### 1. 数据说明
+ **电影信息**包括电影id、图片链接、名称、导演名称、编剧名称、主演名称、类型、制片国家、语言、上映日期、片长、季数、集数、其他名称、剧情简介、评分、评分人数,共**67245条**数据信息。虽说是电影信息,但其中也包括电视剧、综艺、动漫、纪录片、短片。
+ **电影演员信息**包括演员id、姓名、图片链接、性别、星座、出生日期、出生地、职业、更多中文名、更多外文名、家庭成员、简介,共**89592条**数据信息。这里所指的演员包括电影演员、编剧、导演。
+ **书籍信息**包括书籍id、图片链接、姓名、子标题、原作名称、作者、译者、出版社、出版年份、页数、价格、内容简介、目录简介、评分、评分人数,共**64321条**数据信息。
+ **书籍作者信息**包括作者id,姓名、图片链接、性别、出生日期、国家、更多中文名、更多外文名、简介,共**6231条**数据信息。这里作者包括书籍作者和译者。
### 2. 配制环境
+ 系统环境:ubuntu 18.04
+ python环境:python3.6
+ python依赖包:requests, bs4, redis, yaml, multiprocessing
### 3. 爬虫思路
#### 3.1电影爬虫
进入电影分类界面后,找到开发者工具,找到NetWork->XHR,我们能够看到Request URL为<https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=剧情>。
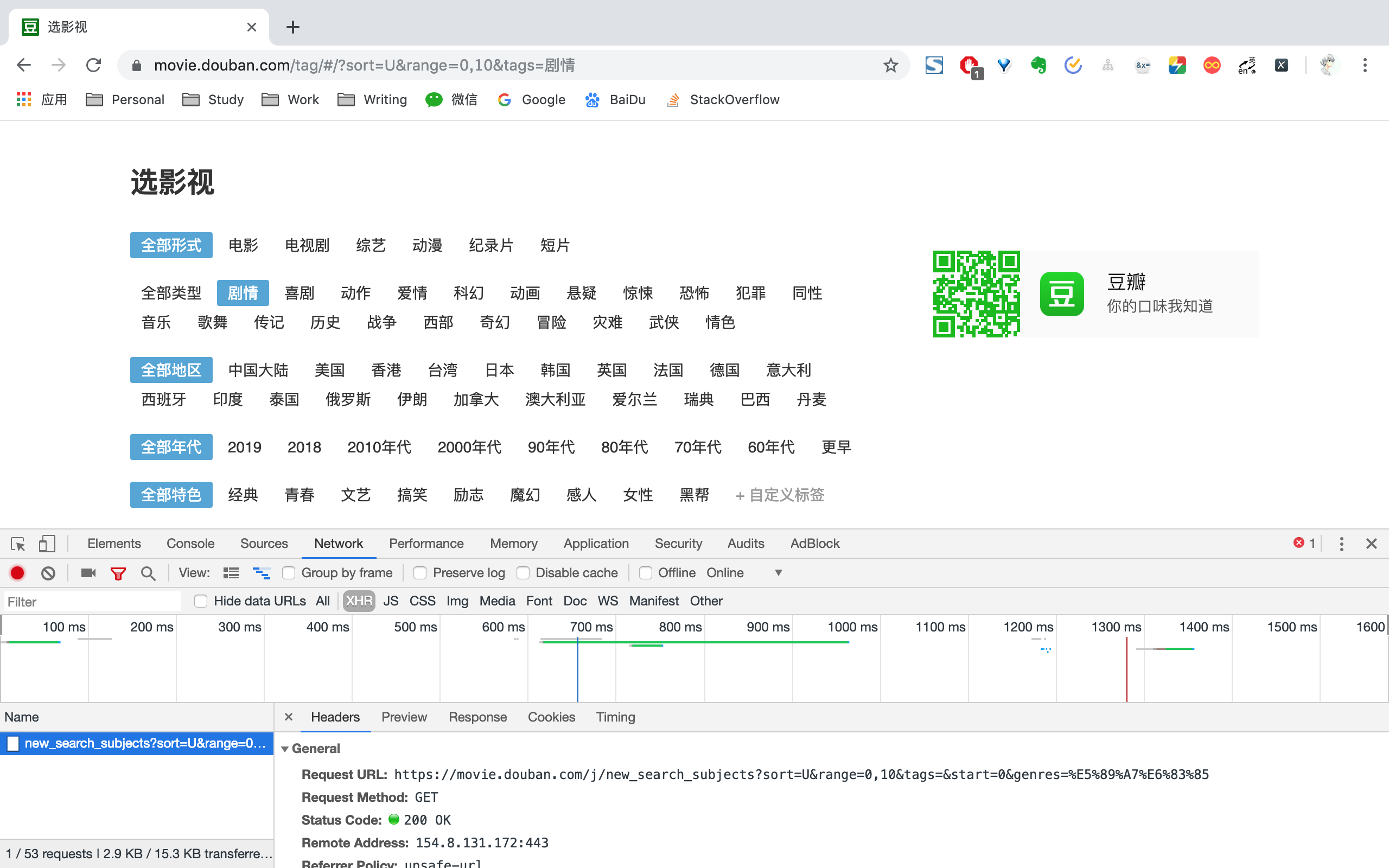
打开上述Request URL,能够看到一系列电影信息,我们只需要拿到其中的id即可。为了确保不重复爬取相同的电影,每拿到一个id之后,都存到redis已爬取队列之中。如果下次再遇到相同的id,则跳过不进行爬取。
另外,再次观察上面URL,发现只要改变start和genres,便能够拿到所有电影id。
