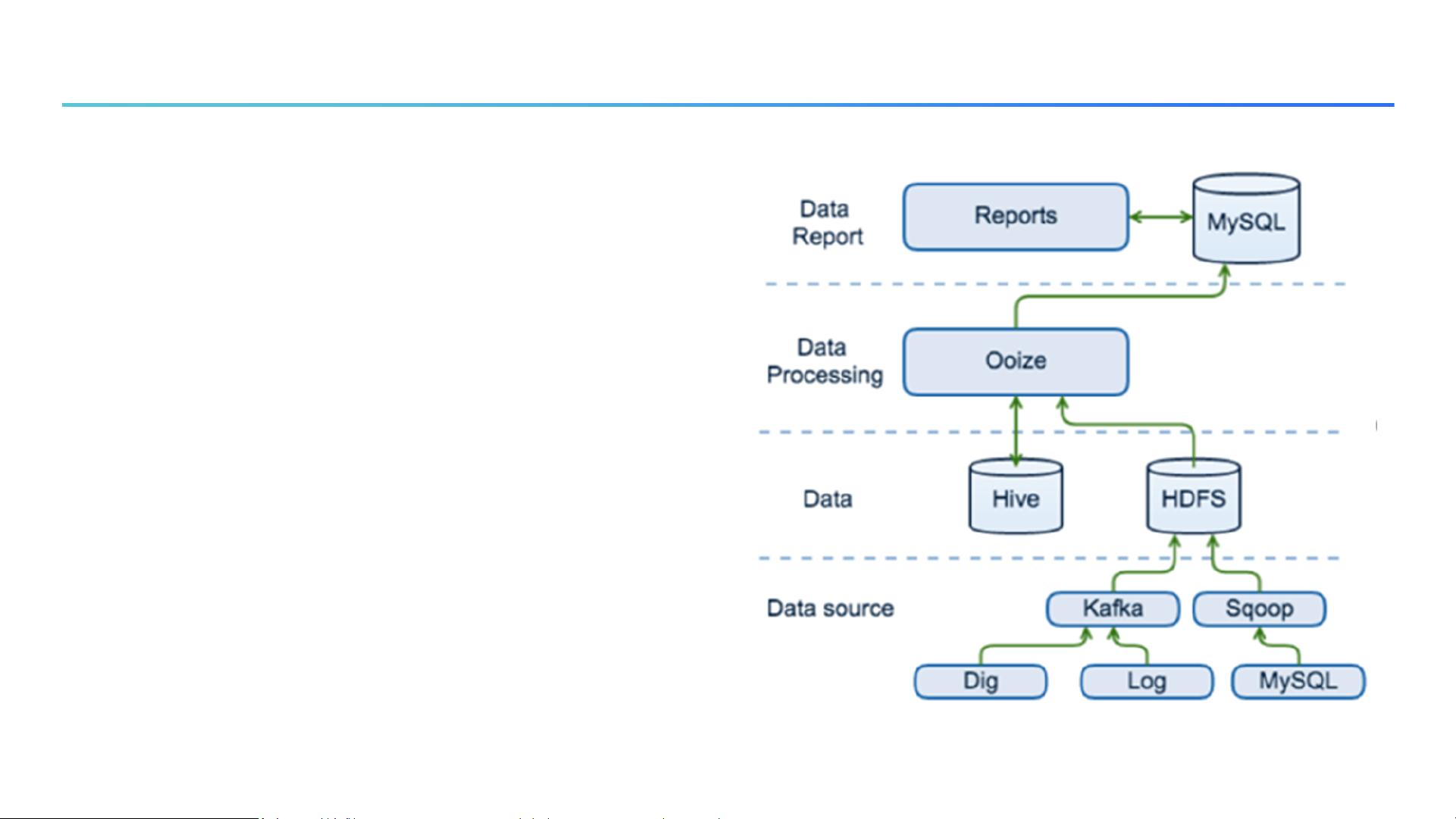
1. **初期阶段 - Hive到MySQL**:早期的贝壳OLAP平台采用Hive作为数据存储,然后通过ETL过程将数据导入MySQL进行分析。然而,这种模式受限于MySQL的数据处理能力,无法有效支持大数据量的存储和快速查询。同时,由于缺乏通用能力的沉淀,导致每次需求解决都需要定制开发,效率较低。
2. **基于Kylin的OLAP平台**:为了提升查询性能,贝壳引入了Apache Kylin,这是一个由eBay开发并贡献给Apache开源社区的高性能OLAP引擎。Kylin支持大规模数据处理,具备高并发和亚秒级查询能力,其核心是预计算,即预先计算好Cube以供后续快速查询。在这一阶段,贝壳构建了指标平台,对外提供统一API,实现指标的统一定义和口径管理,减轻了应用层直接操作SQL的复杂性。
3. **指标平台**:指标平台不仅定义了原子指标、派生指标和复合指标,还负责根据调用参数自动生成Kylin查询SQL,处理查询结果,如计算同环比和指标间运算。这一平台提升了开发效率,支撑了公司全面的指标体系。
4. **Kylin的应用与优化**:随着Kylin的广泛使用,贝壳建立了超过800个Cube,存储了数百TB的数据。然而,Kylin在维度数量、构建速度、灵活性以及实时性方面存在局限,如全量预计算导致Cube构建时间长,不支持实时指标(直到Kylin 3.0)等。
5. **多OLAP引擎支持**:为了解决单一Kylin引擎的问题,贝壳发展到了第三阶段,即支持多种OLAP引擎的OLAP平台。这一阶段,指标平台与Cube定义和管理解耦,引入了一个抽象层,使得Cube可以灵活地绑定到不同的OLAP引擎,如Kylin、Mondrian等,以满足不同业务场景的需求。
贝壳OLAP平台架构的演进充分展示了在大数据分析场景下,如何逐步优化和扩展系统,以应对不断增长的数据规模和复杂性。从初期的简单方案到引入先进的OLAP引擎,再到支持多种引擎的平台,这个过程体现了技术选型、平台化建设和持续优化的重要性。