基于图卷积半监督学习的论文作者同名消歧方法研究.docx
版权申诉
184 浏览量
2023-02-23
20:06:24
上传
评论
收藏 443KB DOCX 举报


1. 引言
作者姓名歧义一直是国内外出版界和学术界的难点问题。近年来科学论文数量呈指数
级增长,重名现象越来越严重,特别是名称缩写、拼音一音多字等问题影响着文献检索系
统以及学术评价的准确性。为消除歧义,许多研究机构提出了人名标识系统以期通过唯一
标识来区分作者,如开放研究者与贡献者身份识别码(Open Researcher and Contributor
IDentifier, ORCID)
[1]
、Thomson Reuters 的 ResearchID
[2]
等。然而,人名标识系统的应用范
围有限,大量科学出版物中并未明确标注作者身份识别码。因此,通过自动化方法解决论
文中作者歧义问题仍然是同名消歧的主要手段,也是国内外学者的研究热点之一。常用的
作者消歧方法往往将问题转化为机器学习的聚类问题或分类问题,如利用 SVM
[3]
、层次聚
类
[4]
、谱聚类
[5]
等机器学习算法进行处理。随着深度学习技术的发展,越来越多研究人员采
用网络嵌入方法(Network Embedding)进行作者同名消歧
[6,7]
,从论文数据中抽取特征以便于
聚类或分类任务。此外,具有表征学习能力的卷积神经网络(Convolutional Neural Networks,
CNN)快速发展,在计算机视觉
[8,9]
、自然语言处理
[10]
等领域都取得了巨大成功,而图卷积
神经网络(Graph Convolutional Network, GCN)由于能够有效处理具有丰富关系结构的任务,
常用于处理图节点表示学习、图节点分类、边预测、图分类等问题
[11-14]
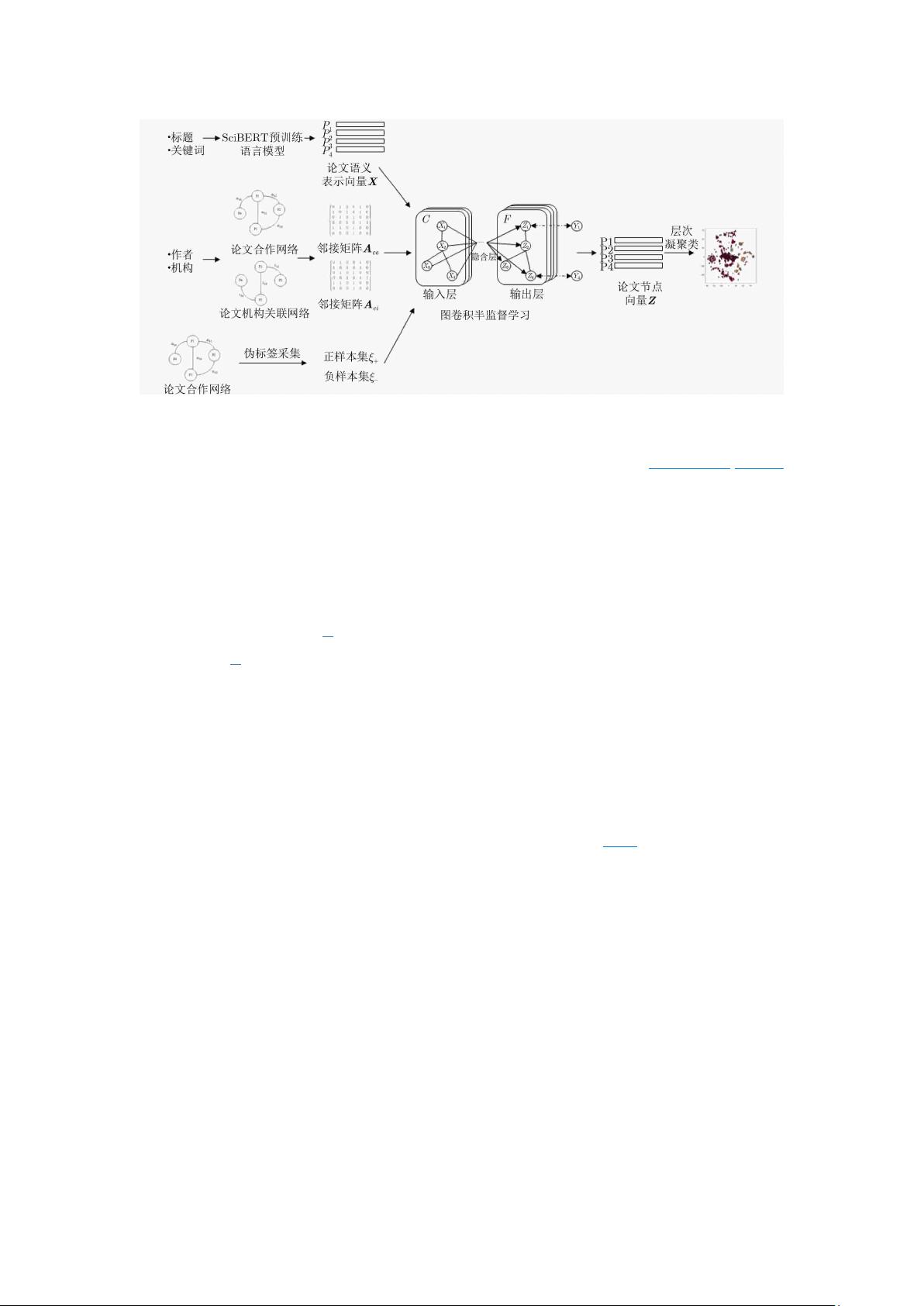
。鉴于此,本文提
出了一种基于图卷积半监督学习的论文作者同名消歧方法,融合作者、机构、题目、关键
词等论文属性信息,借助 BERT 语义表示方法和图卷积神经网络,探索作者消歧方法,以
提高作者与成果的匹配效果。
2. 相关研究
Zhang 等人
[6]
将当前同名消歧的研究方法分为两类:基于特征的消歧方法和基于连接/
图的消歧方法。
基于特征的消歧方法应用较早,根据文档的特征向量学习文档之间的距离函数,将相
近的特征向量归入相同类别,实现同名消歧。Huang 等人
[15]
提出了一个有效的综合框架来
解决名称消歧问题,分别利用 Blocking 技术检索具有相似名称作者的候选类,使用在线主
动选择支持向量机算法(LASVM)计算论文之间的距离度量进行 DBSCAN 聚类。Yoshida 等
人
[16]
提出一种基于 bootstrapping 的两阶段聚类算法来改善低查全率,其中第 1 阶段的聚类
结果用于提取第 2 阶段聚类中使用的特征。Han 等人
[3]
提出了基于 SVM 和贝叶斯网络的有
监督消歧方法,利用论文合作者、题目出版物名称等特征对同名作者进行消歧。Zhu 等人
[17]
使用多层聚类的方式进行同名消歧,如分别利用 Email 信息、论文合作者、论文题目等
进行动态的作者聚类。

剩余14页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3691
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