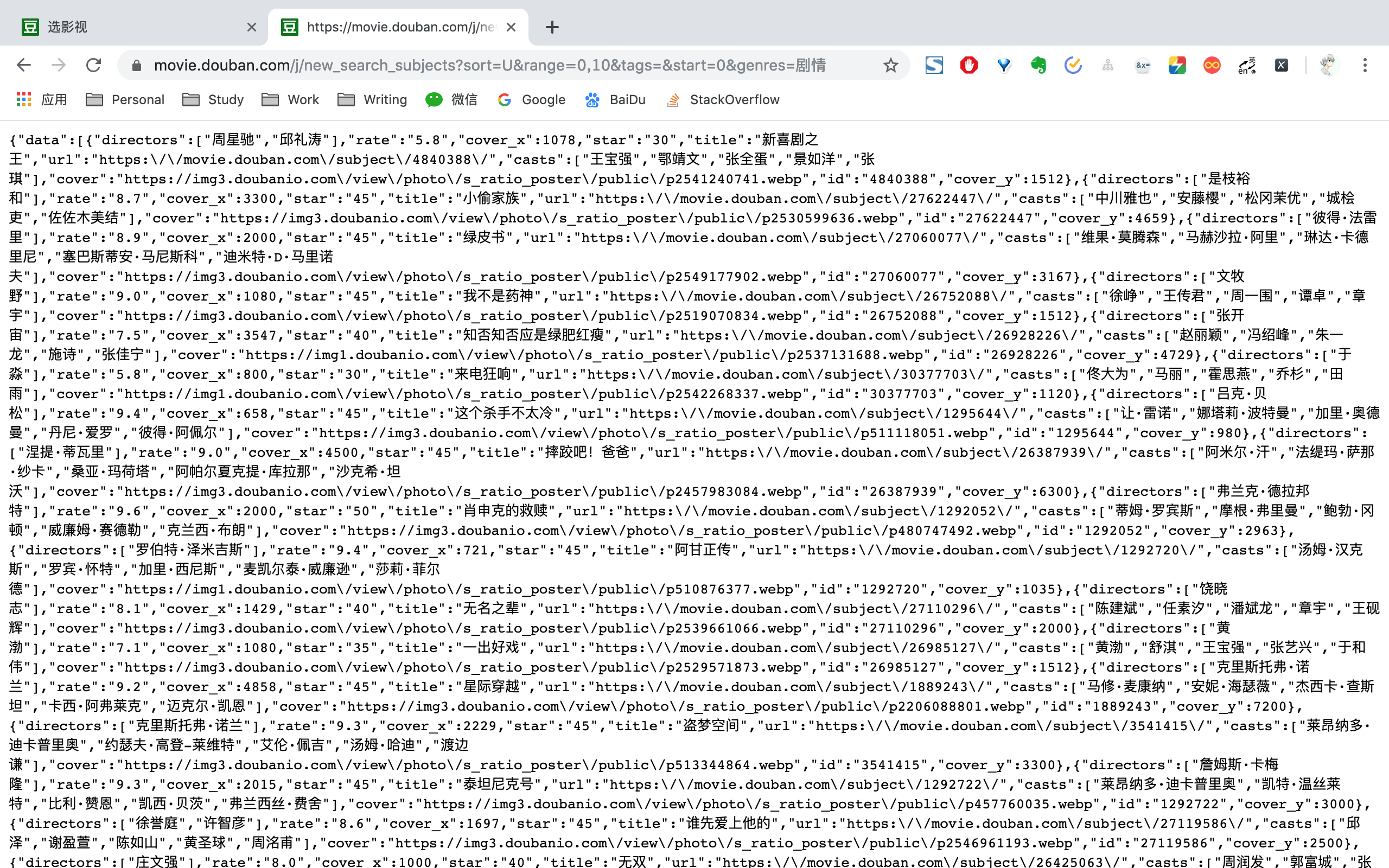
以新喜剧之王id 4840388为例,拼接<https://movie.douban.com/subject>后得到Movie URL为<https://movie.douban.com/subject/4840388>。请求Movie URL,便能得到电影信息。
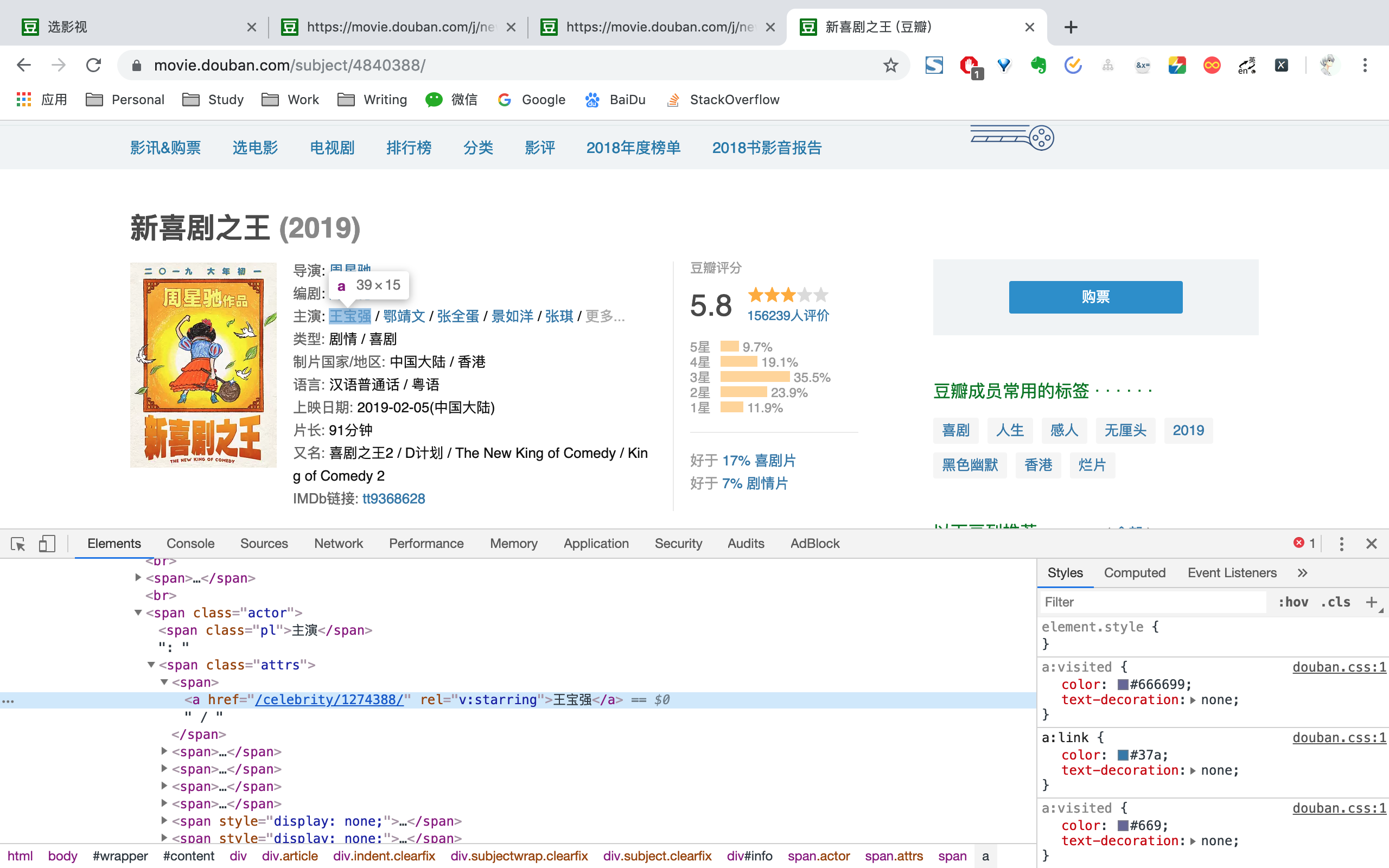
通过BeautifulSoup选取相应标签,便能够拿到电影id、图片链接、名称、导演名称、编剧名称、主演名称、类型、制片国家、语言、上映日期、片长、季数、集数、其他名称、剧情简介、评分、评分人数信息。
爬取电影信息结束之后,将演员id单独进行提取出来。同样为了保证不重复爬取,每得到一个演员id,都存放到redis已爬取队列之中。
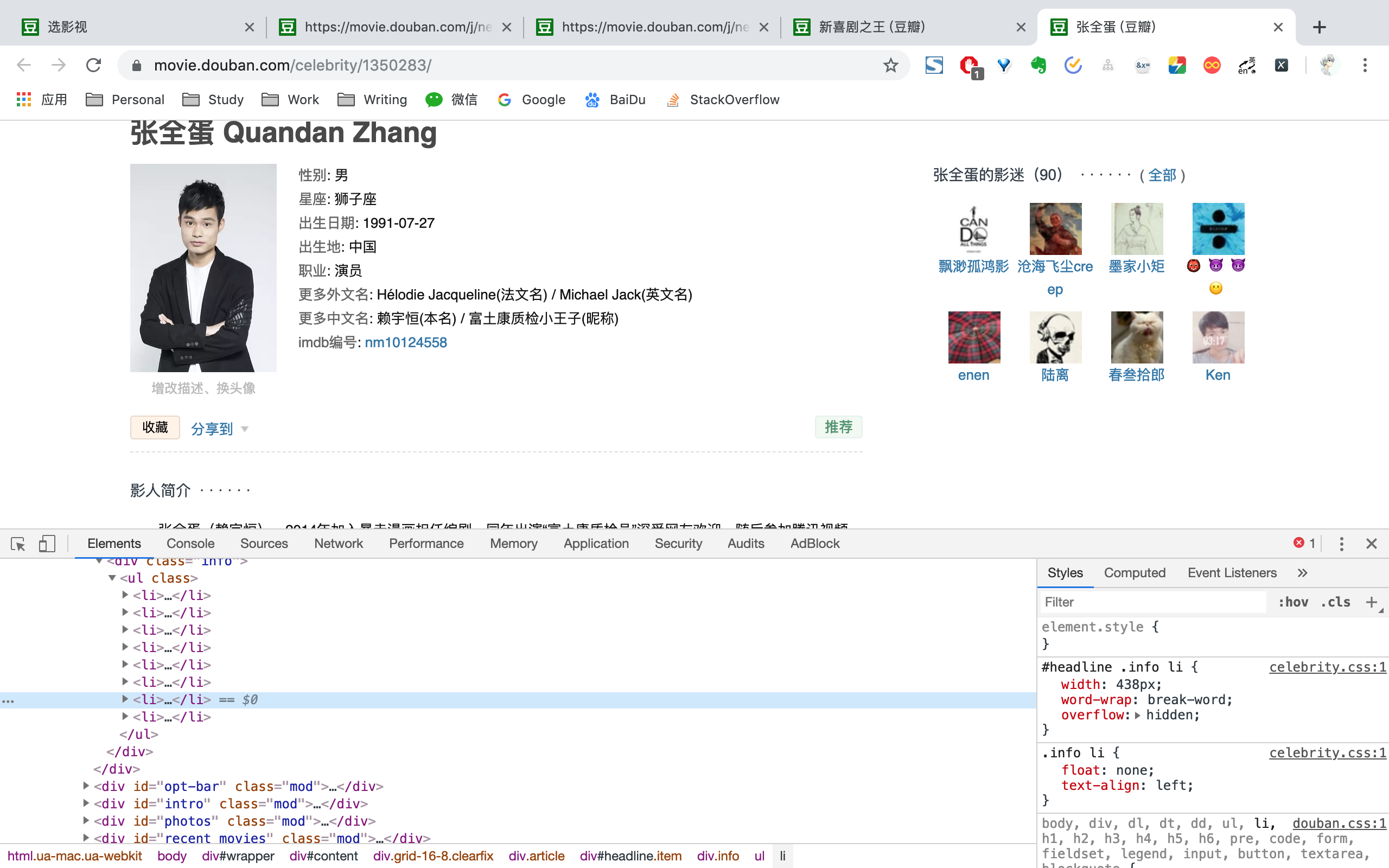
以张全蛋id /celberity/1350283为例,拼接<https://movie.douban.com>,便能得到演员URF为<https://movie.douban.com/celebrity/1350283/>。然后请求演员URL,利用BeautifulSoup选取相应标签,便能拿到演员id、姓名、图片链接、性别、星座、出生日期、出生地、职业、更多中文名、更多外文名、家庭成员、简介信息。
总结一下,获取电影信息和电影演员信息流程为
1. 获取<https://movie.douban.com/tag/#/>界面所有电影类别genres,循环电影类别genres。
2. 请求<https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=剧情>网址,每次返回20个电影id。如果返回为空,更换电影类别genres。
