FEDformer.pdf
需积分: 0 19 浏览量
2024-04-18
19:46:24
上传
评论
收藏 540KB PDF 举报


arXiv:2201.12740v3 [cs.LG] 16 Jun 2022
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term
Series Forecasting
Tian Zhou
* 1
Ziqing Ma
* 1
Qingsong Wen
1
Xue Wang
1
Liang Sun
1
Rong Jin
1
Abstract
Although Transformer-based methods have sig-
nificantly improved state-of-the-art results for
long-ter m series forecasting, they are not only
computationally expensive but more importa ntly,
are una ble to capture the global view of time
series (e.g. overall trend). To address these
problems, we propose to combine Transfor mer
with the seasonal-trend decomposition method,
in which the decomposition method captu res the
global profile of time series while Transformers
capture more detailed structures. To further en-
hance the perform ance of Transformer for long-
term prediction, we exploit the fact that most
time series tend to have a sparse representation
in well-known basis such as Fourier tra nsform,
and develop a frequency enhance d Transformer.
Besides being more effective, the pro posed
method, termed as Frequency Enhanced Decom-
posed Transformer (FEDformer), is more effi-
cient than standard Transformer with a line ar
complexity to the sequenc e length. Our empiri-
cal studies with six benchmark d a ta sets show that
compare d with state-of-the-art methods, FED-
former can reduce prediction error by 14.8% and
22.6% f or multivariate an d univariate time se-
ries, respectively. Code is publicly available at
https://github.com/MAZiqing /FED former.
1. Introduction
Long- term time series forecasting is a long- standing chal-
lenge in various applications (e.g., energy, weather, traf-
fic, economics). Despite the impressive results achieved
by RNN-typ e methods (Rangapuram et al., 2018; Flunkert
et al.
, 2017), they often suffer from the problem of gradi-
*
Equal contribution
1
Machine Intelligence Technology, Al-
ibaba Group.. Correspondence to: Tian Zhou <tian.zt@alibaba-
inc.com>, Rong Jin <jinrong.jr@alibaba-inc.com>.
Proceedings of the 39
th
International Conference on Machine
Learning, Baltimore, Maryland, USA, PMLR 162, 2022. Copy-
right 2022 by the author(s).
ent vanishing or explod ing (
Pascanu et al., 2013), signifi-
cantly limiting their performance. Following the recent suc-
cess in NLP and CV community (
Vaswani et al., 2017; De-
vlin et al., 2 019; Dosovitskiy et al., 2021; Rao et al., 2021),
Transformer (Vaswani et al., 201 7) has been introduced to
capture long-term dependencies in time series for ecasting
and shows p romising results (
Zhou et al., 2021; Wu et al.,
2021). Sin ce high computational complexity and memory
requirement make it difficult for Transformer to be applied
to long sequence modeling, numero us studies are devoted
to reduce the computational cost of Transformer (
Li et al.,
2019; Kitaev et a l., 2020; Zh ou et al., 2021; Wang et al.,
2020; Xiong et al., 2021; Ma et al., 2021). A through
overview of this line of works can be found in Appendix
A.
