基于卷积神经网络的苗语孤立词语音识别.docx
版权申诉
26 浏览量
2022-06-24
13:37:33
上传
评论
收藏 362KB DOCX 举报


引言
语音识别技术在汉语、英语和一些常用少数民族语言(藏语、蒙语、维尔吾语)中已有一定研究基础
,但关于低资源、无文字的少数民族语言(苗语、普米语、佤语、白语)的语音识别研究成果较少
。在历史上,苗语只有语言,没有通用文字
,其语言和文化仅通过口授相传,相关文字资料留存
有限,且受其他常用语言的影响,使用苗语交流的人越来越少,导致苗族的语言文化正逐渐走向消亡 。
为了更好地传承和保护苗族语言文化,苗语语音语料库的构建和语音识别逐渐成为相关学者的研究重
点。
相关研究
早期语音识别方法主要基于动态时间规整算法(,)和隐马尔可夫模
型(,)实现。例如,徐利军
采用 算法和放宽起始点的
算法对孤立词语音识别进行研究,发现相较于原始 算法,放宽起始点的 算法能有效降低
噪声干扰,但语音识别率改善不明显;易雪蓉等
!
利用 模型对声调语音模型进行研究,通过改
造语音模型和语言模型提高近音字和同音字的识别率,但对轻声和四声词识别效果不理想。
传统模型在小词汇识别方面取得了良好效果,但针对大量词汇、非特定人语音的识别效果有待提升。
近年来,深度学习技术在语音识别方面受到广大研究者的青睐。例如,"# 等
$
将前馈神
经网络(%%&'#'(&,%'')和递归神经网络()#*'#
'(&,)'')引入声学模型中,在法语语音识别任务中, )'' 的效果优于 %'',但需进一步
改进最佳列表的解码;' 等
以深度神经网络—隐马尔科夫混合模型('')为网络框架,
设计了一种自动噪声检测前端技术对孤立词进行识别,其在高噪声条件下的识别率高于梅尔频率倒谱
系数(%+#,*(,- (,%,,);李云红等
提出一种结合深度玻尔兹曼
机(.(/0,.)的 '' 语音识别方法,在词错率和句错率方面比
传 统 '' 模 型 均 有 所 下 降 ; 1*0 等
将 卷 积 神 经 网 络 ( ,#( '#
'(&*,,'')与 %,, 特征相结合,其对存在背景噪音的说话人识别精度达 ! 23,但该方
法的计算复杂度较高;"0(( 等