3. 对返回的20个电影id存放到redis已爬取队列之中,返回去重后的电影id list。
4. 多线程爬取电影id list之中的电影信息。
5. 获取电影演员id,存到到redis已爬取队列之中,返回去重后的演员id list。
6. 多线程爬取演员id list之中的电影信息。
7. start加20循环2-7步骤。
#### 3.2 书籍爬虫
进入豆瓣图书标签页面,请求<https://book.douban.com/tag/?view=type&icn=index-sorttags-all>,利用BeautifulSoup得到所有图书标签。
以小说标签为例,URL为<https://book.douban.com/tag/小说?start=0&type=T>,请求URL之后,利用BeautifulSoup选取相应标签,便能够拿到当前页面所有书籍id。为了确保不重复爬取相同的书籍,每拿到一个id之后,都存到redis已爬取队列之中。如果下次再遇到相同的id,则跳过不进行爬取。
同样,观察上述URL,我们只需要通过遍历start和tag便能够拿到所有书籍id。
以解忧杂货店id 25862578为例,拼接<https://book.douban.com/subject/>后便能得到书籍URL为<https://book.douban.com/subject/25862578/>。然后请求书籍URL页面,通过BeautifulSoup选取相应标签,便能够拿到书籍id、图片链接、姓名、子标题、原作名称、作者、译者、出版社、出版年份、页数、价格、内容简介、目录简介、评分、评分人数信息。
爬取书籍信息结束之中,将作者id单独提取出来。同样为了保证不重复爬取,每得到一个作者id,都存放到redis已爬取队列之中。
