面向智慧康养的数据集构建方法及其应用.docx
版权申诉
14 浏览量
2022-11-28
20:29:45
上传
评论
收藏 277KB DOCX 举报


真实、有效、完备的数据集意味着机器学习模型将有较好的输入,模型通
过学习发现规律,挖掘并分析当中的关联规则与信息,可以很好地为现实中社会
生产活动提供知识决策
[1⇓-3]
。另外,从提升模型的泛化能力出发,也应该相应地增
大训练数据的规模。
中国作为世界上最大的发展中国家,人口老龄化程度已经比肩中高收入国
家群体,并在未来 30 年(到 2050 年)将迅速攀升,超过高收入国家群体
[4]
。缺
乏相关的信息化技术以及成熟的康养公共服务设施的辅助,康养数据的采集和
获取是比较困难的。真实、有效的数据集的缺失,成为了研究相关工作的障碍。
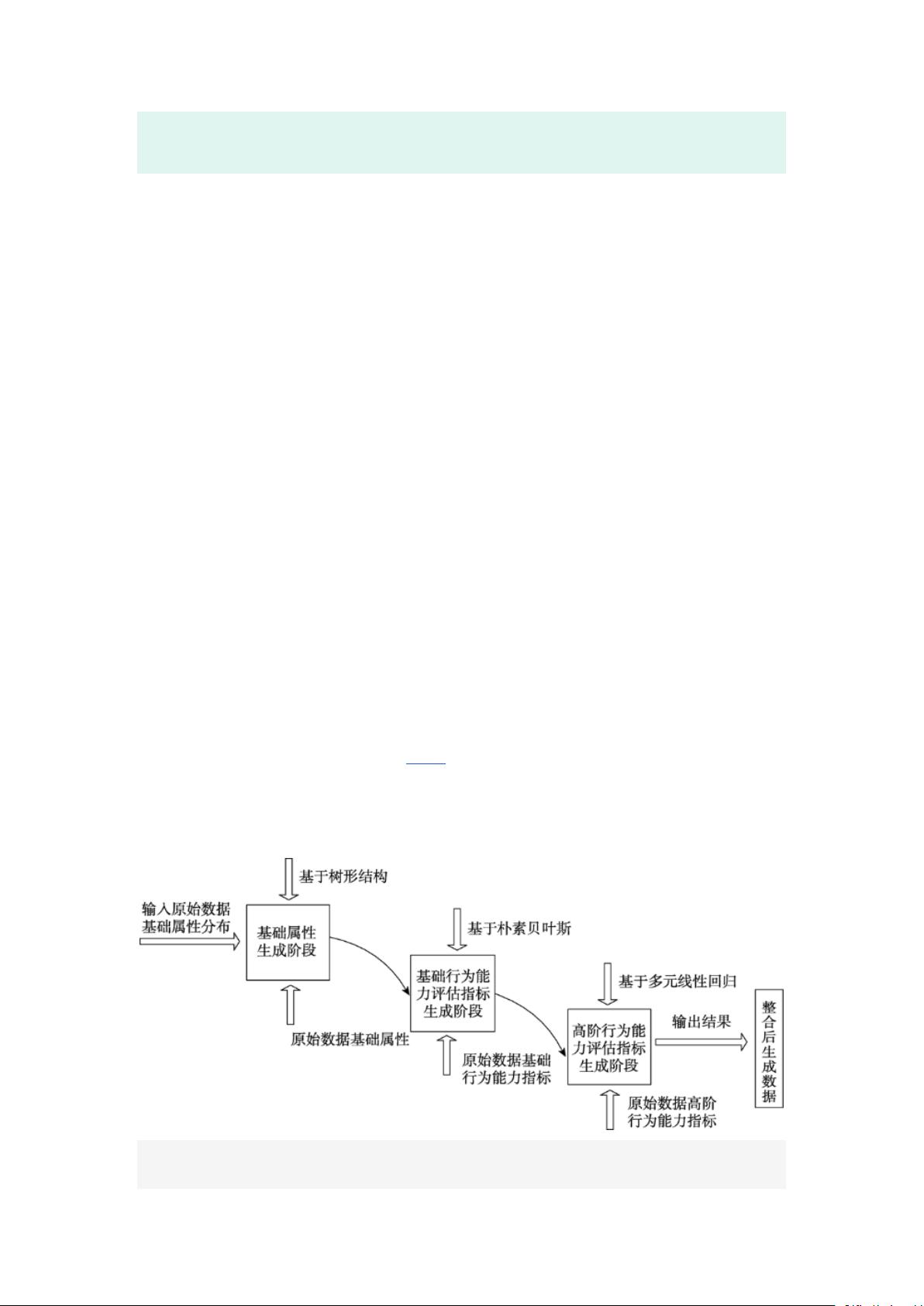
针对这一问题,本团队从慢病康复训练指导入手,通过长期的社区公益服务
采集了某市的社区康养的标准数据。在此基础上,本文提出了一种基于机器学
习的三阶段数据生成模型,以采集到小样本数据集为基础,实现了大批量具有区
域养老人群特征的样本数据生成。该模型在第一阶段使用基于树形结构
[5]
的基
础属性生成策略,按照自上而下的思想,生成符合原始数据集分布的基础属性样
本;接着提出了基于朴素贝叶斯
[6]
的基础行为能力指标生成策略,将基础行为能
力指标的生成转化为分类问题进行实现;第三阶段,又提出了基于多元线性回归
[7]
的高阶行为能力指标生成策略,在前两个阶段的基础上,通过选定合适的自变
量,拟合 9 个线性回归方程,完成高阶行为能力指标数据的生成。最后,通过整合
三个阶段的结果,完成了康复养老数据的生成工作。
另外,本文利用了模型生成的数据集,设计了基于神经网络的分类推荐模型,
在将生成的数据集反馈给康复专家验证、筛选、标注之后,经过属性特征提取,
把其输入到模型当中,实现了康复训练计划推荐的任务。
1 相关 工 作
与传统的机器学习不同,现在基于神经网络的深度学习模型通常采用多层
的网络结构,其复杂程度较高,因此也需要尽可能多的数据进行训练。而训练模
型所必须的海量训练数据样本难以获取已经成为阻碍深度学习技术进一步推
广的一个普遍性难题。目前,学术界提出了很多解决小样本数据集上学习的方
法
[8-9]
。一种常见的思路是把小样本的数据应用到改进后的算法中。文献[10]提
出了基于卷积神经网络的小样本图像识别方法,结合了深度学习与迁移学习技
术,先在卷积神经网络中对相关领域的大数据集进行预训练,提取预训练模型的


剩余16页未读,继续阅读

罗伯特之技术屋
- 粉丝: 3663
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0
最新资源