
前言
在上一篇《大数据必须要学会的资源调度平台》中(还没看的小伙伴先去补一补课!),从 YARN 的基
本架构、YARN 的通信协议以及 YARN 的调度流程三个方面讲解了 YARN 的基本工作机制。
本文从 YARN 的最核心的组件资源调度器(Scheduler)出发,为大家深度解析 YARN 的调度机制,也会重
点介绍 Capacity Scheduler 和 Fair Scheduler 两种多用户资源调度器的应用场景和设计原理;此外,还
会介绍 YARN 常见的配置以及相关命令!
1.YANR 资源调度器
1.1资源调度器的基本架构
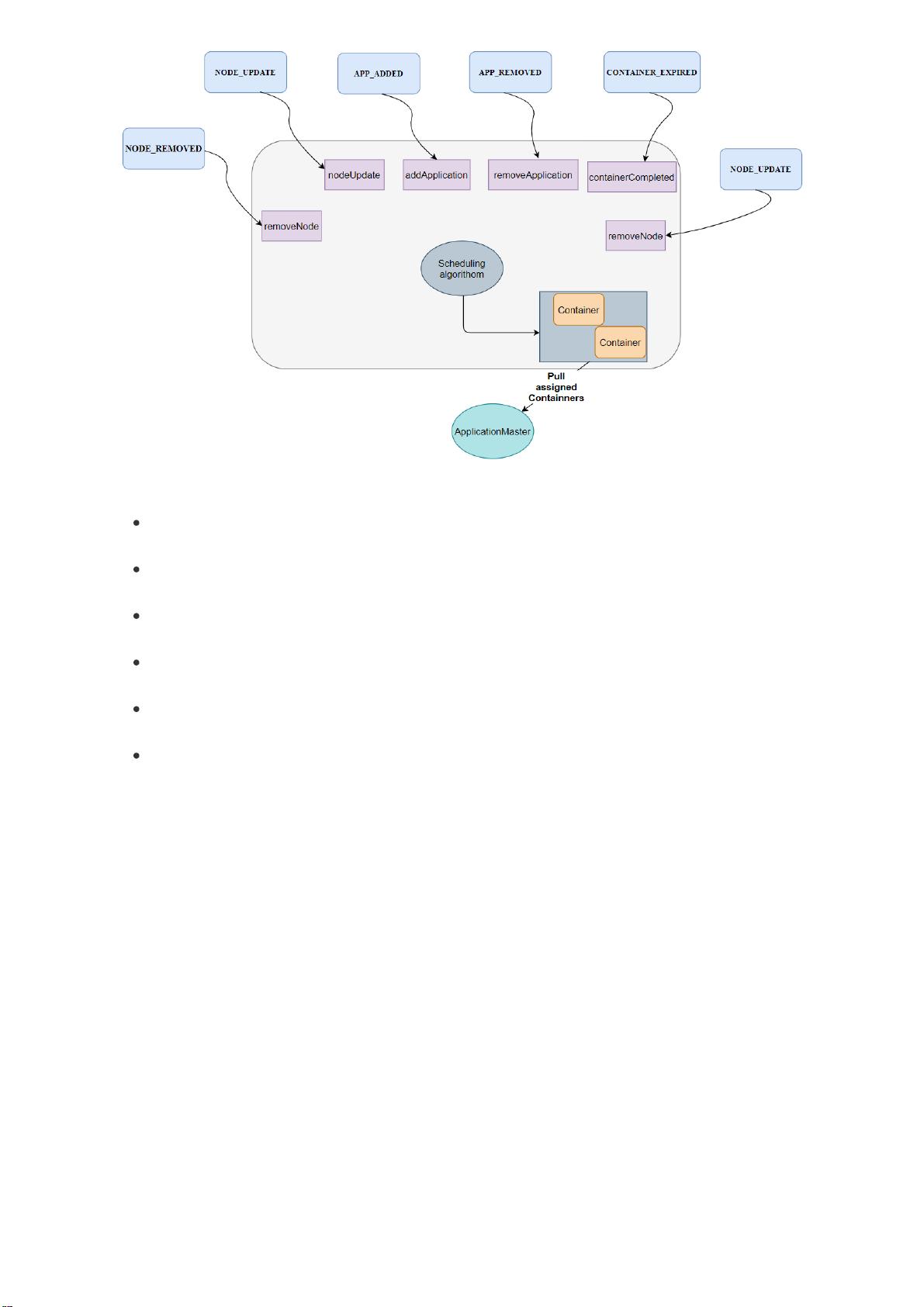
实际上,YARN 资源调度器是一个事件处理器,它需要处理来自外部的6种 Scheduler-EventType 类型
事件,然后根据事件的含义作相应的处理。其基本架构图如下:
剩余10页未读,继续阅读
资源评论













