# 爬取汽车之家 二手车产品库
## 目标
最近经常有人在耳边提起汽车之家,也好奇二手车在国内的价格是怎么样的,因此本次的目标站点是 [汽车之家](https://car.autohome.com.cn/2sc/440399/index.html) 的二手车产品库
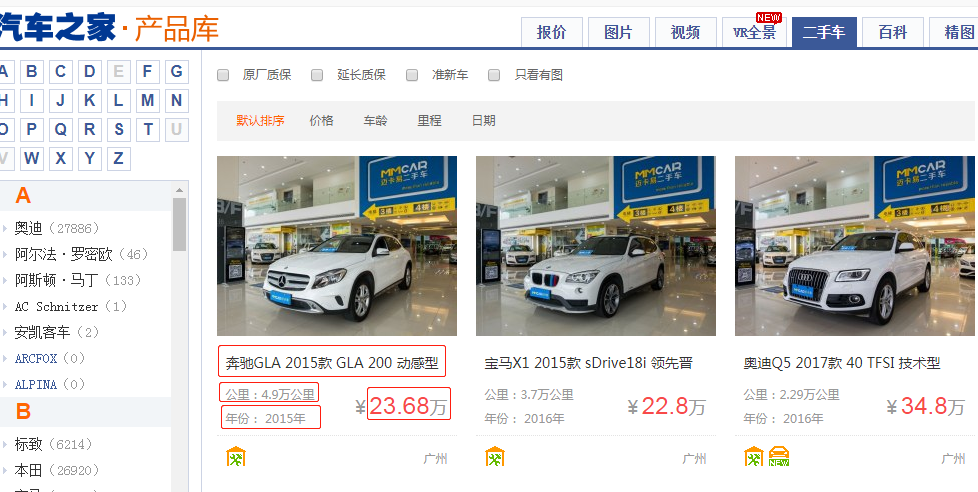
分析目标源:
- 一页共24条
- 含分页,但这个老产品库,在100页后会存在问题,因此我们爬取99页
- 可以获取全部城市
- 共可爬取 19w+ 数据
## 开始
爬取步骤
- 获取全部的城市
- 拼装全部城市URL入队列
- 解析二手车页面结构
- 下一页URL入队列
- 循环拉取所有分页的二手车数据
- 循环拉取队列中城市的二手车数据
- 等待,确定队列中无新的 URL
- 爬取的二手车数据入库
### 获取城市
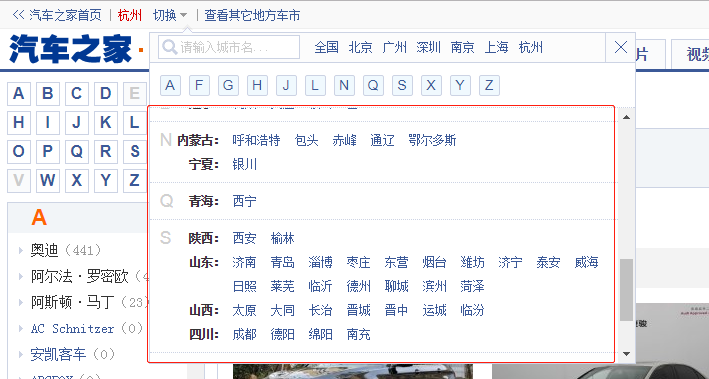
通过页面查看,可发现在城市筛选区可得到全部的二手车城市列表,但是你仔细查阅代码。会发现它是JS加载进来的,城市也统一放在了一个变量中
