基于自适应级联的注意力网络的超分辨率重建.docx
版权申诉
69 浏览量
2023-02-23
16:51:59
上传
评论
收藏 2.61MB DOCX 举报


单图像超分辨率(Single image super-resolution, SISR)
[1]
技术是一个经典的计算机视觉任
务, 旨在从一个低分辨率(Low-resolution, LR)图像生成对应的高分辨率(High-resolution, HR)
图像, 在医学成像、监控和遥感等领域有十分广泛的应用. SISR 是一个病态的逆问题, 要重
建逼真的 HR 图像非常困难, 因为一个 LR 图像可与多个 HR 图像对应, 需要假定的先验知
识, 正则化原 HR 图像解
[2]
.
近年来, 深度学习
[3]
技术显著改进了 SISR 性能, 并主导了当前 SISR 技术的研究. Dong
等
[4]
提出了第 1 个基于卷积神经网络的 SISR 算法称为超分辨率卷积神经网络(Super-
resolution convolutional neural network, SRCNN). SRCNN 只有 3 个卷积层, 感受野较小. 之
后的 SISR 方法的一个趋势是: 逐步加深网络, 从而获得更强的 LR-HR 映射能力, 同时拥有
更大的感受野, 能够融入更多的背景信息, 改进了 SISR 性能
[5]
. 然而加深网络也会带来一些
问题: 更大的网络(更深或更宽), 会有更多的参数, 需要更大的内存和更强的计算力, 这阻
碍了在资源受限的设备, 如移动设备上的实际应用. 当前已有一些引人注意的基于轻量级网
络的 SISR 方法被提出. Kim 等
[6]
提出的深度递归卷积网络(Deeply-recursive convolutional
network, DRCN)方法, 使用深度递归的方法, 在卷积层之间共享参数, 在加深网络的同时,
尽可能不增加网络参数量. Tai 等
[7]
提出的深度递归残差网络 (Deep recursive residual
network, DRRN), 也使用了深度递归的方法. 与 DRCN 的区别在于 DRRN 在残差块之间共
享参数, 不仅显著地减少了参数量, 而且性能也显著更好. Tai 等
[8]
也提出了深度持续记忆网