Despite the progr e ss mad e by Transformer-based meth-
ods for time series forecasting, they tend to fail in cap-
turing the overall characteristics/distribution of time se-
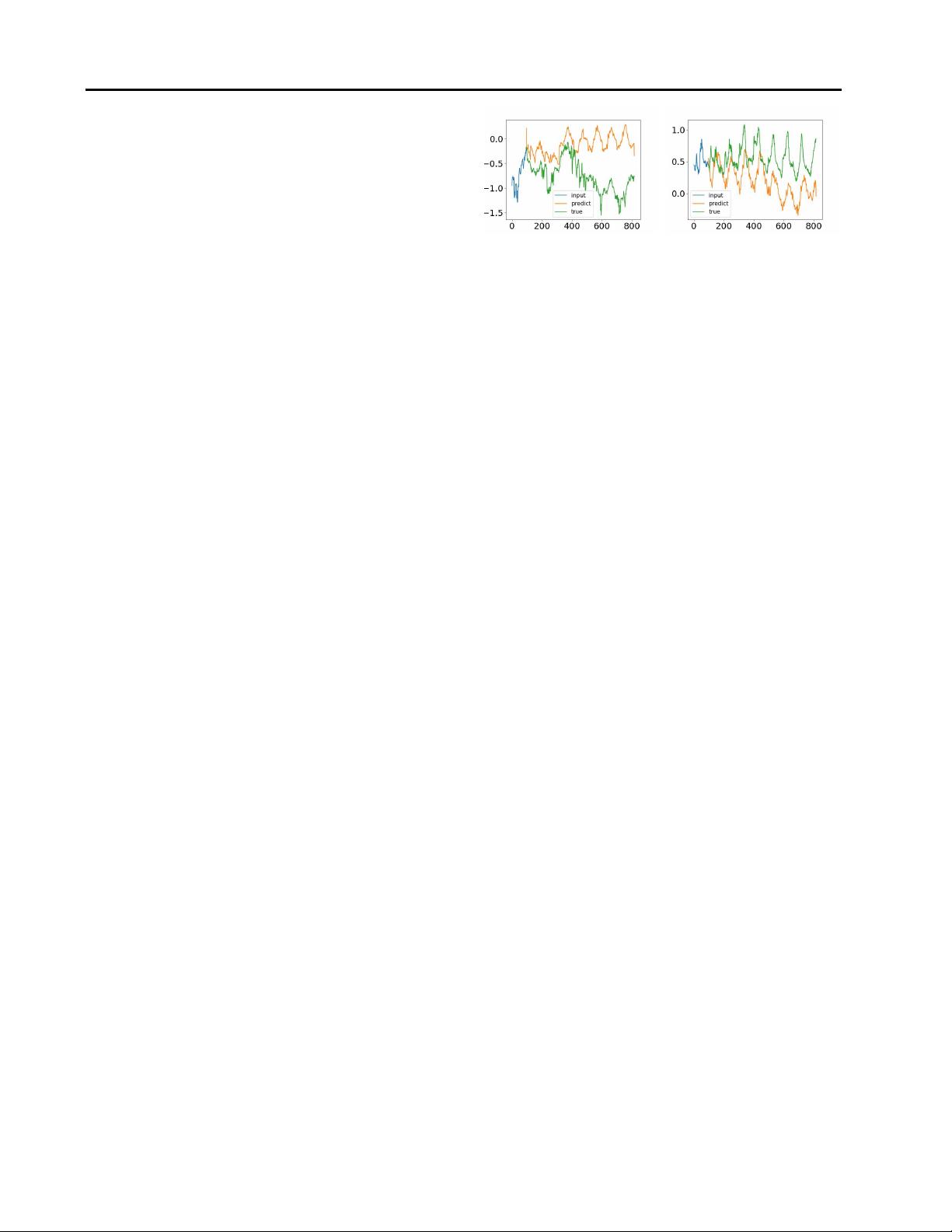
ries in some cases. In Figure
1, we compare the time
series of ground truth with that predicted by the vanilla
Transformer me thod (
Vaswani et al., 2017) in a re al-world
ETTm1 dataset (Zhou et al., 2021). It is clear that the pre-
dicted time series shared a different distribution from that
of ground truth. The discrepancy between ground truth
and p rediction could be explained by the point-wise atten-
tion an d prediction in Transformer. Since pre diction for
each timestep is made individually and independently, it
is likely that the model fails to maintain the global prop-
erty and statistics of time series as a whole. To address
this problem, we exploit two ideas in this work. The first
idea is to incorporate a seasonal- trend decomposition ap-
proach (Cleveland et al., 1990; Wen et al., 2019), which is
widely used in time series analysis, into the Transformer-
based method. Although this idea has been exploited be-
fore (
Oreshkin et al., 2019; Wu et al., 20 21), we present a
special design of network that is effective in bringing the
distribution of prediction close to that of ground truth, ac-
cording to Kologrov-Smirnov distribution test. Our second
idea is to combine Fourier analysis with the Transfo rmer-
based method. Instead o f applying Tr a nsformer to the time
domain, we ap ply it to the frequency domain which helps
Transformer b e tter capture global p roperties of time series.
