

近年来,计算机视觉(computer vision,CV)在深度学习领域的应用迅速发
展,图像处理作为 CV 中比较活跃的一个分支,广泛应用在医疗卫生、安检刑侦、
图像检索与分析、增强现实等领域中
[1]
。而 CV 领域更新变化飞快,这就要求图
像处理具有很高的灵活性、实时性和精确性。传统的硬件很难满足可编程性、
高性能和低功耗的要求。可编程技术的出现使得硬件变得可“编译”,能在嵌入式
系统上完成多种多样的新任务。并行计算方式的出现使得硬件介质可以提供更
加强大的计算能力和密度,大幅提高了芯片系统的总体性能,实现片上超级计算
[2]
。 业 界 典 型 的 两 种 并 行 可 编 程 模 型 分 布 式 共 享 内 存 MPI ( multi-point
interface)和集中式共享内存 OpenMP,与当前 GPU 多核、众核架构相比
[3]
,形
式过于单一。可编程的专用指令集处理器可以兼顾功耗、性能和灵活性
[4]
,一种
专为图形图像处理而设计的新型多态阵列处理器
[5]
应运而生,其不但处理性能
在一定程度上接近于 ASIC(application specific integrated circuit),而且具有
灵活的可编程性,它能够将线程并行、数据并行、指令并行和操作并行融合到
一 个 单 一 的 阵 列 结 构 中 。 对 于 图 像 计 算 ,ASIP( application specific instruc-
tion processor)是一种可行的硬件设计方法,基于 ASIP 体系结构,本文提出了
一种面向计算机视觉底层任务加速的可编程并行处理器。
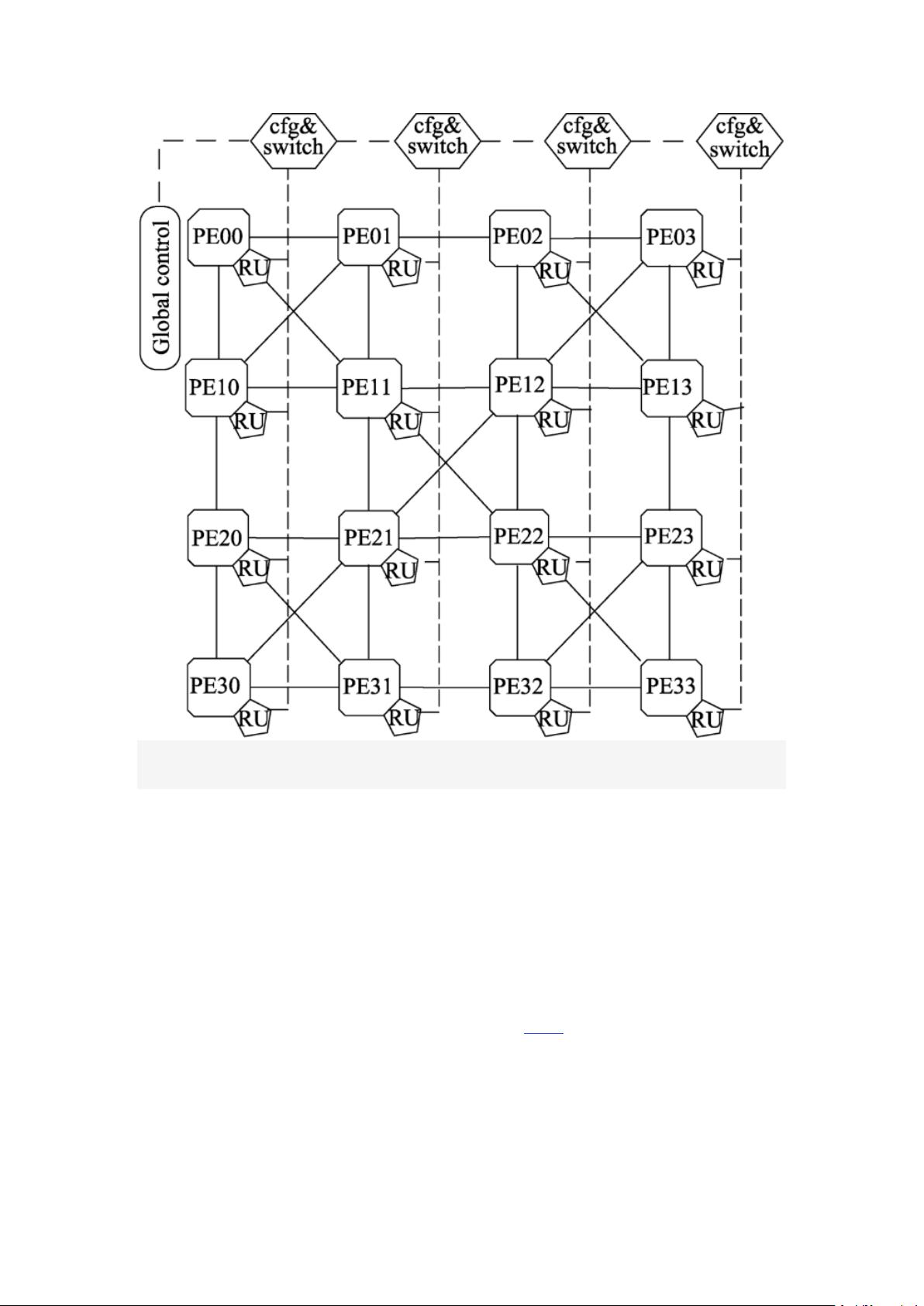
首先,本文研究了各种拓扑特性对互联网络传输性能的影响,分析了一类基
础网络的拓扑特性,选择了一种更加灵活的新型网络结构——层次交叉互联网
络(hierarchically cross-connected mesh+,HCCM+),可以根据不同应用的网
络流量重新配置为 Mesh、HCCM 或 HCCM-网络,降低整个系统的功耗。其次,
以 HCCM+的网络拓扑结构为基础,设计实现了一种可编程的 OpenVX 并行处
理器,使用有限的硬件资源,以可编程的方式对 OpenVX 1.3 标准中核心函数进
行映射,实现通用的图像处理。
1 OpenVX 的介 绍
2019 年 Khronos 发布的 OpenVX 1.3 标准中,核心图像处理函数包括了基
本像素点处理、全局处理、局部处理、特征提取四大类
[6]
。OpenVX 标准是按
照新兴的图计算方式指定的,其基本加速原理是根据需求有目的性地对图像矩
