基于粒子群算法寻最优属性关联下的零样本语义自编码器.docx
版权申诉
171 浏览量
2023-02-23
20:12:23
上传
评论
收藏 652KB DOCX 举报


1. 引言
在图像分类任务中,为保证测试集与数据集类别相同,在每次增加新的图像类别时需
要对模型重新进行训练。从而,传统的图像识别方法在大量新类别出现时图像分类效果会
显著下降。为解决现实生活中海量类别的存在,使计算机具有知识迁移的能力,“零样本学
习”成为研究焦点
[1-4]
。基于属性的零样本分类是通过对不同类别之间的共享属性进行学
习,从而实现从训练类别到测试类别的迁移。在零样本发展的前期阶段,对属性的考察仅
仅停留在二值
[5]
层面,“1”表示具有该属性的性质,“0”则表示不具有。采用二值属性对于共
享属性层描述过于简单,从而使该模型对语义的理解存在偏差,因此相对属性(Relative
Attribute, RA)
[6]
这一概念被提出,并在零样本图像分类中取得了良好的分类效果
[7]
。相对属
性的属性值是连续的,其大小可以表示为样本具有该属性的相对强弱程度,从而提高了属
性信息的准确性。作为样本的另一种表示,属性携带的语义信息可以建立起已知类别与未
知类别的联系。鉴于深度神经网络的特征学习能力,将语义信息用于引导底层特征学习过
程,从而获得具有鉴别性信息的共享特征
[8,9]
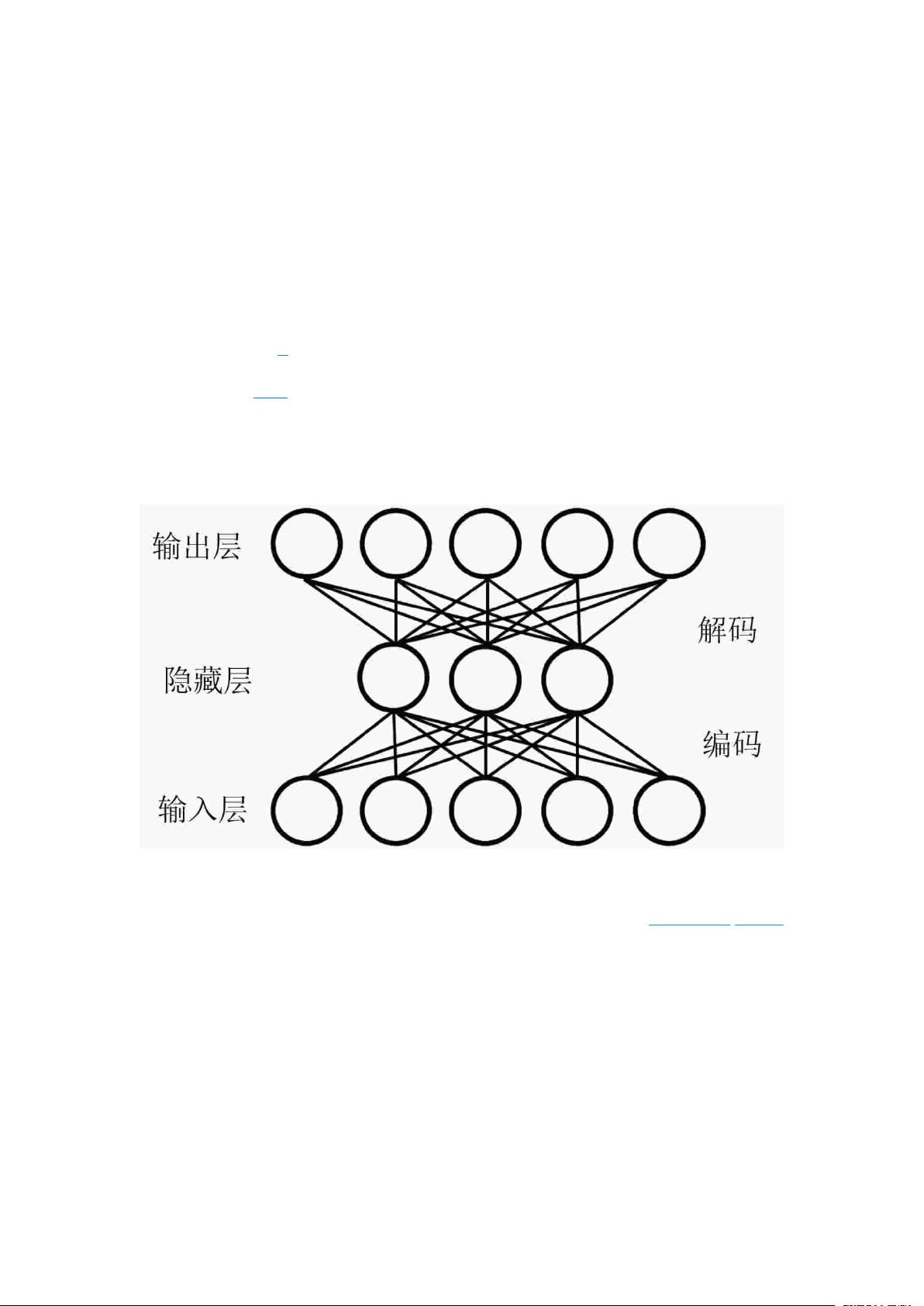
。语义自编码器(Semantic AutoEncoder,
SAE)
[10]
将属性作为隐藏层,实现了零样本图像底层特征到语义属性的映射,取得了突破性
进展。然而,从深度神经网络学习的图像底层特征中提取出的共享属性信息用作零样本分
类时,会使属性之间固有的相关性信息丢失,如何对丢失信息进一步补偿成为零样本图像
分类的重要研究内容。
在传统的属性学习
[11-13]
方法中,很少考虑到这些相关性信息并予以补偿。随着对零样
本学习研究的逐渐深入
[14-16]
,现有的属性相关性的研究证明了属性相关性的挖掘有利于属
性分类器性能的提高
[17-22]
。Liu 等人
[17]
采用属性相关性矩阵与原始共享属性进行运算从而
将相关性信息引入属性层。Wang 等人
[18]
利用互信息对属性间关系进行衡量。Biswas 等人
[19]
提出将语义属性相关性引入嵌入空间的跨越空间结构。Quercia 等人
[20]
发现,应该对不同
城市感知属性之间的相关性进行建模,以通过适当共享视觉知识来实现更有效和准确的相
对属性学习。Min 等人
[21]
提出了一种多任务深度相对属性学习网络,通过多任务连体网络
同时学习所有相对属性,解决了成对排名算法独立学习每个感知属性时造成的不同属性之
间的关系的丢失。通过将属性相关性向多维度扩展,Qiao 等人
[22]
研究了多个属性之间的相
关性,从而构造属性链,结果表明当属性链长为 2 时属性分类器性能达到最优。因此,本
文重点研究二元属性相关性,将属性相关性引入共享属性层中,以提升零样本图像分类时
的信息量和准确度。
本文提出一种自动寻找最优属性相关方法,弥补 SAE 在属性学习中缺少的属性相关
性信息,对属性进行相关性信息补偿。该方法将属性相关性求解转化为参数寻优,使用经
典启发式粒子群优化算法(Partial Swarm Optimization, PSO)寻找最优的嵌入属性相关性信息
的新属性。首先,学习属性与属性间的相关性,在原始的共享属性层中加入相关性变量。
考虑到参数与目标之间的单向可解性,利用 PSO 平衡原始属性与相关性变量间的关系。在

剩余11页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3552
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











