针对命名实体识别的数据增强技术针对命名实体识别的数据增强技术.docx
版权申诉
130 浏览量
2022-11-29
17:39:45
上传
评论
收藏 140KB DOCX 举报

0 引 言
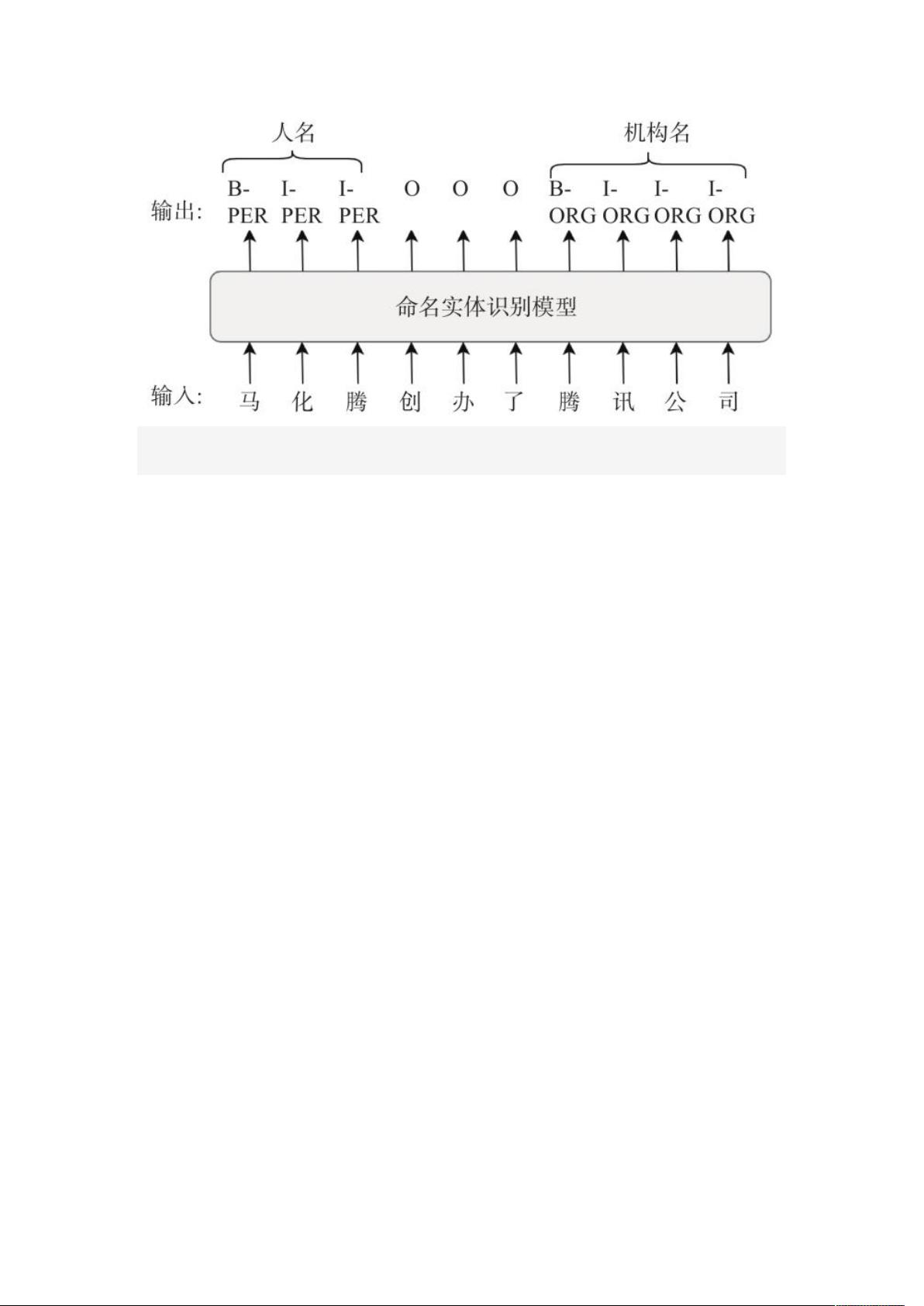
命名实体识别(Named Entity Recognition, NER)旨在通过模型自动地识别
出一段自然文本中所包含的实体, 在金融科技领域有着广泛的应用. 例如, 识
别出时事新闻中的人名、地名、机构名, 能够为后续的金融分析任务提供特征
支持. 由于实体表述十分繁杂多样, 往往无法穷举所有可能的实体(不存在一
个词典能够把所有人名都涵盖起来), 所以命名实体识别是一个艰难的任务.
近年来, 得益于深度学习的发展与兴起, 命名实体识别任务在大量训练数
据的支持下取得了良好的性能. 但是, 命名实体识别任务的数据标注成本很高,
一句话需要标注多个实体, 且往往存在歧义和嵌套的情况, 导致标注时需要详
细斟酌. 所以, 标注一条 NER 数据的时间往往是文本分类等其他自然语言处
理任 务的数 倍. 现在 有许多 词嵌入方 法能够 在大规模的无监 督文本 上进行预
训练来提高小数据量下模型的泛化性能, 但是其含有的监督信息极其有限, 因
此模型的性能远远没有达到贝叶斯最优误差. 以隐藏单元数为 100 的 Bi-LSTM
+ CRF 模 型 为 例 , 可 以 根 据 “10× 规
则 ”( https://medium.com/@malay.haldar/how-much-training-data-do-you-
need-da8ec091e956)做个简单的数据量估计: 网络中 LSTM 的参数个数约为 2
× 4 × 100
2
= 80000 (2 个方向的 LSTM, 分别有 4 个门控单元, 对应 8 个权重
矩阵). 因此, 这个网络的样本数量至少要超过 80000 × 10 = 800000 才能够接
近饱和. 然而在现实业务场景中, 命名实体识别任务的样本规模一般都在几千
至几万的量级内, 很难达到“10×规则”所要求的饱和数据量.
为 了 解 决 数 据 匮 乏 的 问 题 , 统 计 机 器 学 习 领 域 最 常 用 手 段 是 数 据 增 强
(Data Augmentation)技 术 . 目 前 , 数据增强技术在各个 统 计 学 习 领 域里都有
广泛应用. 例如, 在计算机视觉的相关任务中, 常用的数据增强技术包括对图
像进行缩放、平移、旋转、白化等操作, 可以将一张图片样本扩展成多张图片
样本. 在语音处理相关任务中, 常用的数据增强技术则有时域扭曲、时域遮罩、
频域遮罩等
[1]
, 将声波在频域和时域上加入噪声. 在自然语言处理中, 数据增
强在文本分类任务中也有广泛的应用, 最具代表性的就是 EDA 方法
[2]
, 其将自
然语言数据进行随机的替换、交换、插入、删除. 但是, 目前没有专门针对命
剩余14页未读,继续阅读

罗伯特之技术屋
- 粉丝: 3959
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0
最新资源