Combining both ideas, we propose a Frequency Enhanced
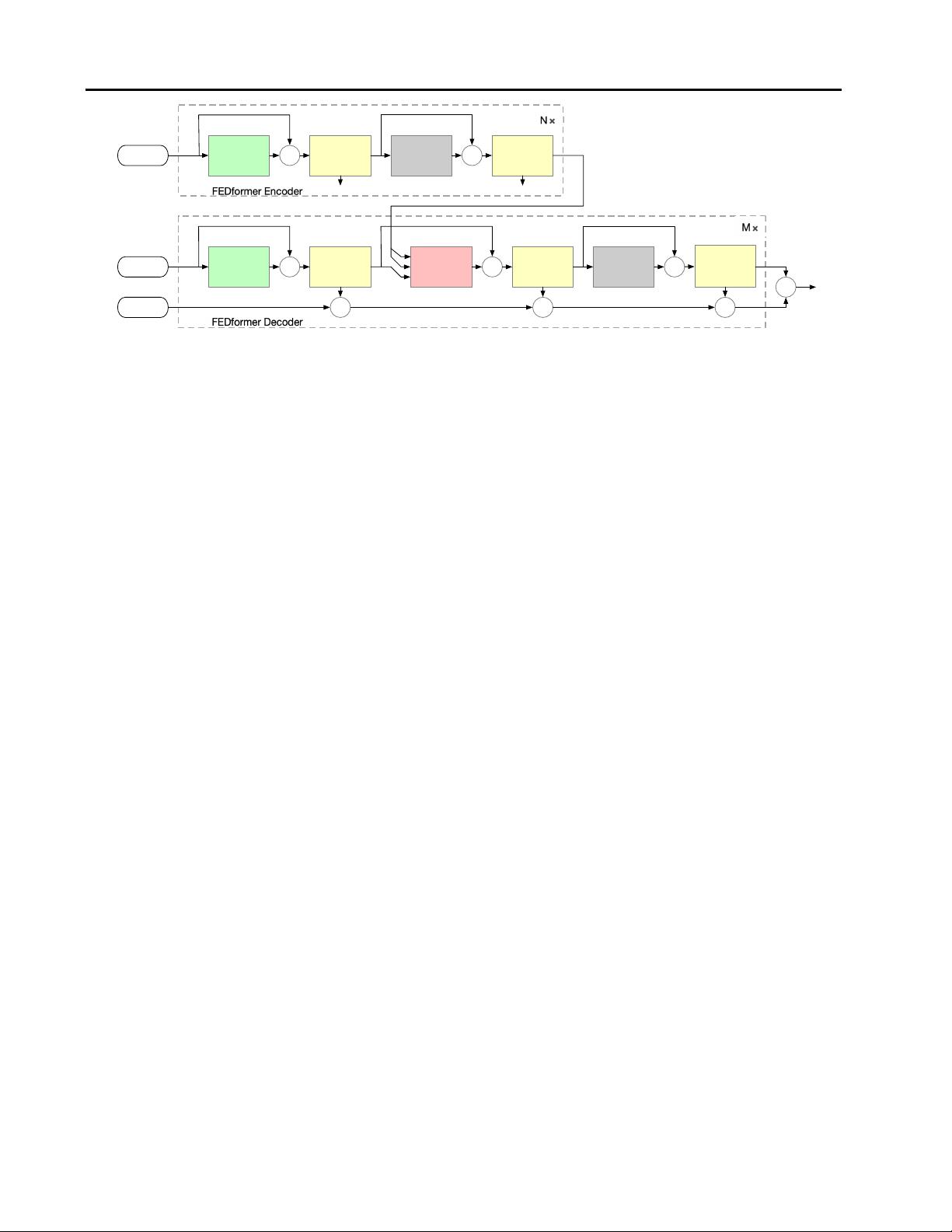

剩余18页未读,继续阅读
资源评论


Chase~711
- 粉丝: 0
- 资源: 1









最新资源
- 三维装箱问题(Three-Dimensional Bin Packing Problem,3D-BPP)是一个经典的组合优化问题
- 以下是一些关于Linux线程同步的基本概念和方法.txt
- 以下是一个简化的示例,它使用pygame库来模拟烟花动画的框架.txt
- Linux线程同步机制深度解析与实用指南.zip
- PTA题库C语言解题策略与实战.rar
- SVPWM控制技术的simulink建模与仿真【包括simulink模型,参考文献,操作步骤】
- AI高清修复图片画质易语言易语言源码易语言填表
- 映射窗口.ec易语言易语言模块CPU占用0%游戏监控窗口监控
- 易语言 361窗口模块高效、便捷、自封装、自用
- 易语言 窗口排列 模块 ,简单、高效、体积小
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


