

-
..
固定效应模型的估计原理说明
在面板数据线性回归模型中,如果对于不同的截面或不同的时间序列,只是
模型的截距项是不同的,而模型的斜率系数是一样的,那么称此模型为固定效应
模型。固定效应模型分为三类:
1.个体固定效应模型
个体固定效应模型是对于不同的纵剖面时间序列〔个体〕只有截距项不同的
模型:
K
x u
y
(1)
it
i
k kit
it
k2
从时间和个体上看,面板数据回归模型的解释变量对被解释变量的边际影响
均是一样的,而且除模型的解释变量之外,影响被解释变量的其他所有〔未包括
在回归模型或不可观测的〕确定性变量的效应只是随个体变化而不随时间变化
时。
检验:采用无约束模型和有约束模型的回归残差平和之比构造 F 统计量,以
检验设定个体固定效应模型的合理性。F 模型的零假设:
H :
0
0
1
2
3
N 1
(RRSS URSS)
N 1
F
F(N 1,N(T 1) K 1)
URSS
(NT N K 1)
RRSS 是有约束模型〔即混合数据回归模型〕的残差平和,URSS 是无约束
模型 ANCOVA 估计的残差平和或者 LSDV 估计的残差平和。
实践:
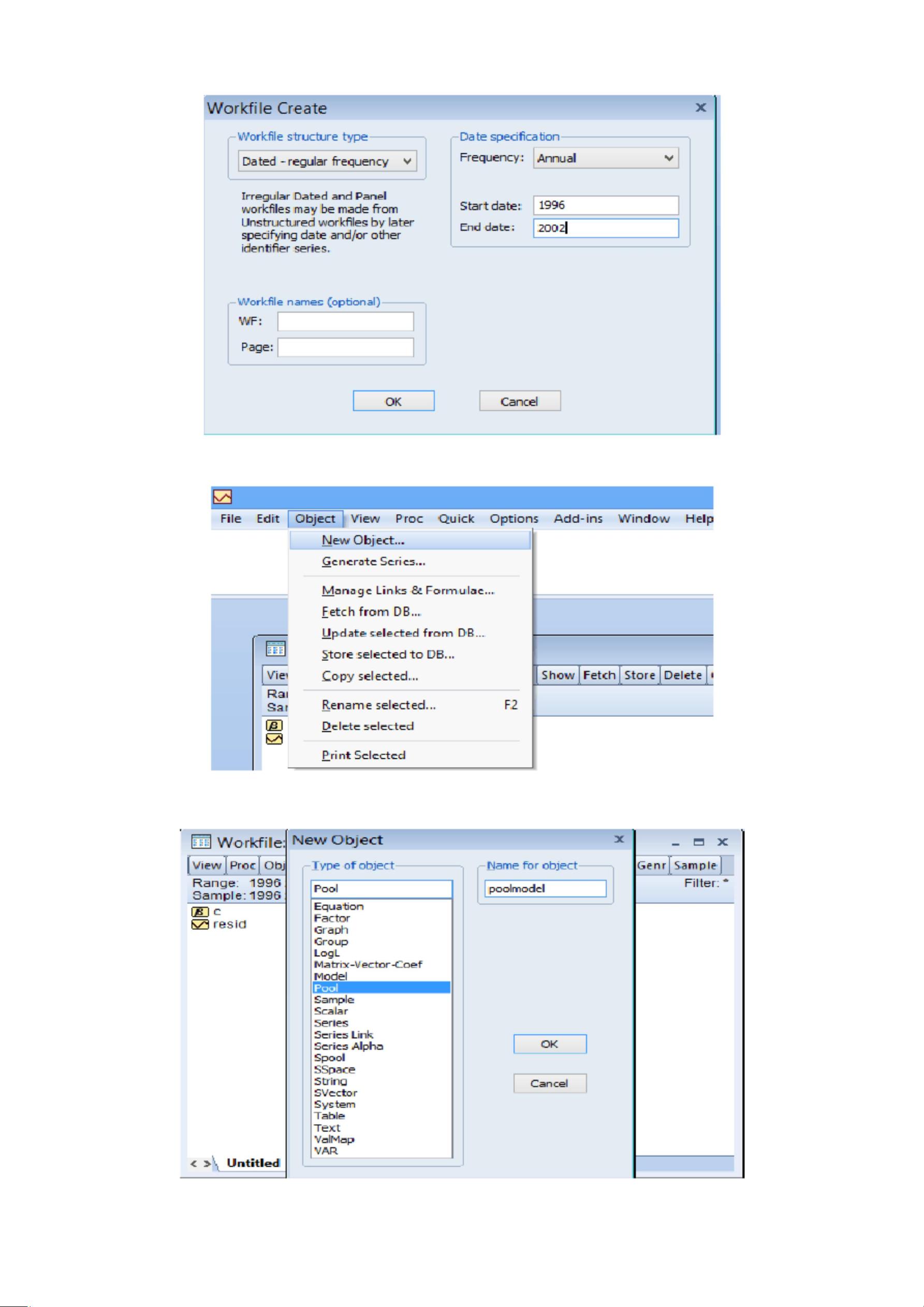
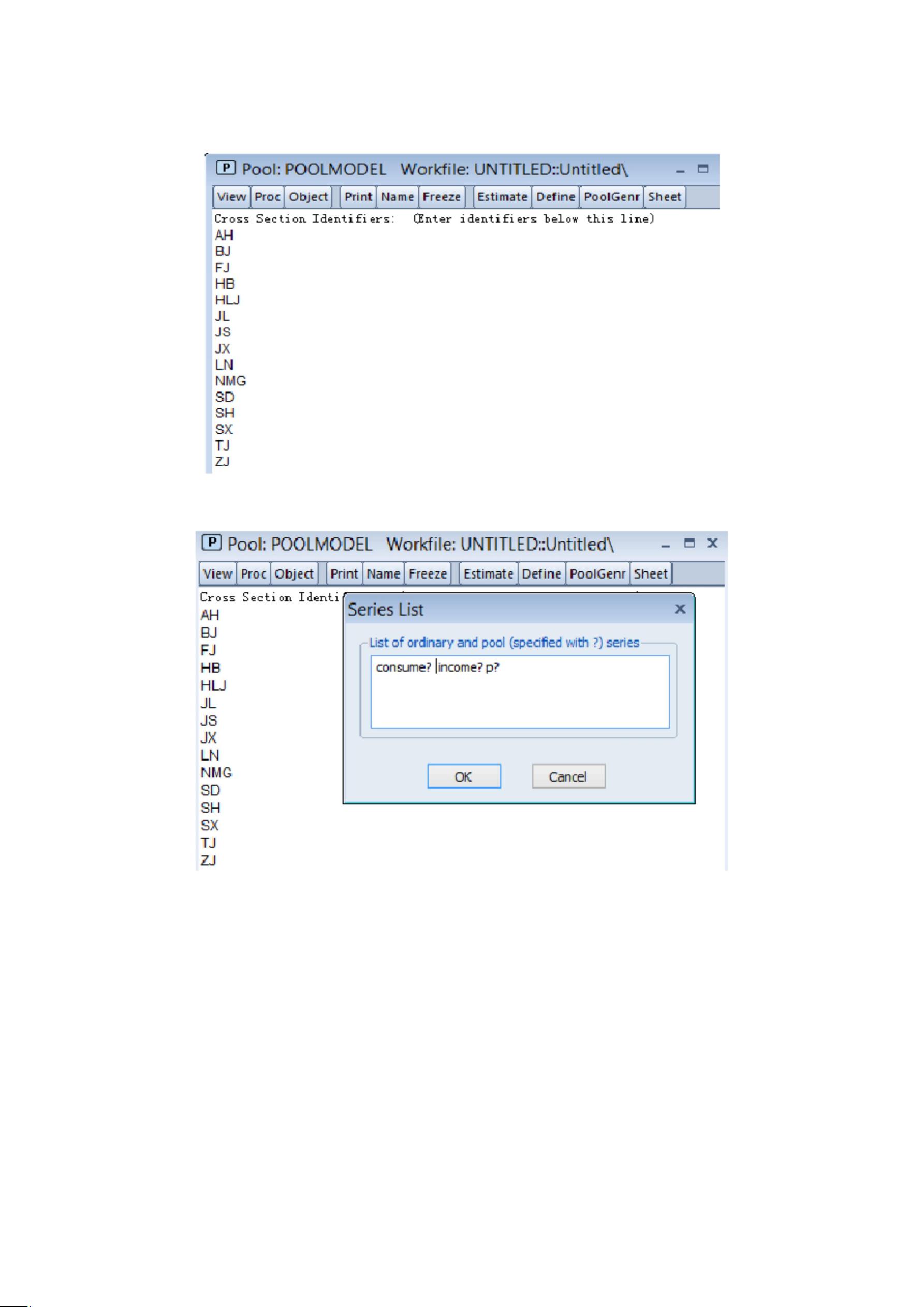
一、数据:1996—2002 年中国东北、华北、华东 15 个省级地区的居民家庭
人均消费〔 ,不变价格〕和人均收入〔
ip
,不变价格〕居民,利用数据〔1〕
cp
-
-可修编.
剩余28页未读,继续阅读
资源评论