络(Deep persistent memory network, MemNet)方法, 使用记忆模块, 并多次递归, 既能控制参
数量, 也能更好地利用多层特征信息. Ahn 等
[9]
提出的级联残差网络(Cascading residual
network, CARN)方法, 使用级联残差的形式, 重用不同层次的信息. Li 等
[5]
提出的轻量级超
分辨率反馈网络 (Lightweight super-resolution feedback network, SRFBN-S)方法, 使用循环神
经网络结构, 共享隐藏层的参数, 并多次利用各个隐藏层的输出, 从而改进了网络性能.
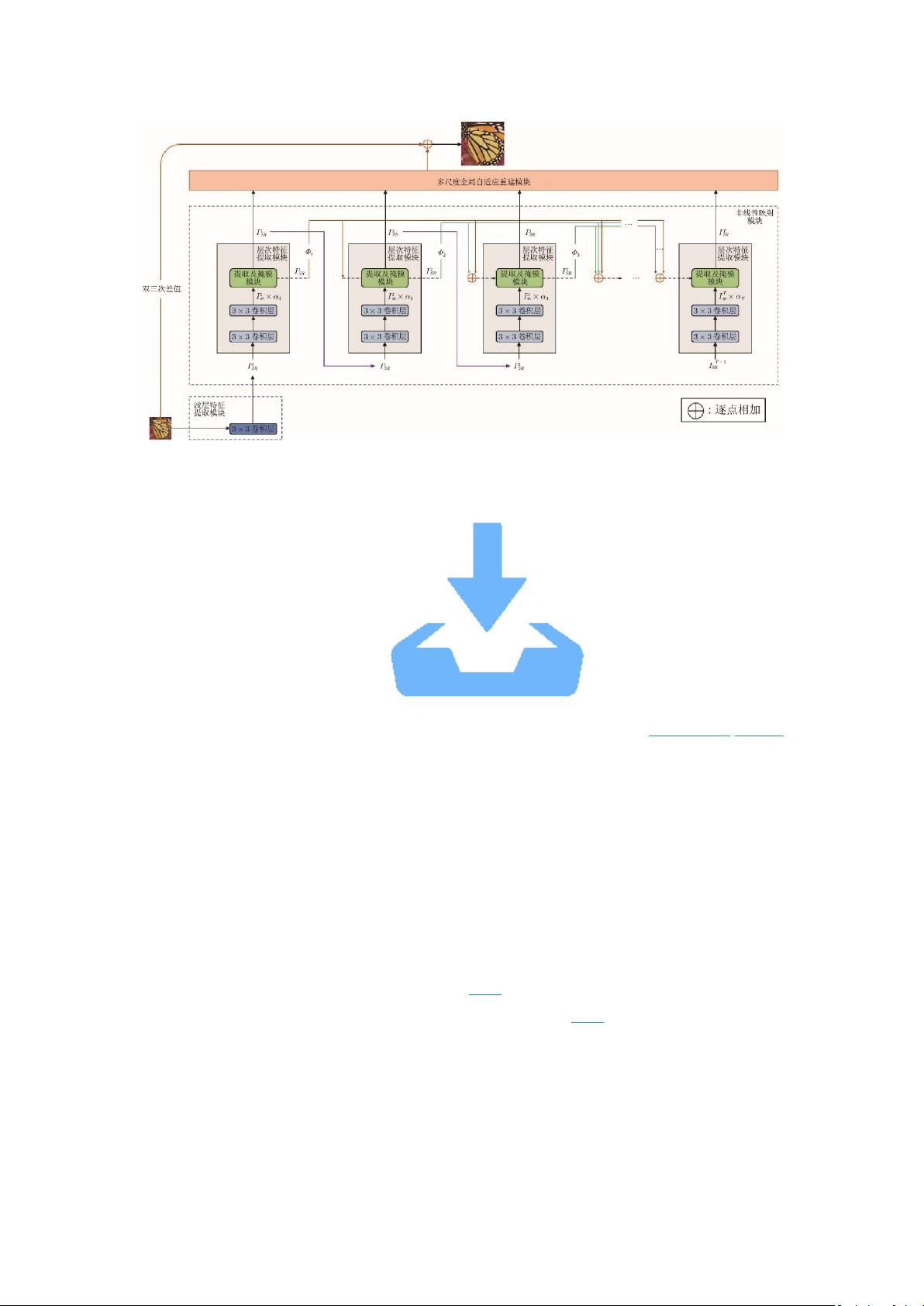
本文提出了一个新的轻量级 SISR 模型, 称为自适应级联的注意力网络(Adaptive
cascading attention network, ACAN). 与当前类似的尖端 SISR 方法相比, ACAN 有更好的性
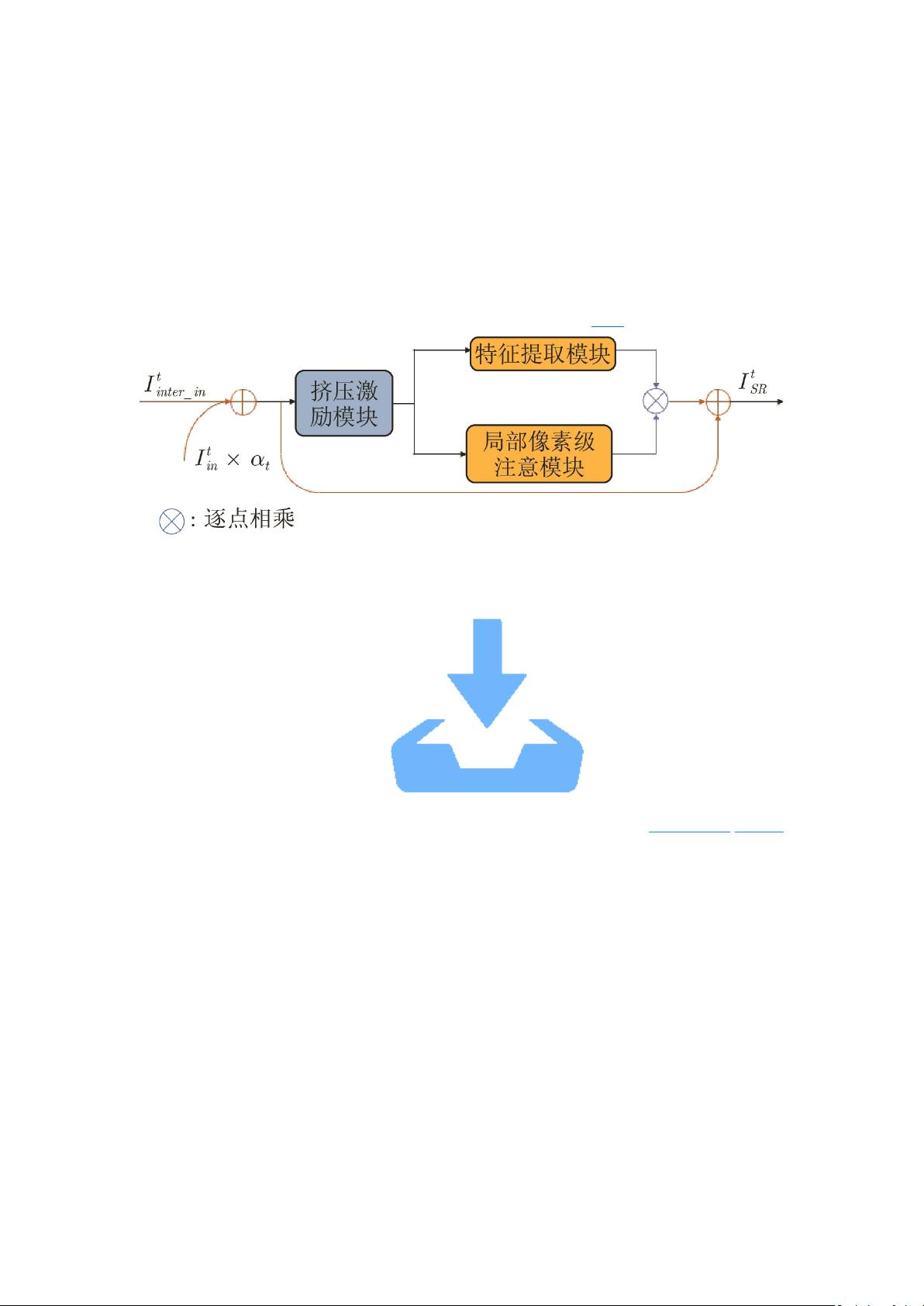
能和参数量平衡. 的主要贡献包括: 1)提出了自适应级联的残差(Adaptive cascading residual,
ACR) 连接. 残差块之间的连接权重, 是在训练中学习的, 能够自适应结合不同层次的特征
信息, 以利于特征重用. 2)提出了局部像素级注意力(Local pixel-wise attention, LPA)模块. 其
对输入特征的每一个特征通道的空间位置赋予不同的权重, 以关注更重要的特征信息, 更好
地重建高频信息. 3)提出了多尺度全局自适应重建(Multi-scale global adaptive reconstruction,
MGAR)模块, 不同尺寸的卷积核处理不同层次的特征信息, 并自适应地组合处理结果, 以
产生更好的重建图像.
1. 相关工作
1.1 注意力机制

剩余20页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3563
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











