
大数据之 hadoop 多节点集群搭建
1、多节点集群架构设计
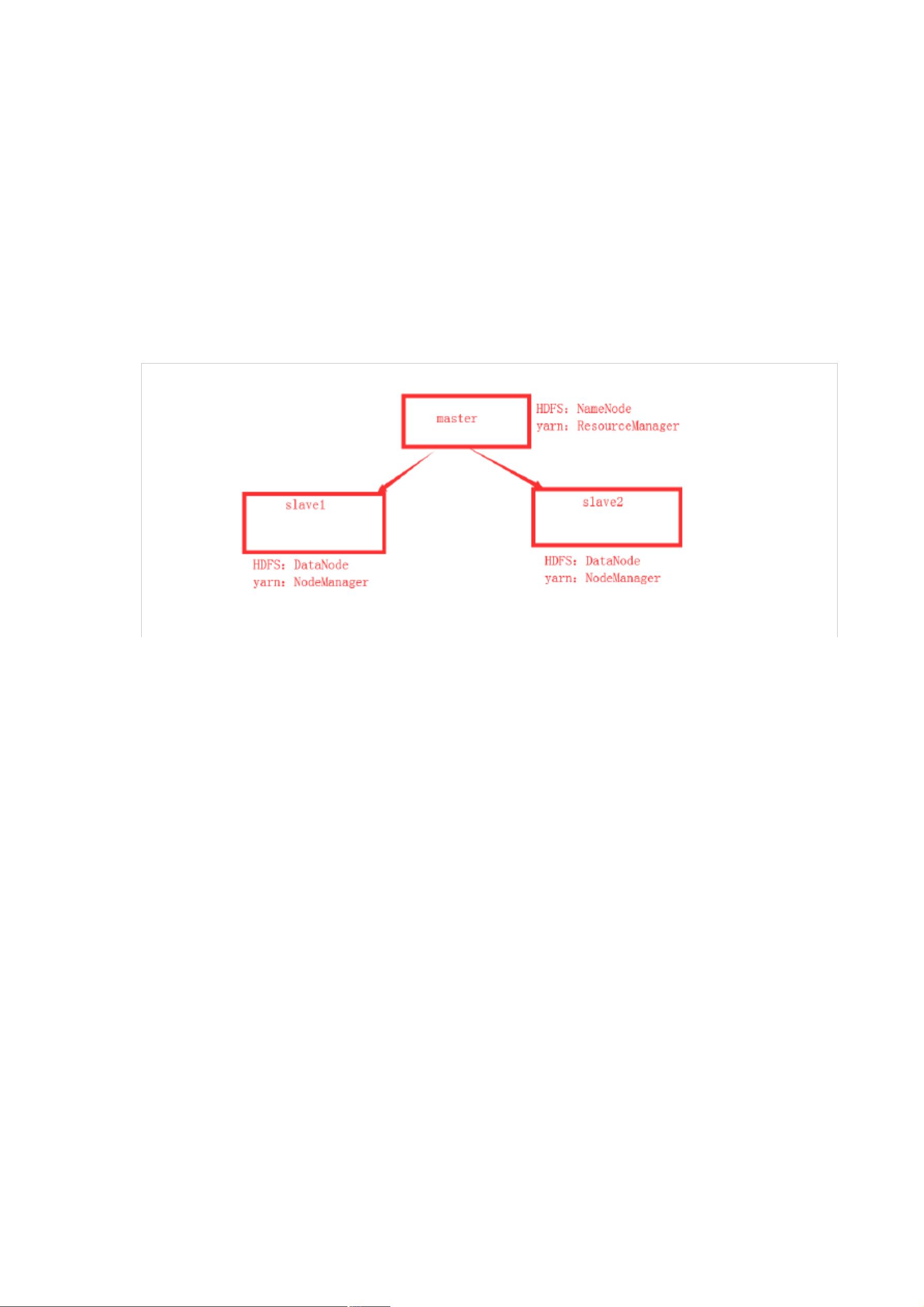
后续介绍的 hadoop 多节点集群由三台计算机构成:一台主节点为 master,两
台从节点为 slave1、slave2。
master 节点上主要运行 namenode、Resourcemanager 进程;slave 节点上运
行 datanode、nodemanager 进程。
由 于 大 家 一 般 只 有 一 台 计 算 机 , 因 此 我 们 使 用 虚 拟 机 软 件 VMware
workstation 虚拟出三台计算机来分别运行 master、slave1、slave2 节点。因为是
虚拟出的集群,所以跟实际的进群还是有差距的,不会体会到真正的并行计算与
并行存储的优势。实际工作中整个集群会有十几个甚至上百个节点,可以批量处
理以 T 为单位的数据。然而他们配置方法是大致相同的,运行过程也是一致的,
区别只是在运行速度和存储数据量上会体现出来。
为了简化安装过程,我们将在之前的伪分布集群基础上通过修改配置文件等
操作来创建 master 节点。
2、复制伪分布集群节点
首先需要复制之前安装配置过伪分布集群的虚拟机。具体操作步骤如下:
1)启动 VMware Workstation,选择 虚拟机->管理->克隆






评论0
最新资源