以东野圭吾为例,获取作者id 4537266,拼接<https://book.douban.com/author/>之后,便能得到作者URL为<https://book.douban.com/author/4537266/>。然后请求作者URL,利用BeautifulSoup选取相应标签,便能拿到作者id,姓名、图片链接、性别、出生日期、国家、更多中文名、更多外文名、简介信息。
总结一下,获取书籍信息和书籍作者流程为
1. 请求<https://book.douban.com/tag/?view=type&icn=index-sorttags-all>界面,利用BeautifulSoup获取图书所有标签。
2. 请求<https://book.douban.com/tag/小说?start=0&type=T>,利用BeautifulSoup获取20个书籍ID。如果为空,则更换书籍标签tag。
3. 对返回的20个书籍id存放到redis已爬取队列之中,返回去重后的书籍id list。
4. 多线程爬取书籍id list之中的书籍信息。
5. 获取书籍作者id,存放到redis已爬取队列之中,返回去重后的作者id list。
6. 多线程爬取演员id list之中的作者信息。
7. start加20循环2-7步骤。
### 4. 使用教程
```shell
├── book
│ ├── __init__.py
│ ├── book_crawl.py
多线程爬虫Get豆瓣电影、演员、书籍、作者信息.zip

版权申诉
63 浏览量
2024-03-25
16:08:40
上传
评论
收藏 4.65MB ZIP 举报
 多线程爬虫Get豆瓣电影、演员、书籍、作者信息.zip (24个子文件)
多线程爬虫Get豆瓣电影、演员、书籍、作者信息.zip (24个子文件)  WGT-code movie
WGT-code movie  __init__.py 0B movie_page_parse.py 13KB movie_person_page_parse.py 10KB movie_crawl.py 15KB movie_spider_config.yaml 