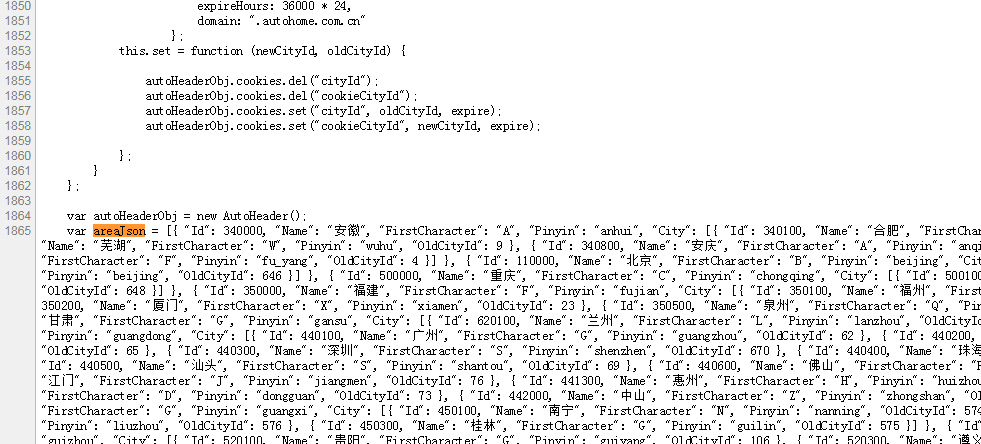
有两种提取方法
- 分析JS变量,提取出来
- 直接将 `areaJson` 复制出来作为变量解析
在这里我们直接将其复制粘贴出来即可,因为这是比较少变动的值
### 获取分页
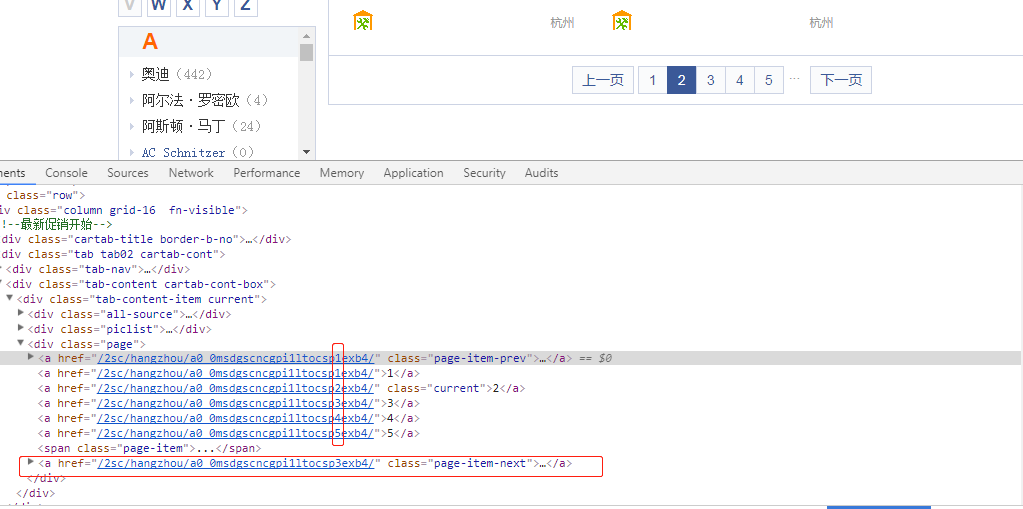
通过分析页面可以得知分页链接是有一定规律的,例如:`/2sc/hangzhou/a0_0msdgscncgpi1ltocsp2exb4/`,可以发现 `sp%d`,`sp` 后面为页码
按照常理,可以通过预测所有分页链接,推入队列后 `go routine` 一波 即可快速拉取
但是在这老产品库存在一个问题,在超过 100 页后,下一页永远是 101 页
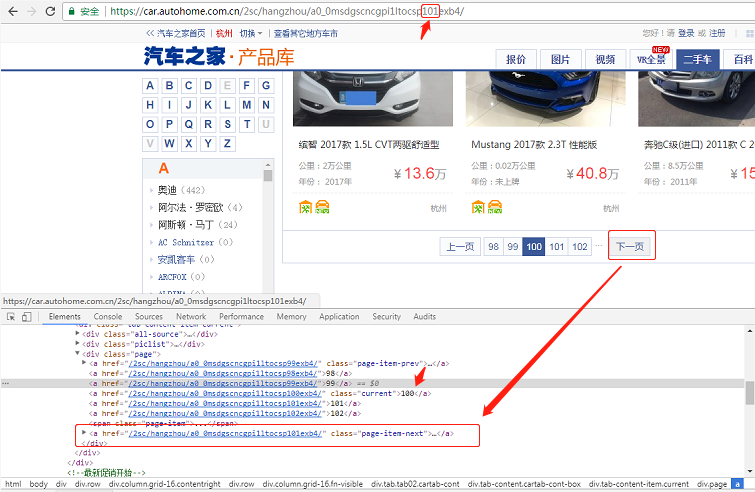
因此我们采取比较传统的做法,通过拉取下一页的链接去访问,以便适应可能的分页链接改变; 100 页以后的分页展示也很奇怪,先忽视
### 获取二手车数据
页面结构较为固定,常规的清洗 HTML 即可
```
