基于多重多尺度熵的孤独症静息态脑电信号分析.docx
版权申诉
49 浏览量
2023-02-23
16:53:50
上传
评论
收藏 452KB DOCX 举报


孤独症(又称自闭症)是一种广泛性大脑发育障碍, 患者存在严重的沟通障碍
[1]
, 特点是
具有高发病率和遗传率, 其中男性发病率比女性高 2~3 倍
[2]
.
孤独症病因目前尚无明确结论, 但有研究表明:孤独症的病因与脑结构状态改变和脑功
能障碍有关, 这种改变或连接异常可以通过脑电信号分析进一步挖掘
[3]
.静息态脑电信号反
映大脑在没有任何外界刺激和任务活动时的状态, 因此, 对于年龄较小、认知水平和任务配
合程度低的孤独症儿童, 基于静息态脑电信号分析脑功能状态更可行、更具优势. 2005 年,
Sutton 等
[4]
研究发现, 与正常儿童相比, 孤独症儿童的静息态脑电 Alpha 频段在前额区的能
量降低, 而顶区和中央区的能量升高. Sheikhani 等
[5]
通过研究静息态脑电发现, 孤独症儿童
颞区(T 区) Gamma 频段的脑电信号相干性显著升高.
基于脑电信号分析孤独症儿童脑功能状态, 目前主要集中在大脑复杂程度评估和脑功
能网络结构研究两个方面, 熵是衡量大脑复杂程度和研究脑功能网络的重要特征参数, 单个
离散随机变量的熵是其平均不确定性的量度, 它表征了随机变量的随机性程度, 基于熵参
数, 可以很好地表征一个复杂性系统的有序性变化, 可以评估系统的状态, 更加可以进一步
指出系统的发展趋势. Fan 等
[6]
在总结了熵在脑功能状态研究现状的基础上, 提出了一种评
估脑功能状态的网络特征熵算法, 结果表明人类的脑功能状态可以通过熵值的变化来评估.
Song 等
[7]
基于脑电信号样本熵、优化样本熵等特征参量, 分析癫痫脑电信号, 得到了较好的
结果.小波熵、排列熵、谱熵等也广泛应用于脑电信号分析
[8]
. 2016 年, 雷敏等
[9-10]
利用样本
熵和辛熵分析孤独症和健康人的脑电信号, 得出孤独症脑电信号样本熵明显低于健康人的
熵值, 熵参数可以作为分析孤独症脑功能状态的参数指标.但是, 传统的熵算法很难表征脑
电信号的多尺度特点, 从而很难进一步挖掘信号中隐藏的细节信息.
多尺度熵算法可以通过在多个尺度上构造原始信号的新序列, 从而达到分析信号在不
同时间尺度上时域复杂性的目的. Bornas 等
[11]
和 Thuraisingham 等
[12]
也证明了在反映脑电信
号特征方面, 多尺度熵能够提取到更多的信息. Zavala-Yoé 等
[13]
以多尺度熵作为特征量, 有
效地识别了癫痫发作的脑电信息. Mclntosh 等
[14]
证实了正常人比孤独症具有更好的适应性与
更高的多尺度熵值. Bosl 等
[15]
和 Catarino 等
[16]
利用多尺度熵分析孤独症和健康人的脑电信
号, 指出孤独症患者的脑电复杂度存在显著性降低.以上结果表明, 多尺度熵方法能够更好
地挖掘信号隐藏的细节信息.
