

开源 python 网络爬虫框架 Scrapy
介绍:
所 谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这种说法
不够专业,更专业的描述就是,抓取特定网站网页的 HTML 数据。不过由于一个
网站的 网页很多,而我们又不可能事先知道所有网页的 URL 地址,所以,如何
保证我们抓取到了网站的所有 HTML 页面就是一个有待考究的问题了。
一般的方法是,定义一个入口页面,然后一般一个页面会有其他页面的 URL,于
是从当前页面获取到这些 URL 加入到爬虫的抓取队列中,然后进入到新新页面后
再递归的进行上述的操作,其实说来就跟深度遍历或广度遍历一样。
上面介绍的只是爬虫的一些概念而非搜索引擎,实际上搜索引擎的话其系统是相
当复杂的,爬虫只是搜索引擎的一个子系统而已。下面介绍一个开源的爬虫框架
Scrapy。
一、概述
Scrapy 是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便,
并且官网上说已经在实际生产中在使用了,不过现在还没有 Release 版本,可
以直接使用他们的 Mercurial 仓库里抓取源码进行安装。
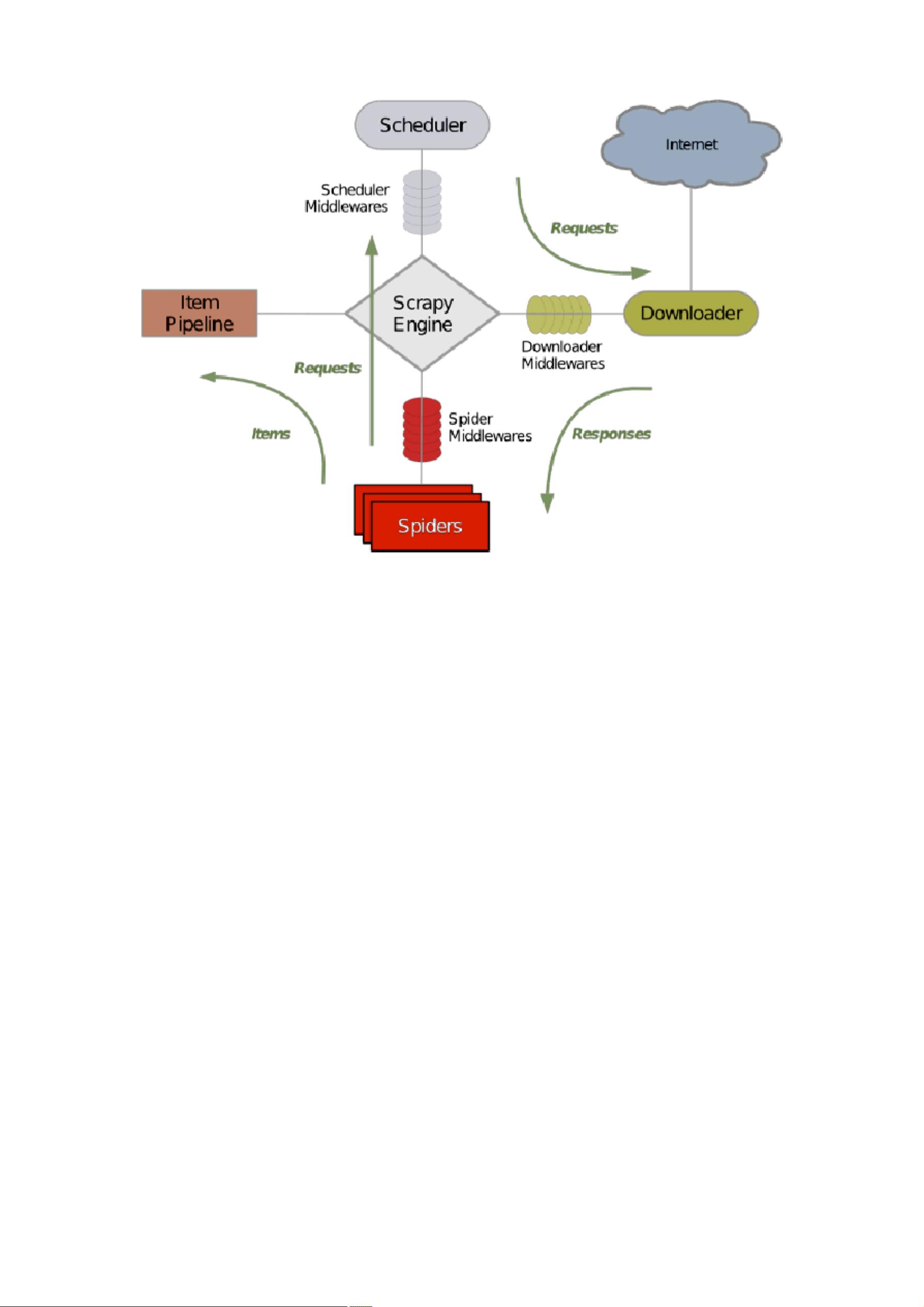
Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了
各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:

剩余10页未读,继续阅读
资源评论

 m0_741663112023-08-25这个资源内容超赞,对我来说很有价值,很实用,感谢大佬分享~
m0_741663112023-08-25这个资源内容超赞,对我来说很有价值,很实用,感谢大佬分享~

想要offer
- 粉丝: 4073
- 资源: 1万+









最新资源
- 机械手机器人含设计文档机械手-多用途气动机器人结构设计
- 如何在 Windows、macOS 和 Linux 上安装 Apache Maven?
- 基于java的奶茶店管理系统的开题报告.docx
- Java毕设项目:基于spring+mybatis+maven+mysql实现的农业视频实时发布管理系统农业新闻论坛【含源码+数据库】
- 基于java的汽车服务商城系统开题报告.docx
- 工具变量-上市公司环境治理费用.xlsx
- 基于java的失物招领信息交互平台的开题报告.docx
- 机械手机器人含设计文档机械手-发客户资料-搬运机械手设计
- Java毕设项目:基于spring+mybatis+maven+mysql实现的网上手机商城分前后台【含源码+数据库+毕业论文】
- 顶升移栽机sw18可编辑全套技术资料100%好用.zip
- 机械手机器人含设计文档机械手-高空作业机器人设计
- 顶升皮带辊筒sw20可编辑全套技术资料100%好用.zip
- Java毕设项目:基于spring+mybatis+maven+mysql实现的民宿管理系统分前后台【含源码+数据库+答辩PPT+毕业论文】
- 机械手机器人含设计文档机械手-工业机器人
- 返板升降机sw21可编辑全套技术资料100%好用.zip
- Java毕设项目:基于spring+mybatis+maven+mysql实现的舞蹈网站管理系统分前后台【含源码+数据库+答辩PPT+毕业论文】
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