将 *4 框架引入语音识别系统中,其对低资源语言识别
任务的识别效果优于 )'' 模型;5 等
6
改进了语音识别系统中的 )'' 模型,相较于类似尺寸的混
合模型,该模型能有效降低识别错误率。
在少数民族语言语音识别研究中,韩清华等
采用 模型对安多藏语非特定人孤立词语音识别进
行了研究,但仅针对小量词汇进行了识别,且识别效果有待提高; 7 等
提出一种基于动态贝叶斯
网络(.*'(&,.')的算法对藏语语音进行识别,相较于传统的 识
别算法,该算法提高了抗噪声的识别能力,但需要设计适合大量词汇和连续语音识别的 .' 识别模
型;5 等
对基于机器学习的孤立词识别算法进行研究,通过提取不同特征向量,在不同分类器下提
高了词语音识别的准确性;# 等
!
利用混合单元进行语言建模,通过引入插值 5 提高模型的识别
性能,降低对维吾尔族语言语音识别的错词率。目前,关于苗语数据收集、发音特点等已有一定研究 ,
但在语音识别方面研究成果较为欠缺。例如,李一如
$
对黔东苗语的比较结构进行了分析;李学林等
对贵州省中部苗语音素边界检测方法进行了研究,实现了音素边界的划分,但需要对音素进行人工
标注;杨建菊等
基于 对苗语连续语音识别系统进行初步设计和识别测试,但语音识别系统规
模较小、复杂度较低。
由于苗语存在文字缺失、地域差异等问题,采用现有语音识别方法难以直接对其进行识别。为此,本
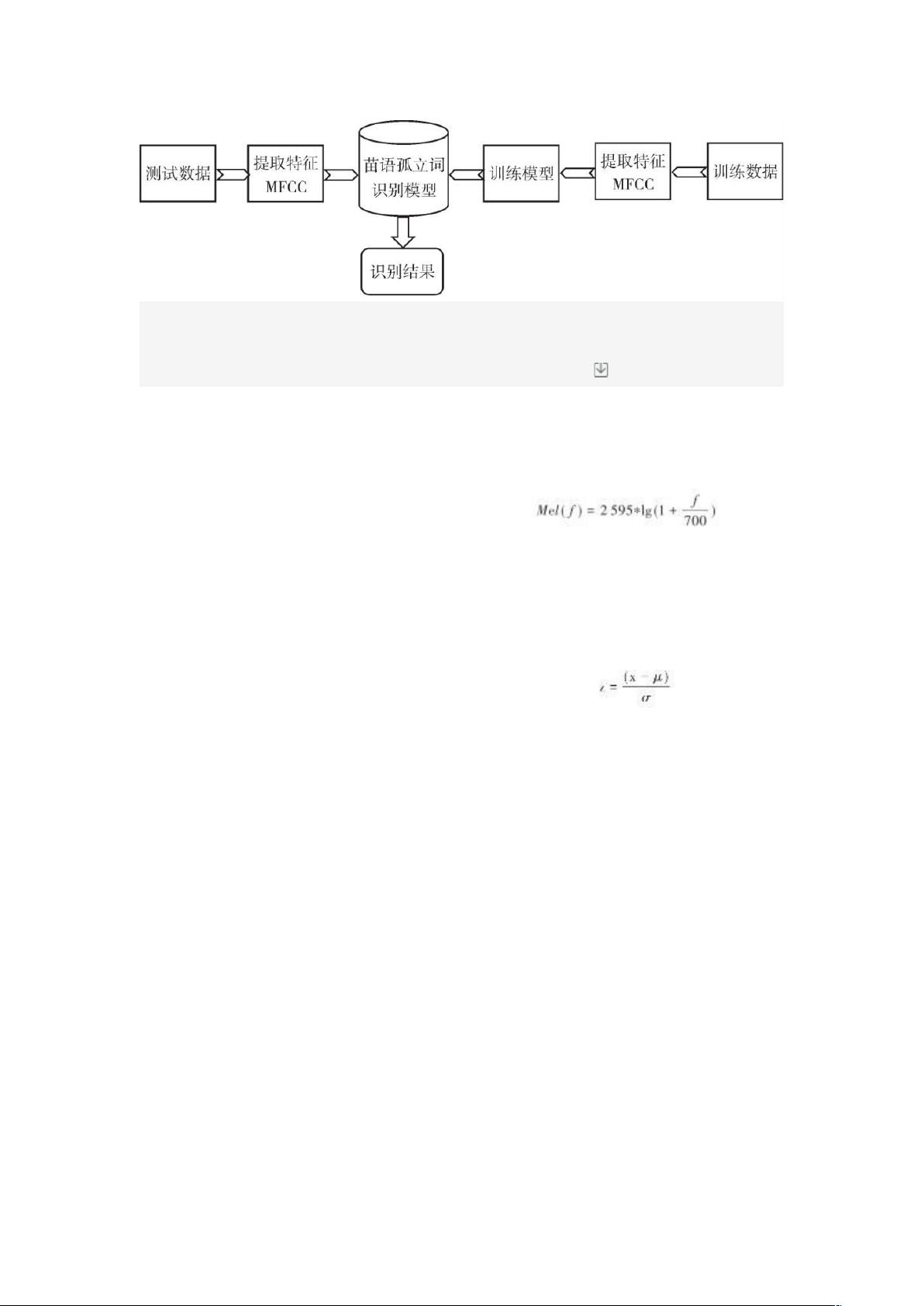
文以汉语拼音为媒介标注苗语语音,构建包含常用字词句的苗语语音语料库,引入 ,'' 建立苗语孤
立词汇识别模型;然后以自建苗语语音语料库的数据作为实验数据集验证该模型对同地域和不同地域
苗语孤立词语音识别的有效性,检验具有地域差异的苗语孤立词语音对模型识别效果的影响。

剩余11页未读,继续阅读

罗伯特之技术屋
- 粉丝: 3907
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP


相关推荐
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0
最新资源