

博客 下载 学习 社区 知道 GitCode InsCode 会议
学习
搜索 登录 会员中⼼
登录后您可以享受以下权益:
https://blog.csdn.net/weixin_44791964/article/details/129941386 2024/7/28 02:34
⻚码 1/21

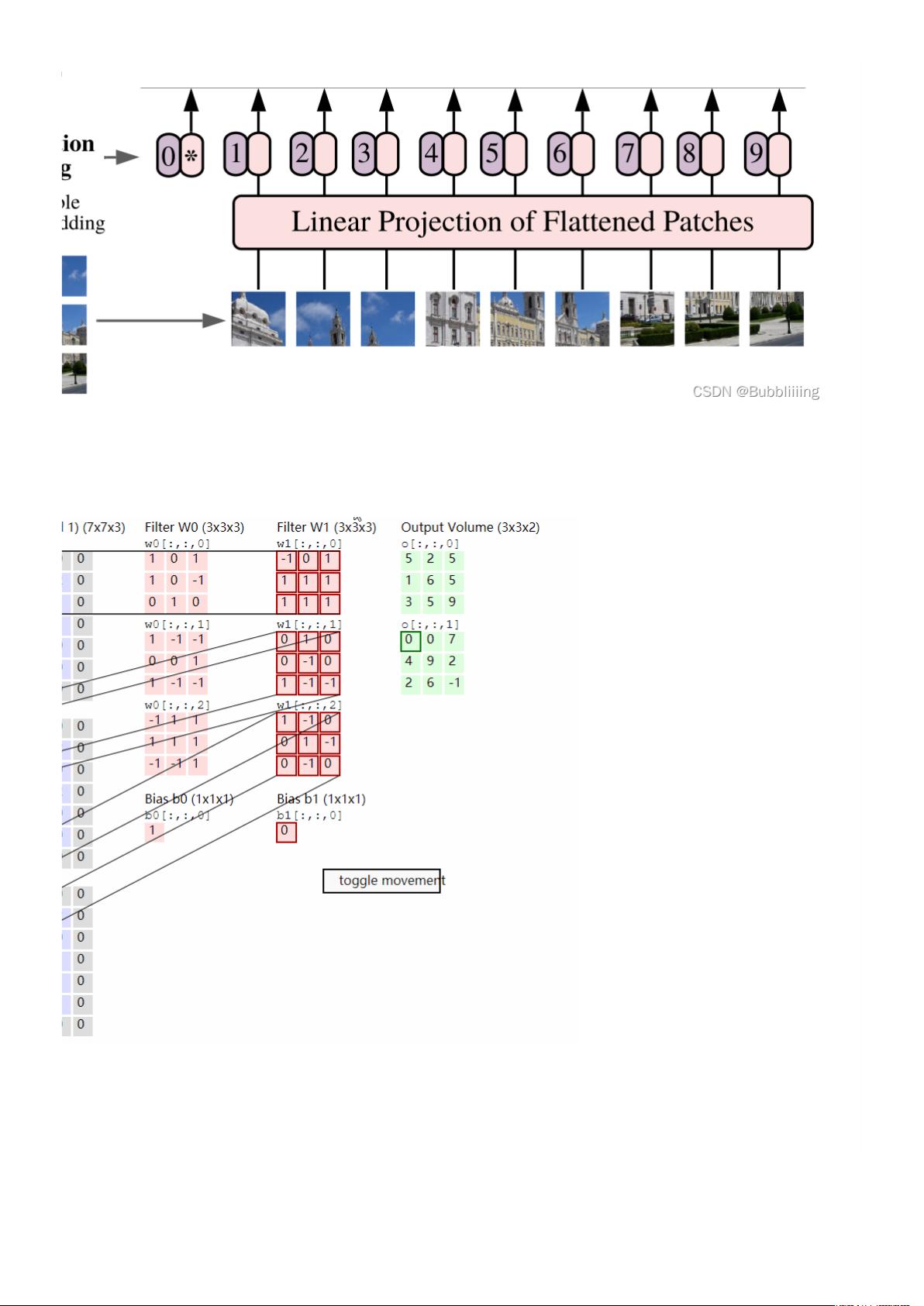

剩余20页未读,继续阅读
资源评论


刘伊诺
- 粉丝: 0
- 资源: 3









最新资源
- 基于STM32为电子香味项目,通过蓝牙模块传输数据,嵌入式硬件平台,RFID使用的是RC522.整个项目包括软硬件以及android程序详细文档+全部资料+高分项目+源码.zip
- 基于发布-订阅模型的多线程消息框架,用于嵌入式平台,纯C实现,性能和灵活性极高详细文档+全部资料+高分项目+源码.zip
- 基于嵌入式Linux的一套可视对讲设备代码,比较底层,写的比较好,里面的lib库是一些图像处理库详细文档+全部资料+高分项目+源码.zip
- php 实现各种排序和查找算法源代码.zip
- 基于嵌入式qt的车载系统详细文档+全部资料+高分项目+源码.zip
- 基于嵌入式的基础图形库详细文档+全部资料+高分项目+源码.zip
- 基于嵌入式平台ARM Linux的新冠肺炎疫情监控平台详细文档+全部资料+高分项目+源码.zip
- 基于嵌入式的视觉运动控制详细文档+全部资料+高分项目+源码.zip
- 基于嵌入式综合项目:STM32F407基于ARM Cortex-M4处理器,云服务器Linux操作系统,MySQL数据存储转发详细文档+全部资料+高分项目+源码
- 基于热风控制系统嵌入式项目,基于STM32F1芯片和RT-Thread实时系统开发出温度闭环控制和风速控制详细文档+全部资料+高分项目+源码.zip
- 基于全志V3S的嵌入式开发者打怪升级项目详细文档+全部资料+高分项目+源码.zip
- 基于事件型嵌入式驱动框架。详细文档+全部资料+高分项目+源码.zip
- 基于使用B-Tree作为索引,基于MMap的嵌入式键值数据库详细文档+全部资料+高分项目+源码.zip
- 基于三个嵌入式的小项目:一个是基于科大讯飞的语音识别系统,一个是智能音乐相册,一个是别踩白块小游戏详细文档+全部资料+高分项目+源码.zip
- 基于物联网模式开发的嵌入式程序详细文档+全部资料+高分项目+源码.zip
- 基于以太网通信的电力电子设备运行状态的远程监控嵌入式系统设计详细文档+全部资料+高分项目+源码.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


