改进特征引导消歧的偏标记学习算法.docx
版权申诉
137 浏览量
2022-12-15
14:16:17
上传
评论
收藏 1.1MB DOCX 举报


监督学习是机器学习中被研究的最为广泛的一种学习框架
[1]
,在这种学习框架下,每
个学习示例都有明确的标记信息,是使训练得到的模型具有强泛化性能的前提。而真实世
界的情景更为复杂,由于标记成本高、真实标记难以获得等原因,常常无法得到明确的标
记信息。如何在弱监督条件下进行学习,已经成为机器学习领域的热门研究问题
[2]
。
偏标记学习属于弱监督学习的一种,属于不准确监督,即给定的标签不总是真
[3-5]
。在
偏标记学习领域,每个训练示例与一系列的候选标签集相关联,其中只有一个标签是真实
的标签,其余的标签为伪标签
[6-7]
。偏标记学习算法是通过有干扰的数据训练来习得分类模
型,在现实生活中许多场景都存在类似情况,所以该领域具有很高的研究价值
[8]
。如在互
联网搜索引擎中,对一个关键词进行搜索时,会出现许多相关程度不高的图片,这是由于
该图片的标签不止一个
[9-10]
,这种场景就适于用偏标记学习算法来解决
[11]
,通过对带有干扰
的标签进行学习,最终得到更高的识别精度,减少了在不考虑伪标签干扰情况下所带来的
损失。偏标记学习是对传统分类学习的一种延伸扩展,具有非常广阔的发展空间和应用前
景,在图像分类、医疗诊断、文本挖掘、医学图像处理等领域也有相应的应用。
1. 理论分析与设计
1.1 特征引导消歧
文献[12]提出了一种基于特征感知消歧的偏标记学习算法,利用特征空间的潜在信
息,将偏标记学习问题转换成多输出回归问题。该算法分为 2 个阶段:第一阶段是消歧,
通过对样本在特征空间的流形结构进行学习得到结构信息,并利用结构信息在候选标记集
合上生成归一化的标记置信度信息;第二阶段是预测模型的生成归纳,利用第一阶段的信
息来学习一个基于正则化的多输出回归模型,最终得到回归模型在多个标记中输出值最大
的一个所对应的标记。
1.2 改进特征引导消歧方法
以往的消歧策略是把学习的重心放在标签信息空间
[13]
,忽视了特征信息与标签之间的
联系,未对已有的信息进行充分利用。作为一种将样本特征之间的相关性充分利用和结合
的方法,改进特征引导消歧方法弥补了特征信息欠拟合的弱点,使偏标记学习过程中消歧
的效果得到了改善
[14-15]
。但是在衡量样本相关度的过程中,仅采用一种最小二乘法来计算
权重矩阵,使相关度的计算过程存在单一性。因此,将示例的相似性进行综合考量,对特
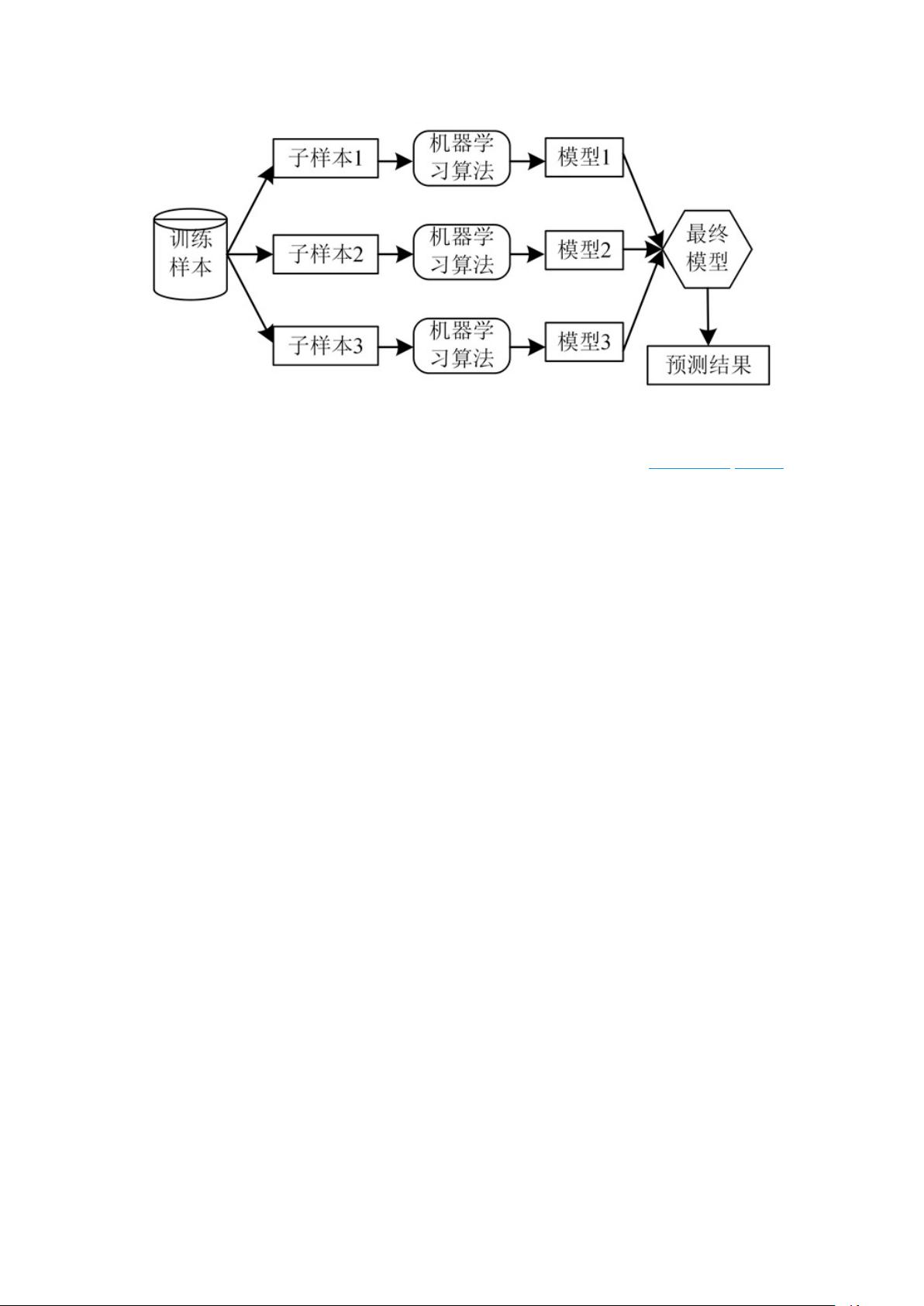
征引导消歧方法做出改进,并采用集成学习的方法对分类模型的生成进行优化,提出了改
进特征引导消歧的集成学习偏标记算法,简称 PL-FGD。
1.2.1 构建特征相似度矩阵
每个样本 x
i
都由对应的特征空间 y 和拥有多个标签集合的空间 l 组成,偏标记学习系
统的目标是获得一个输出正确标签的多分类器 h。消歧思想第一步是构造一个样本关联度


剩余15页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3895
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











