

移动自组织网络(mobile Ad hoc networks, MANET)是由移动节点组成复杂分布式系
统。移动节点可以自由和动态地自组织成临时网络拓扑结构来传输每个节点收集到的信
息。MANET 的特点是有限的存储资源、处理能力以及高度移动性。在网络中,移动节点
可以动态地加入或离开网络,导致了频繁和难以预测的拓扑改变,加重了网络任务的复杂
程度,降低了网络通信质量。由于网络拓扑结构的不断变化
[1-2]
,无线链路在高速移动环境
中经常发生断裂,如何保持通信链路的持续性成为一个巨大挑战。因此,在临时网络拓扑
结构信息交互过程中选择稳定联接链路节点进行传输对于链路联接的持续性有重要意义。
为了增强网络的性能因素,目前最有效方法是通过节点的移动特性来预测网络中链路
联接的稳定性程度和网络拓扑结构。文献[3]提出了基于自适应神经模糊系统来预测节点的
运动轨迹,根据预测得到的轨迹来选择链路节点进行传输。文献[1]通过收集节点的接收信
号强度指示(received signal strength indication, RSSI),将其进行深度学习训练,预测节点的
运动轨迹。文献[4-5]通过深度学习或机器学习方法对节点的位置进行预测或进行链路质量
预测来选择最短可靠路径进行信息传输。文献[6]提出一种基于接收信号强度选择稳定路径
的方法,根据一段时间内节点接收信号强度平均值将链路分为强联接和弱联接两类,设定
阈值选择某一阈值内的链路进行路由传输。上述算法在研究方法上不尽相同,但都存在一
定的局限性。现有的预测链路稳定性的算法中,大多都是仅考虑节点相对移动性,或仅采
集节点某个时期的运动参数,而这些参数不能及时反映节点移动特性的变化,没有考虑对
链路稳定性的综合影响。通常在预测节点的未来移动性时需大量的测量数据以及控制信
息,这些因素会形成巨大开销造成网络拥塞,降低网络性能。在预测过程中节点移动特性
是假设不变的,然而在实际的网络中这些情况都会实时变化,算法不能很好地自适应环境
变化。因此,本文提出一种基于强化学习的分布式自适应拓扑稳定性方法,通过对网络中
各个邻居节点接收信号强度值自适应学习,得到每个节点对未来链路稳定性和拓扑结构的
判断依据,提升网络性能。
本文将接收信号强度与强化学习方法结合,每个分布式节点通过邻居节点的信号强度
值进行分布式强化学习,自适应划分区间边界分级处理,形成直接决策区间和自适应强化
学习区间,对不同环境下节点的联接状态进行分级判断以及实时更新学习。经过不断学习
每个节点得到最优联接策略表,根据策略表中的值预测和判断下一状态的邻居节点联接情
况,解决了综合因素对链路稳定性的影响。
1. 理论基础及模型
1.1 链路稳定性概念
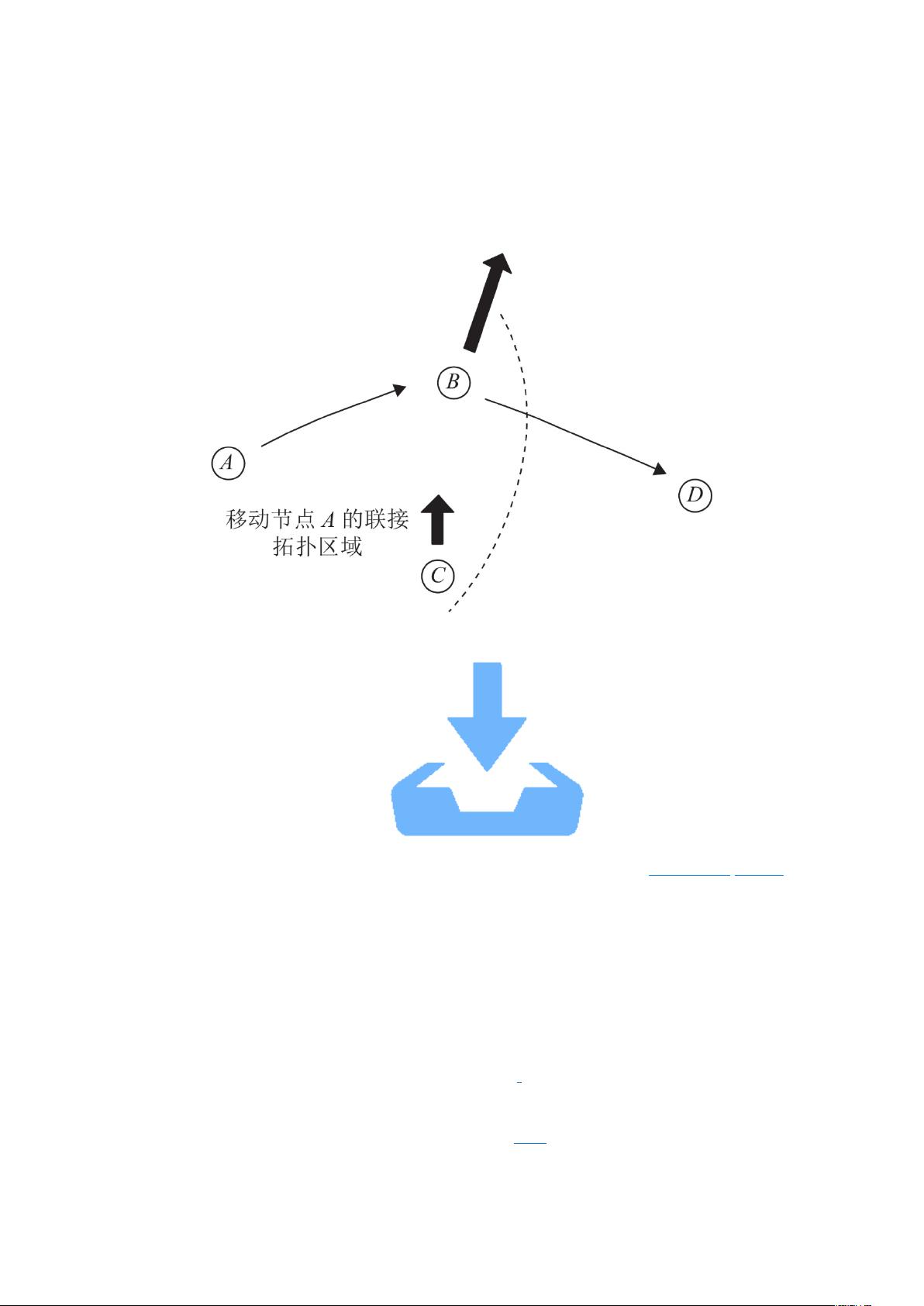
为了说明链路稳定性研究在移动自组织网络中的重要性,通过图 1 所示场景进行简要
说明。从图 1 中可以观察到,移动自组织网络包含 4 个节点 A,B,C,D。节点 A 需要向
D 发送数据包,所以节点 A 广播路由请求分组并发现要发送数据包到 D 必须经过节点 B
或 C。此时节点 B 正迅速远离 A 和 D 节点,而节点 C 缓慢向 A 移动。如果节点 A 选择 B
剩余12页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4451
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


