



2022/10/11 Flume 1.8.0 User Guide — Apache Flume
https://flume.apache.org/releases/content/1.8.0/FlumeUserGuide.html 1/55
Flume 1.8.0 User Guide ¶
Introduction
Overview
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log
data from many different sources to a centralized data store.
The use of Apache Flume is not only restricted to log data aggregation. Since data sources are customizable, Flume can be used to
transport massive quantities of event data including but not limited to network traffic data, social-media-generated data, email
messages and pretty much any data source possible.
Apache Flume is a top level project at the Apache Software Foundation.
There are currently two release code lines available, versions 0.9.x and 1.x.
Documentation for the 0.9.x track is available at the Flume 0.9.x User Guide.
This documentation applies to the 1.4.x track.
New and existing users are encouraged to use the 1.x releases so as to leverage the performance improvements and configuration
flexibilities available in the latest architecture.
System Requirements
1. Java Runtime Environment - Java 1.8 or later
2. Memory - Sufficient memory for configurations used by sources, channels or sinks
3. Disk Space - Sufficient disk space for configurations used by channels or sinks
4. Directory Permissions - Read/Write permissions for directories used by agent
Architecture
Data flow model
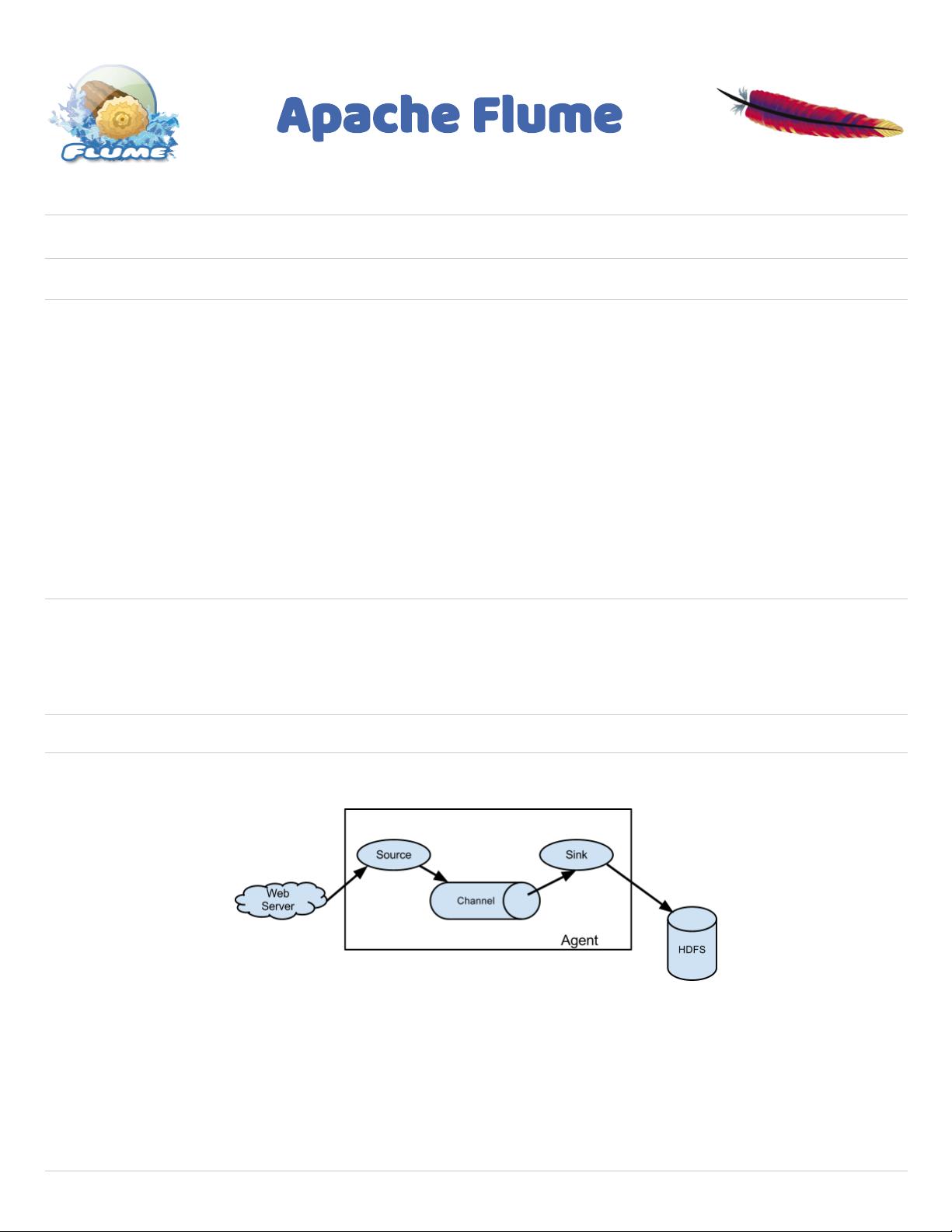
A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a
(JVM) process that hosts the components through which events flow from an external source to the next destination (hop).
