噪声稳健性的卡方生成对抗网络.docx
版权申诉
70 浏览量
2022-05-31
15:13:48
上传
评论
收藏 434KB DOCX 举报


1 引言
深度学习
[1
]
作为一种训练深层神经网络的机器学习算法,被广泛应用于图像
[2
,3
,4
]
、语音
[5
,6
]
、自然语言处理
[7
,8
]
、大数据特征提取
[9
,10
]
等方面。生成式网络是深度
学习的重要组成部分,在无监督情况下可以获取数据的高阶特性,主要包括深
度 置 信 网 络
[11
]
、 受 限 玻 尔 兹 曼 机
[12
]
、 自 编 码 器
[13
]
和 生 成 对 抗 网 络
(GAN,generative adversarial network)
[14
]
等。
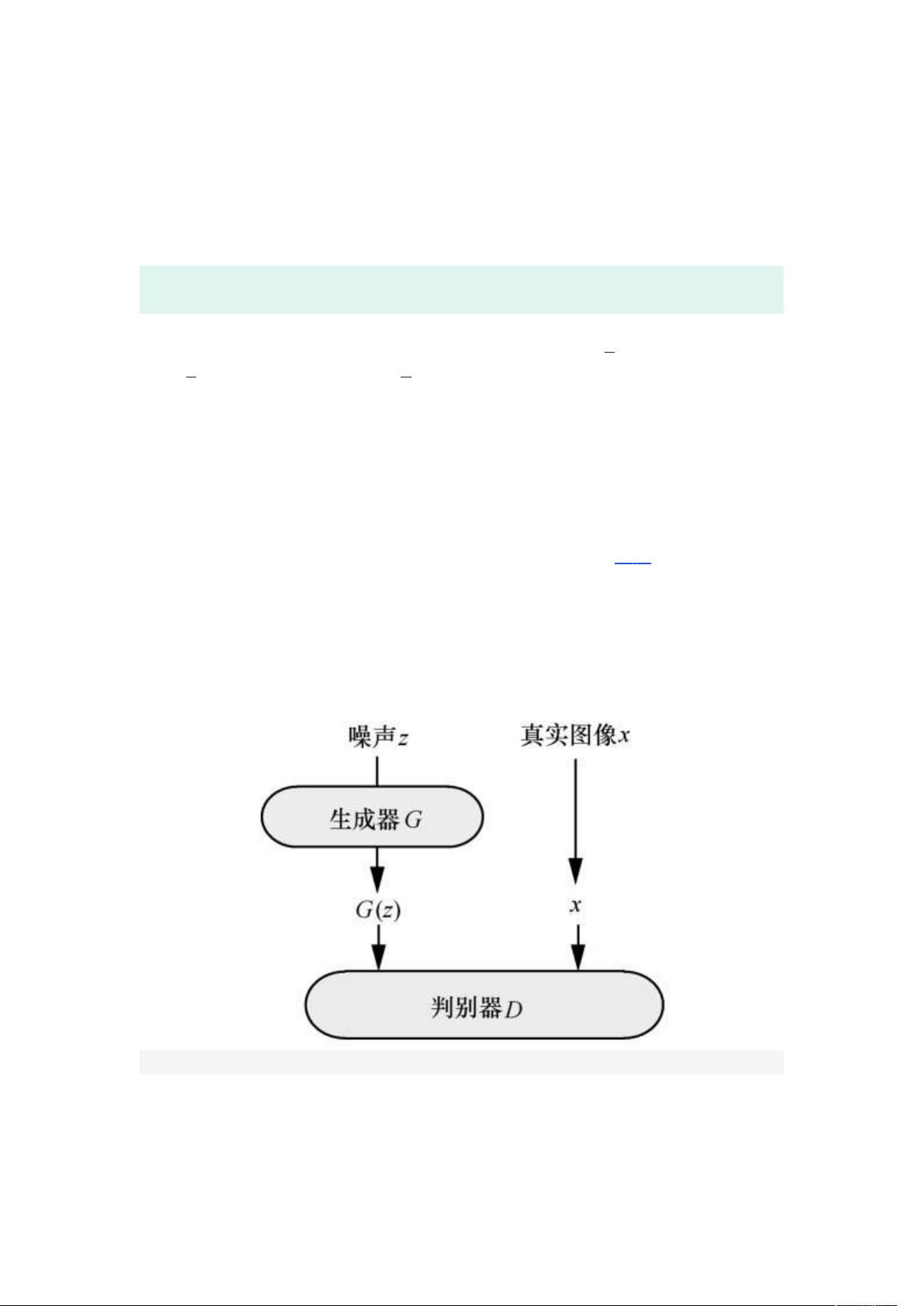
GAN 不同于其他生成式模型,其避免了马尔可夫计算、变分下限和近似推
断的复杂性,大大提高了应用效率;GAN 通过对抗学习生成逼真样本,在图像
合成
[15
,16
,17
]
、修复
[18
,19
,20
]
、分类
[21
,22
,23
]
、转换
[24
,25
,26
]
等任务中表现出色。但是 GAN
在训练和优化过程中存在着一些问题
[27
,28
]
。例如,对抗训练过程中生成器与判别
器之间需要很好的平衡,如果生成器退化且判别器误判,会导致模式崩塌问题 ,
使生成的图像单一;梯度下降在非凸函数的情况下很难达到纳什均衡;当真实
样本分布和生成样本分布没有重叠或重叠可忽略时,延森 -香农(JS,Jensen-
Shannon)散度接近定值,容易出现梯度消失问题。
针对 GAN 存在的问题,研究者们提出了有效的改进方法
[29
,30
]
。Radford 等
[31
]
采用卷积和解卷积的方式代替全连接结构,并使用归一化提升训练的稳定性,
可以生成多样化图像,但是仍需要平衡训练生成器和判别器。Salimans 等
[32
]
提
出增加判别器中间层的输出作为优化目标之一,虽然不能保证达到均衡,但提
高了网络的稳定性。Arjovsky 等
[33
]
通过理论分析说明了 JS 散度判断 2 个无重
叠 或 重 叠 可 忽 略 分 布 的 功 能 受 限 问 题 。 因 此 , Wesserstein 生 成 对 抗 网 络
(WGAN,Wesserstein GAN)
[34
]
引入 Wesserstein 距离,在连续的约束下改进
损失函数,解决了梯度消失等训练不稳定问题,从而生成丰富多样的样本。为
了解决模式崩塌问题,Ghosh 等
[35
]
提出了包含多个生成器和一个判别器的多主
体、多样化生成对抗网络,在判定真假样本的同时找到制造假样本的生成器并
优 化 。 Mao 等
[36
]
提 出 了 最 小 二 乘 生 成 对 抗 网 络 ( LSGAN,least squares
