基于HBase和Hive的芒果TV综艺弹幕数据分析
需积分: 0 164 浏览量
2022-12-10
20:05:52
上传
评论 7
收藏 5.63MB PDF 举报


1
基于
HBase
的芒果
TV
综艺弹幕数据分析
由于内存原因,本课题针对当前芒果 TV 综艺热搜榜 top5 中每个综艺的最新
一期前五分钟的弹幕进行数据分析。
1 项目设计目的
本项目涵盖 Linux、HDFS、MySQL、Sqoop、HBase、Hive、IntelliJ IDEA、
ECharts 等语言和工具的使用方法。通过本项目,可以学习到大数据生态系统的
综合运用。
通过实现此项目,可以达到如下目的:
①熟悉在 Linux 环境下将数据从本地上传到 HDFS 的过程
②了解 MySQL 建表等操作
③了解 Sqoop 的数据操作
④了解 HBase 创建表的过程
⑤了解 Hive 数据仓库的基本操作
⑥了解 ECharts 开发语言
⑦使用 EChars 编写可视化程序
2 技术简介
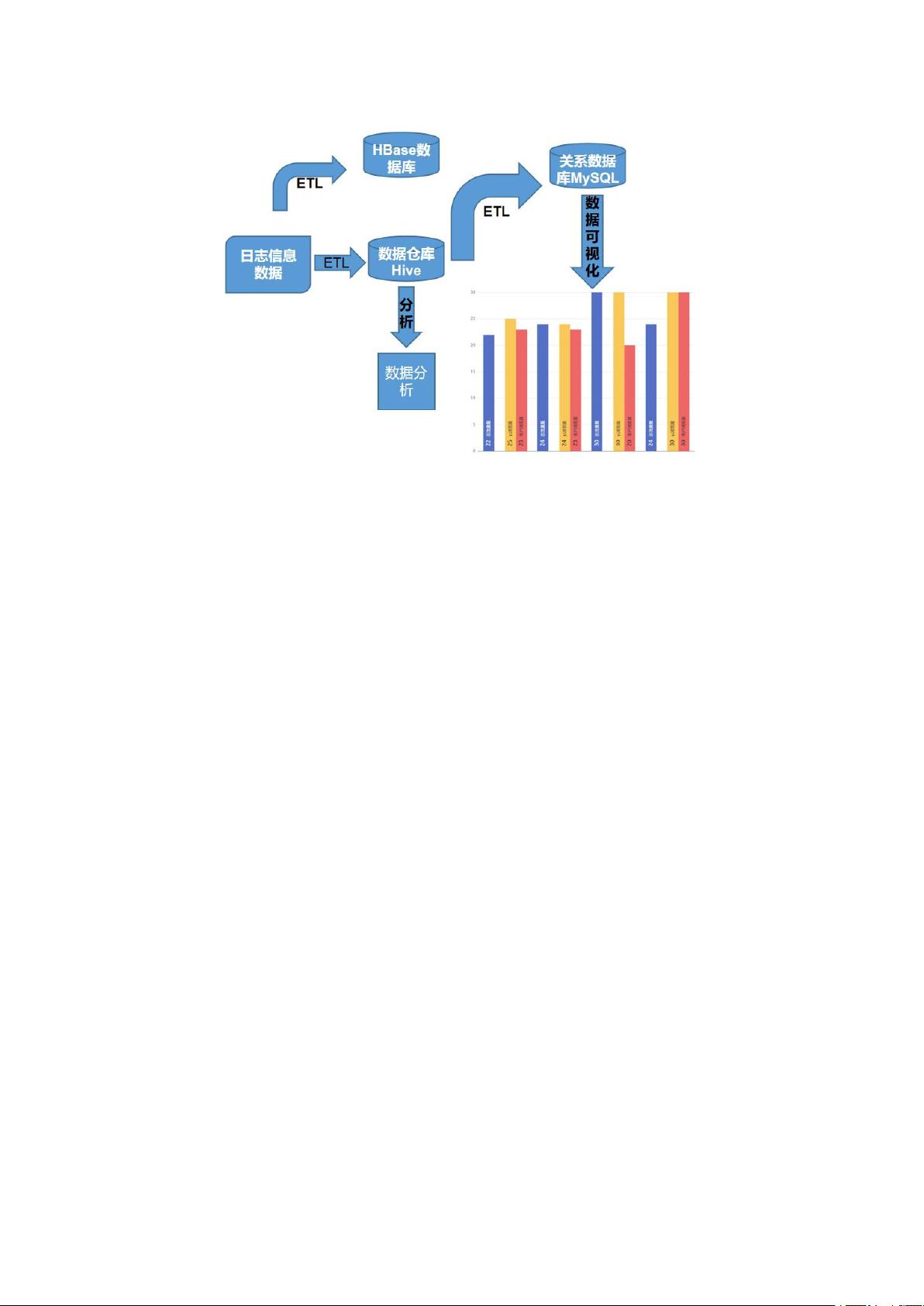
2.1 项目技术架构和组成
项目实现的功能是将收集到的数据上传到 HDFS 中,把明细数据保存到 HBase,
把数据存储到 Hive 中,之后再进一步使用 Hive 对数据进行分析,最后使用
Python 对数据进行可视化展示。此项目的技术组成包括:Linux 系统 CentOS、
MySQL、HDFS、Kettle、Hive、HBase、Sqoop、IDEA、Python、ECharts 等。


剩余25页未读,继续阅读
资源评论