A Flume source consumes events delivered to it by an external source like a web server. The external source sends events to Flume
in a format that is recognized by the target Flume source. For example, an Avro Flume source can be used to receive Avro events
from Avro clients or other Flume agents in the flow that send events from an Avro sink. A similar flow can be defined using a Thrift
Flume Source to receive events from a Thrift Sink or a Flume Thrift Rpc Client or Thrift clients written in any language generated
from the Flume thrift protocol.When a Flume source receives an event, it stores it into one or more channels. The channel is a
passive store that keeps the event until it’s consumed by a Flume sink. The file channel is one example – it is backed by the local
filesystem. The sink removes the event from the channel and puts it into an external repository like HDFS (via Flume HDFS sink) or
forwards it to the Flume source of the next Flume agent (next hop) in the flow. The source and sink within the given agent run
asynchronously with the events staged in the channel.
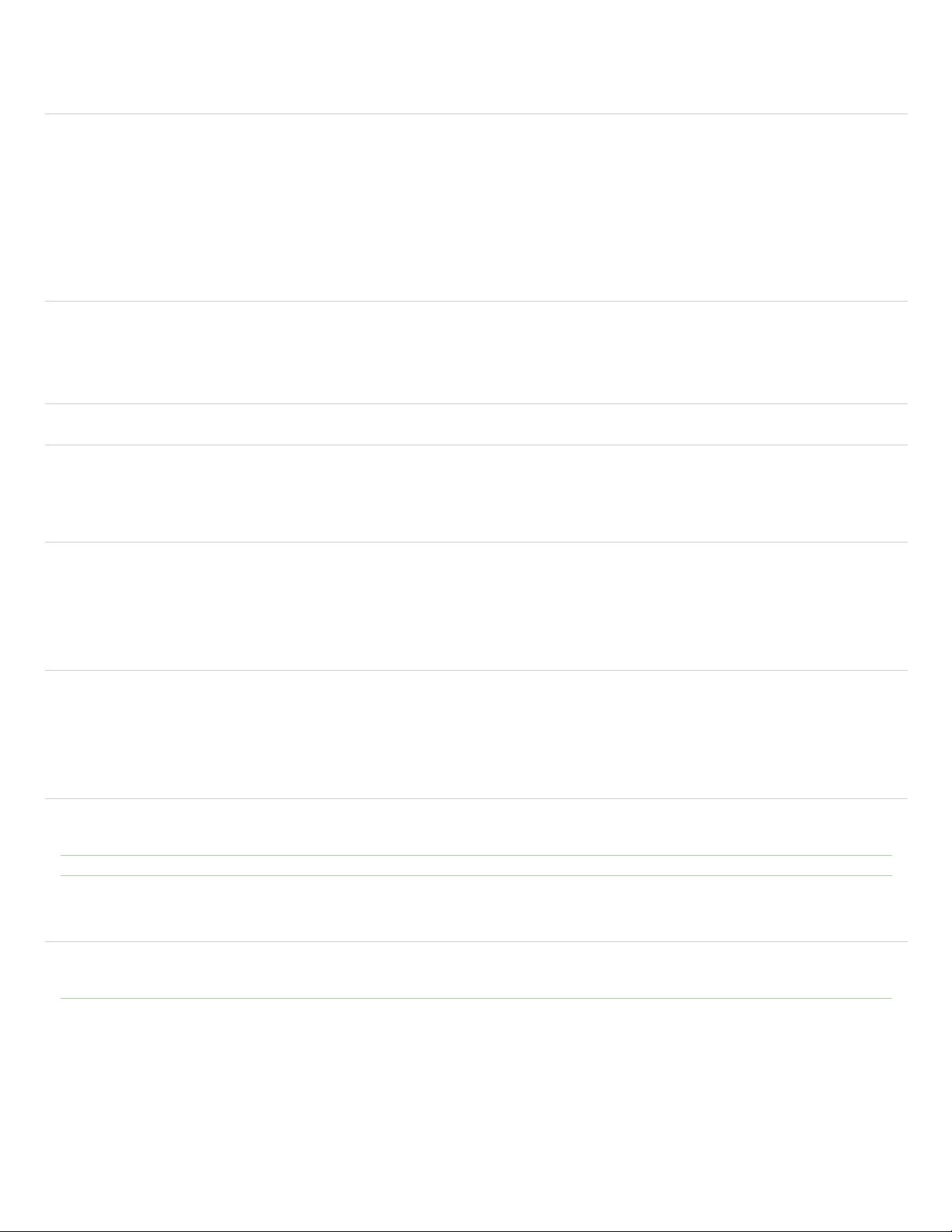
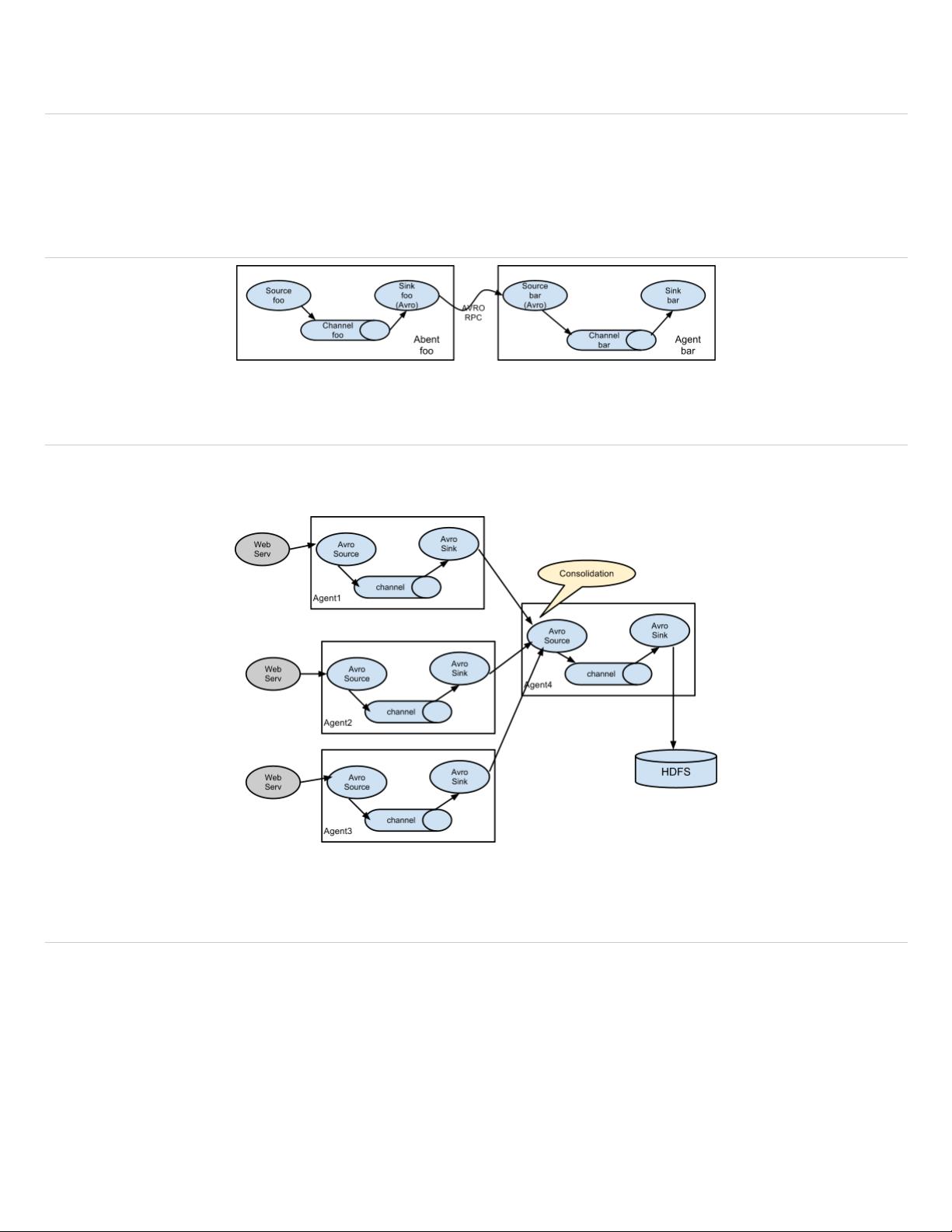
Complex flows
Apache Flume
™
™















评论0