PySpark数据分析和模型算法实战.pdf
需积分: 5 102 浏览量
2024-01-22
20:52:24
上传
评论
收藏 2.18MB PDF 举报

PySpark数据分析和模型算法实战
用 PySpark 构建客户流失模型实战项目
对于在高度竞争的市场中运营的公司来说,预测客户流失是一项关键的业务活动,因为消费者很容易取
消服务或更换供应商。许多研究发现,吸引新客户的成本远远高于保留现有客户的成本。识别有流失风
险的客户,可以让企业针对他们提供优惠和折扣,以及了解更广泛的产品/旅程改进机会。
1. 项目背景和目标
1.1 项目背景
这个项目是基于虚构的音乐流媒体公司 "Sparkify"。该公司在一个高度竞争的市场中运营,其商业模式
是基于广告和订阅。客户可以使用免费层级的服务,在那里他们会被播放广告,或者使用订阅计划,该
计划没有广告,但客户会被收取月费。
1.2 目标
这项研究的目的是建立一个模型,能够预测哪些客户的流失风险最大。对于这个项目,将把流失定义为
客户完全取消他们的订阅(在这个数据集中通过 "取消确认"来识别)。如果能在这些客户离开之前识别
出来,就可以为他们提供折扣/激励措施,让他们留下来。
任务
1. 探索性数据分析(EDA):评估缺失值,描述性统计,可视化数据,并创建一个流失率指标。
2. 特征工程:创建用户级别的记录,具有聚合特征。
3. 数据转换:创建一个管道来扩展+矢量化特征
4. 数据建模、评估+优化
5. 总结
数据
在这个项目中,将使用 sparkify_event_data.json 的一个迷你子集
( mini_sparkify_event_data.json )来分析数据,对数据进行整理和建模。该数据集包含一个有时
间戳的用户操作日志。
衡量标准
将使用F1分数作为主要指标来评估模型的性能。F1分数适合这个分类任务,因为它提供了一个精确性和
召回率的平衡,它可以处理不平衡的类别分布,即在这种情况下只有23%的客户流失。
2. 数据收集和准备
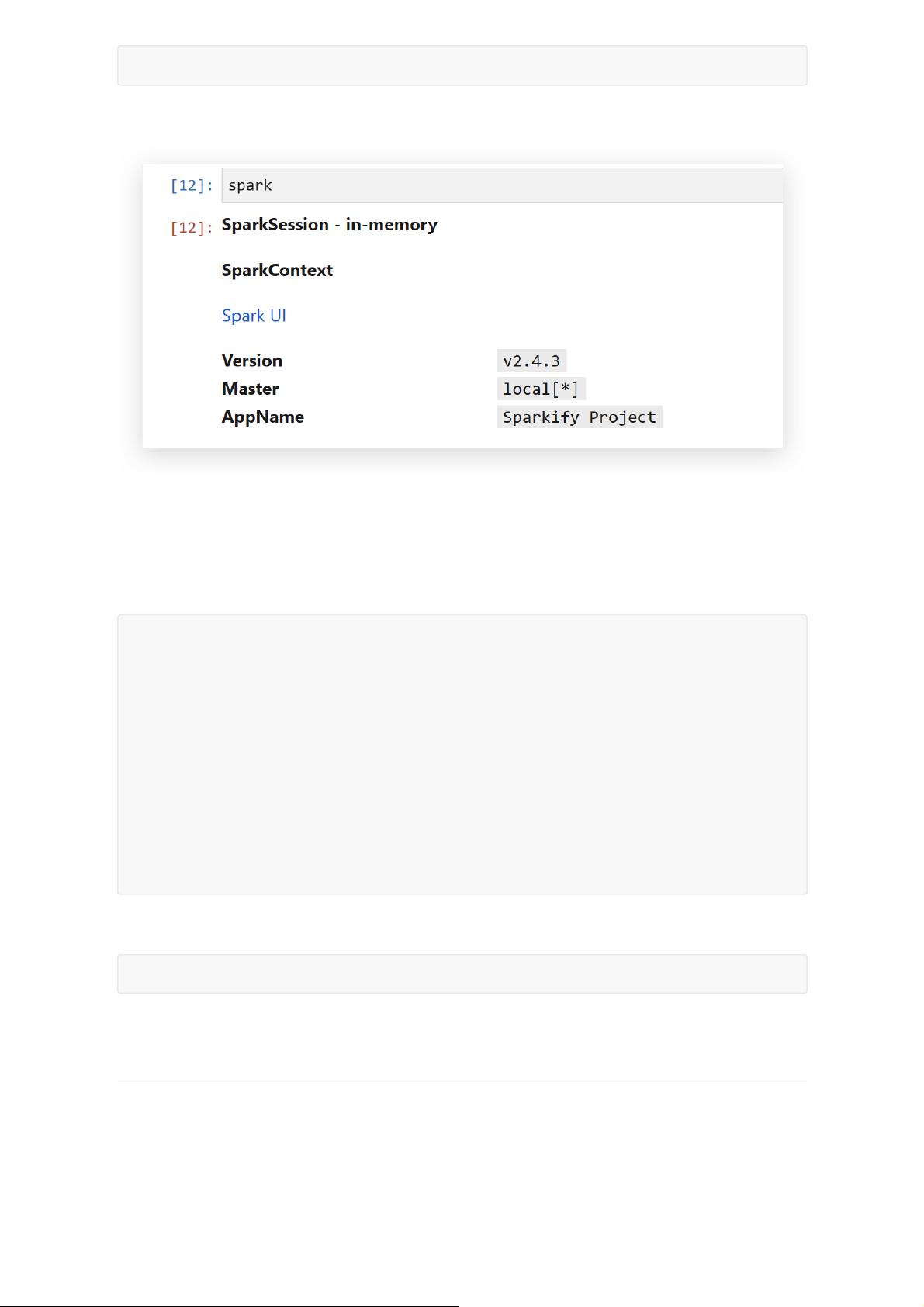
2.1 导入相关类库
安装依赖包:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy sklearn pandas
seaborn matplotlib


剩余38页未读,继续阅读
资源评论