311B book __init__.py 24B book_crawl.py 16KB book_page_parse.py 10KB book_spider_config.yaml 62B book_person_page_parse.py 7KB proxy get_ip.py 796B
__init__.py 0B movie_page_parse.py 13KB movie_person_page_parse.py 10KB movie_crawl.py 15KB movie_spider_config.yaml 311B book __init__.py 24B book_crawl.py 16KB book_page_parse.py 10KB book_spider_config.yaml 62B book_person_page_parse.py 7KB proxy get_ip.py 796B ua_list.txt 2KB ip_list.txt 287B img
ua_list.txt 2KB ip_list.txt 287B img  Python爬虫_Get豆瓣电影与书籍详细信息图片01.png 453KB Python爬虫_Get豆瓣电影与书籍详细信息图片03.png 808KB Python爬虫_Get豆瓣电影与书籍详细信息图片07.png 860KB Python爬虫_Get豆瓣电影与书籍详细信息图片02.png 1011KB 推广.png 102KB Python爬虫_Get豆瓣电影与书籍详细信息图片06.png 650KB Python爬虫_Get豆瓣电影与书籍详细信息图片05.png 520KB Python爬虫_Get豆瓣电影与书籍详细信息图片04.png 757KB README.md 10KB log book_log_config.yaml 573B movie_log_config.yaml 574B