GAN),使用最小二乘损失函数代替交叉熵损失,使图像分布尽可能地接近决
策边界,提高图像质量。Chen 等
[37
]
提出了一种基于感知损失函数的生成对抗网
络,使用密集块构建生成器,生成更自然、更真实的图像。 Tan 等
[38
]
提出了一种
提高图像质量的新策略,将损失函数的梯度从分类识别器反向传播到生成器,
同 时 反 馈 标 签 信 息 , 使 生 成 器 能 够 更 有 效 地 学 习 , 生 成 高 质 量 的 图 像 。
Kancharla 等
[39
]
提出了基于多尺度结构相似度指标的生成对抗网络,将结构相似
度作为 GAN 中鉴别器损失函数的约束,保证局部结构的完整性,提高生成样本
的视觉质量。
以上基于生成对抗网络的改进方法大致上可以分为 2 类:一类是为了缓解
网络训练中出现的梯度消失、模式崩塌等问题,另一类是针对提高图像生成的
质量进行改进。但是,很少研究工作考虑到不同输入噪声对图像生成质量的影
响。文献[40
]表明不同分布在数据拟合效果上具有一定的差异性,因而不同的噪
声分布对生成样本质量有一定的影响。不同度量方法对计算分布间差异的准确
性有直接影响,欧氏距离、L1 范数等只考虑绝对距离,忽视了相对距离。对于
反映不同分布之间的距离,相对距离更有实际意义,卡方散度和熵可以有效反
映相对距离。相比于熵,卡方散度没有对数和指数运算,其计算复杂度小,运
算速度较快。此外,卡方散度还具有稀疏不变性和量化敏感性
[41
]
,利于衡量不同
分布间细微的差异。因此,有必要将卡方散度用于生成对抗网络中展开研究。


剩余19页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3961
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- java-leetcode题解之第111题二叉树的最小深度.zip
- java-leetcode题解之第110题平衡二叉树.zip
- java-leetcode题解之第109题有序链表转换二叉搜索树.zip
- java-leetcode题解之第108题将有序数组转换为二叉搜索树.zip
- java-leetcode题解之第107题二叉树的层序遍历II.zip
- java-leetcode题解之第102题二叉树的层序遍历.zip
- java-leetcode题解之第103题二叉树的锯齿形层序遍历.zip
- java-leetcode题解之第104题二叉树的最大深度.zip
- java-leetcode题解之第173题二叉搜索树迭代器.zip
- java-leetcode题解之第100题相同的树.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