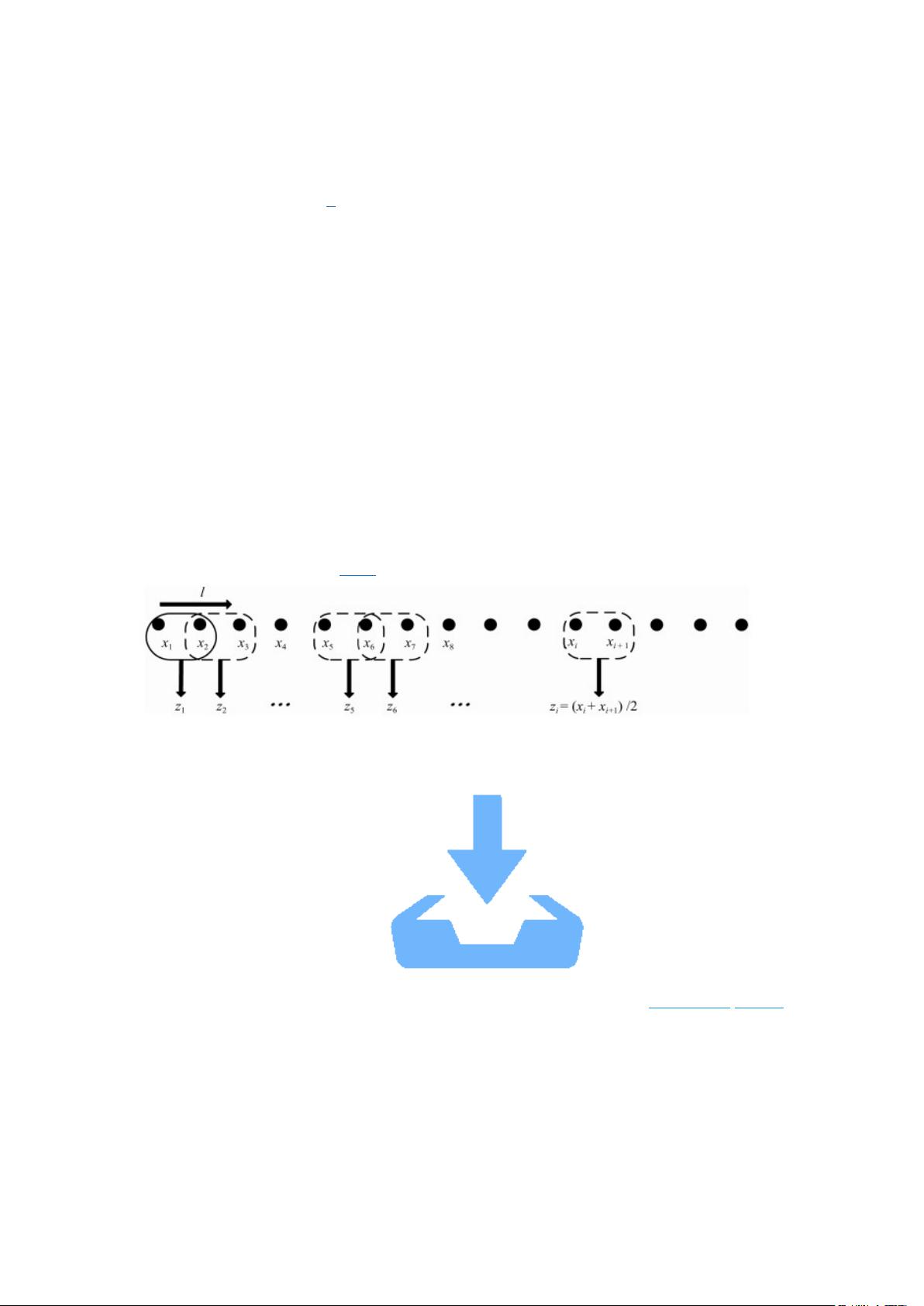
但是, 计算原始数据多尺度熵时,在多尺度粗粒化过程中, 不可避免地会造成数据原
始信息丢失, 从而导致重要的特征信息丢失.针对这一问题, 本文提出一种多重多尺度熵脑
电特征提取算法.算法基于时间序列产生新模式概率理论, 在移动均值粗粒化基础上, 采用
延搁取值法, 构建多个尺度的多重脑电信号序列, 进一步计算各尺度的熵值.基于该算法并
结合复杂度算法, 对比分析了 16 名孤独症儿童和 16 名正常儿童脑电信号特征, 得到了孤独
症儿童敏感脑区与相关敏感通道.
1. 多重多尺度熵

剩余15页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3552
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