Python爬虫_Get豆瓣电影与书籍详细信息图片01.png 453KB Python爬虫_Get豆瓣电影与书籍详细信息图片03.png 808KB Python爬虫_Get豆瓣电影与书籍详细信息图片07.png 860KB Python爬虫_Get豆瓣电影与书籍详细信息图片02.png 1011KB 推广.png 102KB Python爬虫_Get豆瓣电影与书籍详细信息图片06.png 650KB Python爬虫_Get豆瓣电影与书籍详细信息图片05.png 520KB Python爬虫_Get豆瓣电影与书籍详细信息图片04.png 757KB README.md 10KB log book_log_config.yaml 573B movie_log_config.yaml 574B资源评论


JJJ69
- 粉丝: 6266
- 资源: 5775

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 使用ASP.NET Core和Entity Framework Core来构建一个基本的进销存系统.rar
- 深度学习经典数据集+FER2013面部表情识别+附带使用方法的python代码
- Python中,要实现连接多个相机并识别多个二维码.rar
- 使用FFT算法对一个信号进行分析.rar
- 171cms游戏应用下载系统源码.zip
- 基于jsp+servlet+mysql蛋糕甜品店购物网站源码+数据库(期末大作业).zip
- Java项目:在线蛋糕商城系统(java+jsp+mysql)源码+数据库+期末大作业.zip
- ZapyaClient10_7-1.apk
- 织梦cms站长导航网站源码.zip
- 基于SSM+MySQL的网络投票调查问卷系统源码+数据库(java期末大作业).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