阵进行一定的操作。如图 1 所示,OpenVX 基本图像处理核函数可以看作整个
处理流程中的一个节点(node)。对于图像处理流程往往是数据从源 Node 流
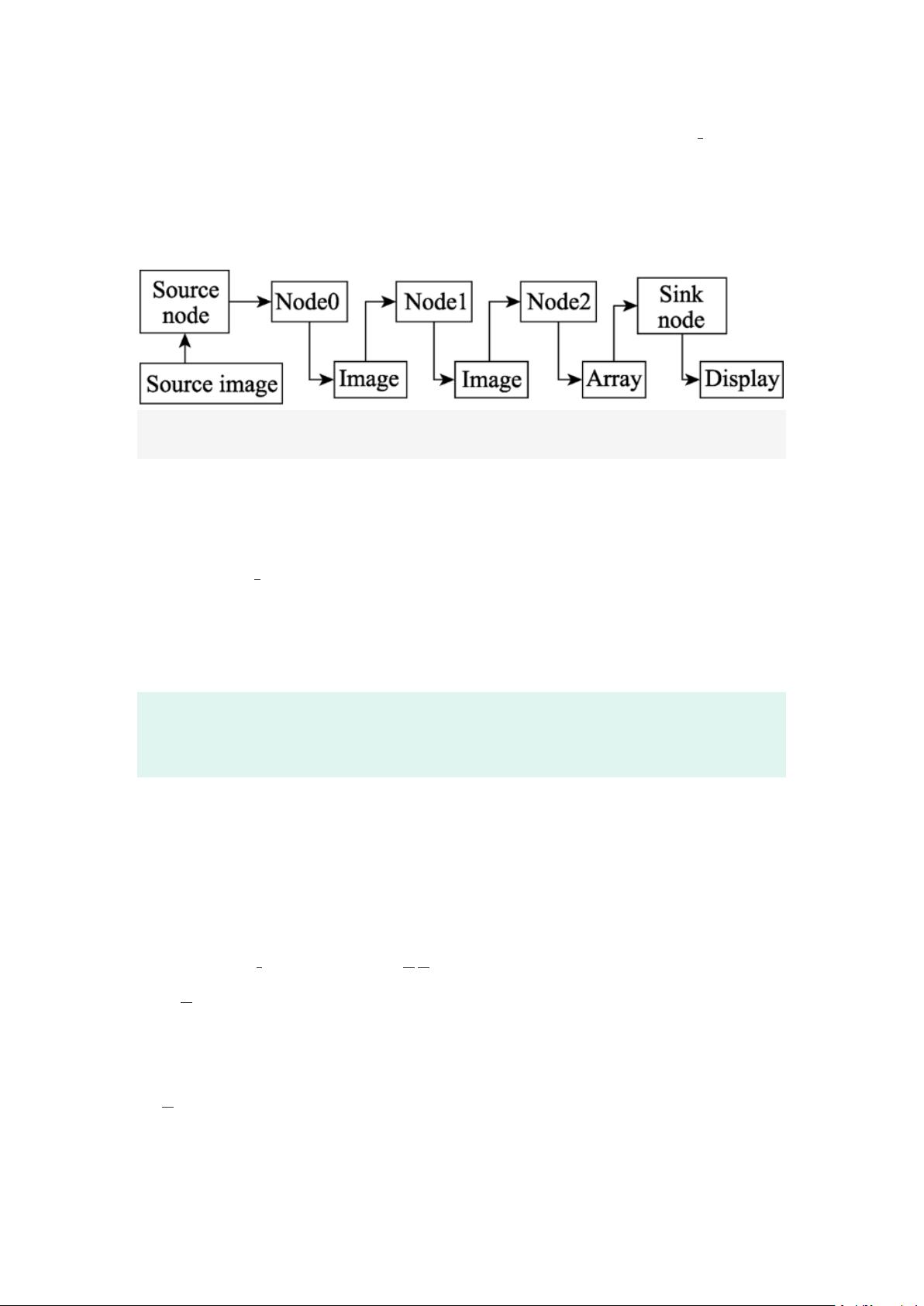


剩余27页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4494
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 毕设和企业适用springboot社交电商类及跨平台协作平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及云端储物管理系统源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及远程医疗平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及在线系统源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及企业数字化转型平台源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及人工智能医疗平台源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及人力资源管理平台源码+论文+视频.zip
- 毕设和企业适用springboot全渠道电商平台类及汽车信息管理平台源码+论文+视频.zip
- 毕设和企业适用springboot全渠道电商平台类及食品安全追溯平台源码+论文+视频.zip
- 毕设和企业适用springboot全渠道电商平台类及人工智能客服平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及在线药品管理平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及智慧医疗管理平台源码+论文+视频.zip
- 毕设和企业适用springboot人工智能类及智能农场管理系统源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及食品安全追溯平台源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及数据智能化平台源码+论文+视频.zip
- 毕设和企业适用springboot社交电商类及在线教育互动平台源码+论文+视频.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


