

摘要
针对传统恶意软件采用图像分类方法准确率不高、抗混淆能力弱、模型训练收敛慢的
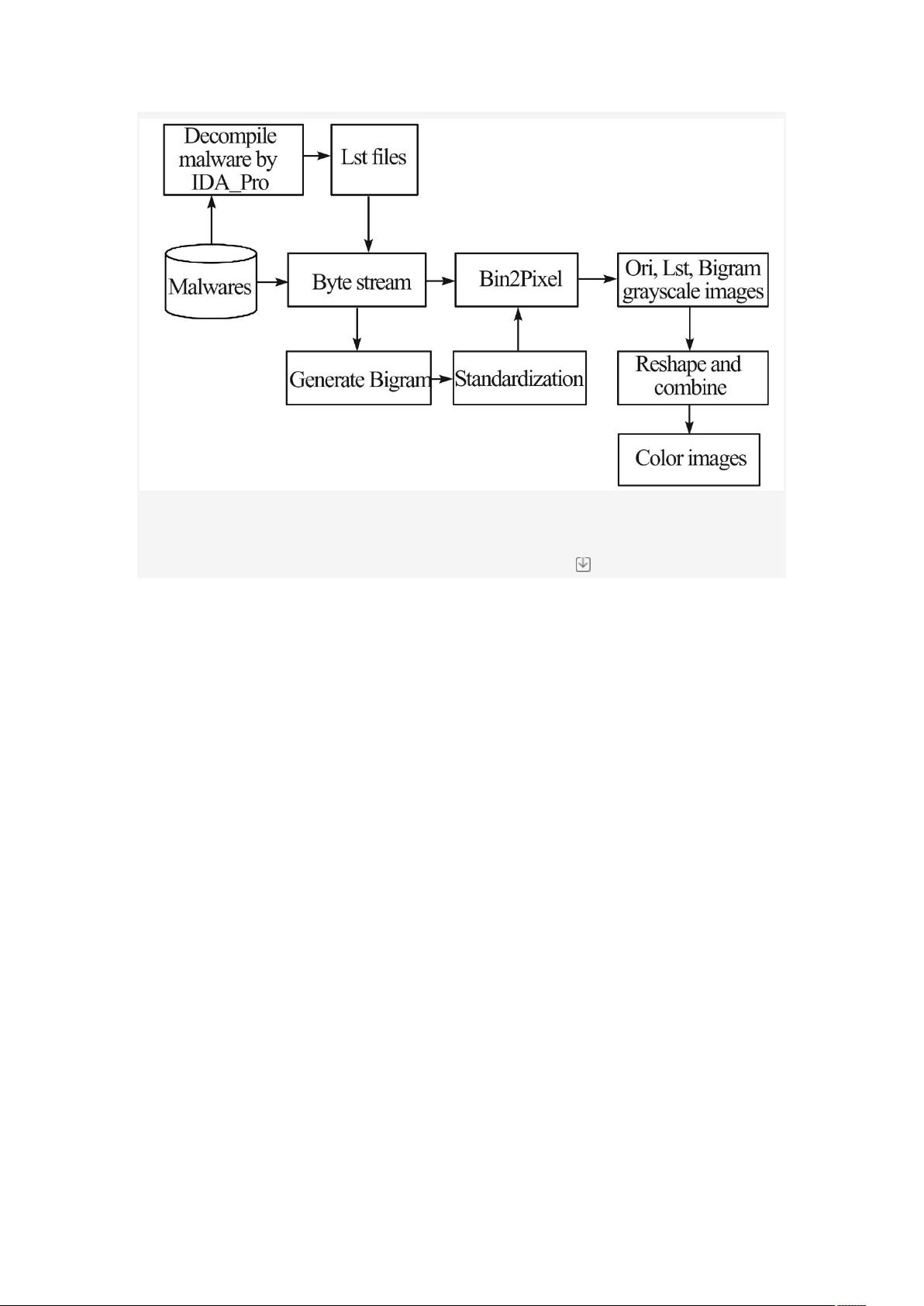
缺点,本文对恶意软件图像表示方法进行改进,将恶意软件、字节 Bigram、Lst 文件
转化成 3 种灰度图像,将 3 种灰度图像组合成三通道彩色图像进行分类,并将图像分
类效果好的 EfficientNet 模型用于恶意软件图像分类。结合迁移学习领域中的微调技
术将 ImageNet 数据集的分类权重应用于 EfficientNet,提高模型的收敛速度和分类
效果,减少模型的训练开销。实验表明在微调技术下模型收敛速度快于预训练,且微
调后的最优模型对 20 种恶意软件的分类准确率达到 97.22%。相比 ResNet、VGG16
等网络,本文的模型具有参数量和浮点运算次数少、准确率高的优点。
关键词
恶意软件; EfficientNet; ImageNet; 微调
0 引 言
近年来,互联网的发展极大地推动了国家和社会发展,但也产生了许多网络安全问题,
各种形式的网络犯罪频频发生,新型网络攻击方式和恶意软件呈指数级增长。根据国
家互联网应急中心发布的《2020 年中国互联网网络安全报告》
[ 1]
可知,2020 年捕
获的恶意程序总量超过 4 200 万个,涉及约 34.8 万个恶意程序家族,境内被攻击的
IP 数约占我国 IP 总数的 14.2%,约有 531 万台主机被境外的 5.2 万个左右恶意程
序服务器控制。恶意软件给国家和社会带来了极大的危害。
传统的恶意软件识别方法是通过签名来识别恶意软件的。但是该方法完全依赖于数据
库的容量,无法应对新型恶意软件。新型恶意软件通过简单的冗余代码插入,就能逃
避传统检测技术
[ 2,3]
。机器学习和深度学习的出现很好地解决了这类问题。这两种技
术能够自动学习已有特征中存在的模式,利用模式对未知特征进行预测。因此,国内
外许多研究专注于提高机器学习或者深度学习的模型性能和特征的有效性。
恶意软件分析方法主要可以分为静态方法、动态方法、动静混合方法。近年来,对恶
意软件的静态分析取得了很多成果。研究者们通过数据挖掘技术发现了恶意软件的许
多静态特征,如 PE(portable executable)特征,反编译文件中包含的段和 Opcode
特征,恶意软件的字节特征和灰度图像特征等。其中,恶意软件的灰度图像特征是一
种静态特征,自 2011 年提出后被广泛应用到恶意软件的各种研究中。2018 年,Fu
等
[ 4]
将 PE 文件中的段信息结合原始字节流生成恶意软件的 RGB 图像,然后提取 RGB
图 像 的 灰 阶 共 生 矩 阵 ( gray-level co-occurrence matrix ) 和 颜 色 矩 ( color
moments)作为恶意软件的全局纹理特征,再融合恶意软件的局部特征使用机器学
习算法对恶意软件进行分类。2019 年,任卓君等
[ 5]
提取恶意软件字节 Bigram,并
将字节 Bigram 转化成灰度图像,使用字节 Bigram 图像对 Kaggle 恶意软件数据集
的分类准确率达到 98.45%。孙博文等
[ 6]
提取恶意软件原始字节流、字符信息和样
本的 PE 信息,分别填充图像的 3 个通道生成恶意软件的 RGB 图像。王博等
[ 7]
提取

剩余16页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4409
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