func GetCars(doc *goquery.Document) (cars []QcCar) {
cityName := GetCityName(doc)
doc.Find(".piclist ul li:not(.line)").Each(func(i int, selection *goquery.Selection) {
title := selection.Find(".title a").Text()
price := selection.Find(".detail .detail-r").Find(".colf8").Text()
kilometer := selection.Find(".detail .detail-l").Find("p").Eq(0).Text()
year := selection.Find(".detail .detail-l").Find("p").Eq(1).Text()
kilometer = strings.Join(compileNumber.FindAllString(kilometer, -1), "")
year = strings.Join(compileNumber.FindAllString(strings.TrimSpace(year), -1), "")
priceS, _ := strconv.ParseFloat(price, 64)
kilometerS, _ := strconv.ParseFloat(kilometer, 64)
yearS, _ := strconv.Atoi(year)
cars = append(cars, QcCar{
CityName: cityName,
Title: title,
Price: priceS,
Kilometer: kilometerS,
Year: yearS,
})
})
return cars
}
```
## 数据
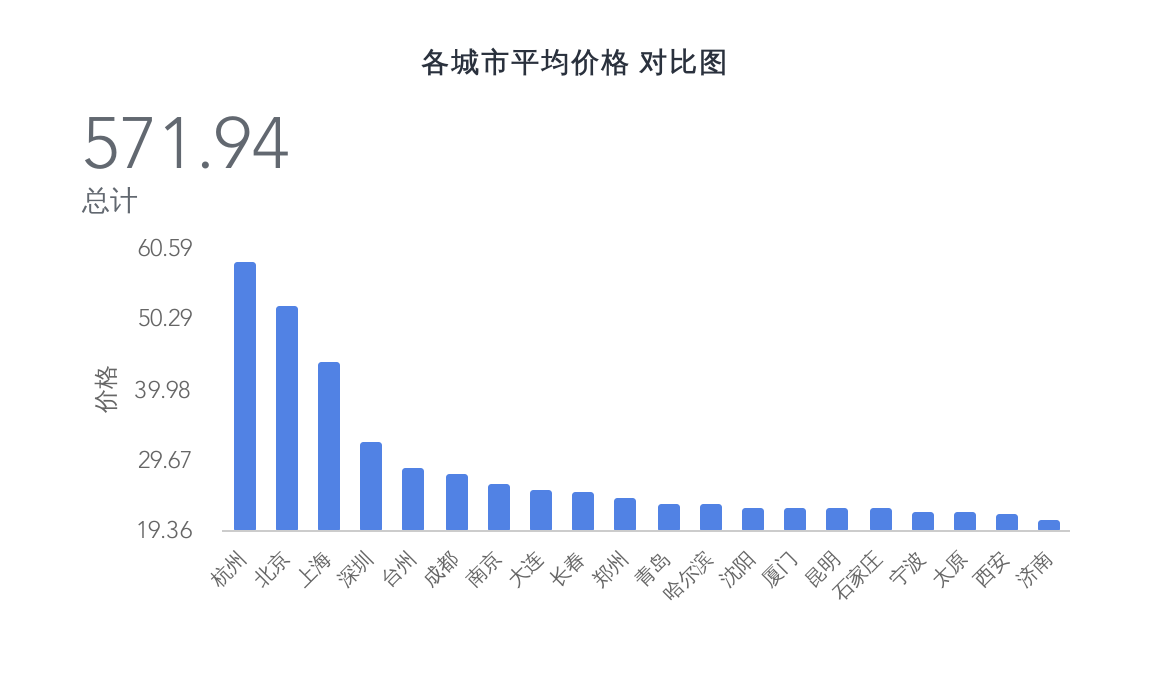
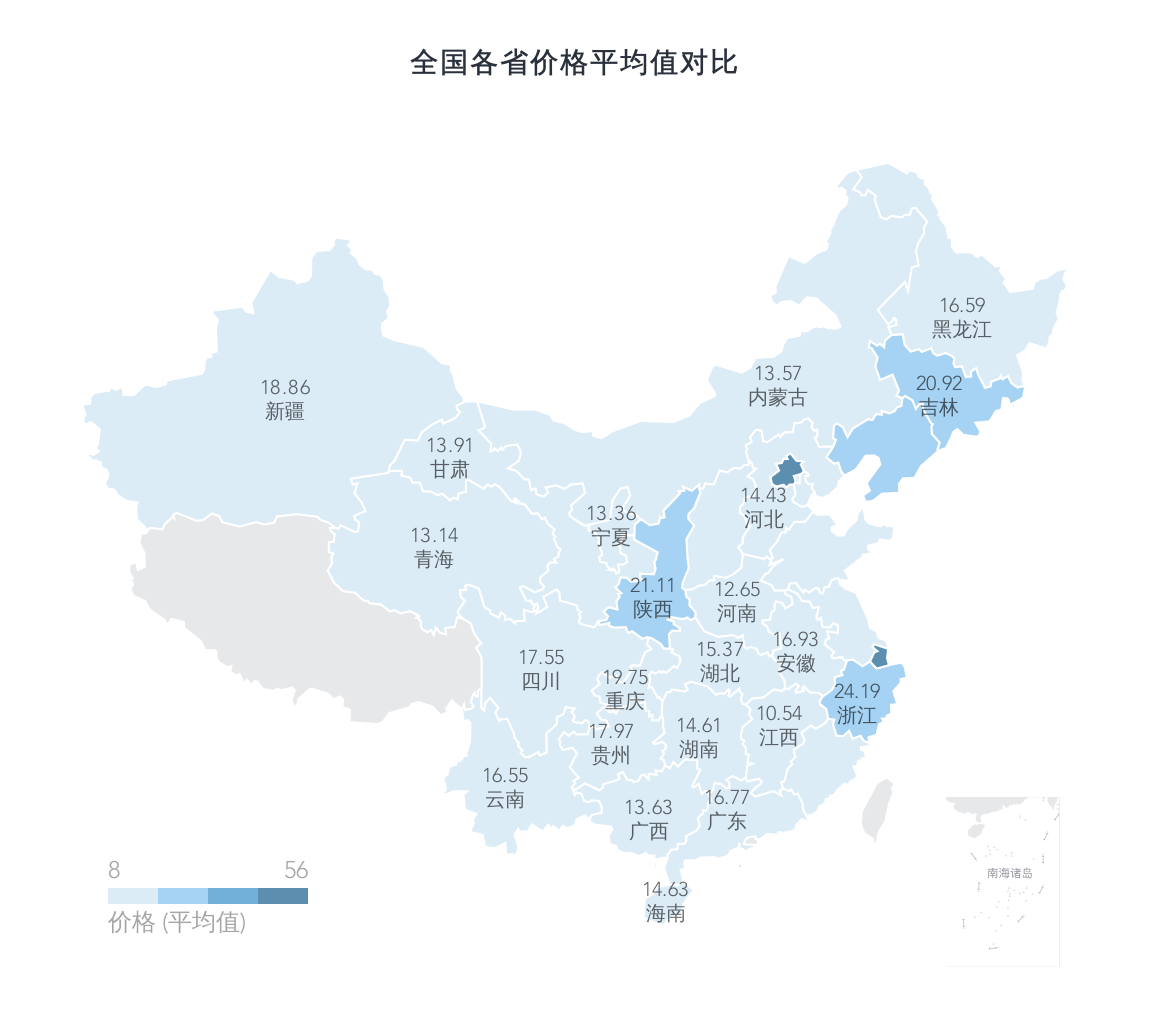
在各城市的平均价格对比中,我们可以发现北上广深里的北京、上海、深圳都在榜单上,而近年势头较猛的杭州直接占领了榜首,且后几名都有一些距离
而其他城市大致都是梯级下降的趋势,看来一线城市的二手车也是不便宜了,当然这只是均价
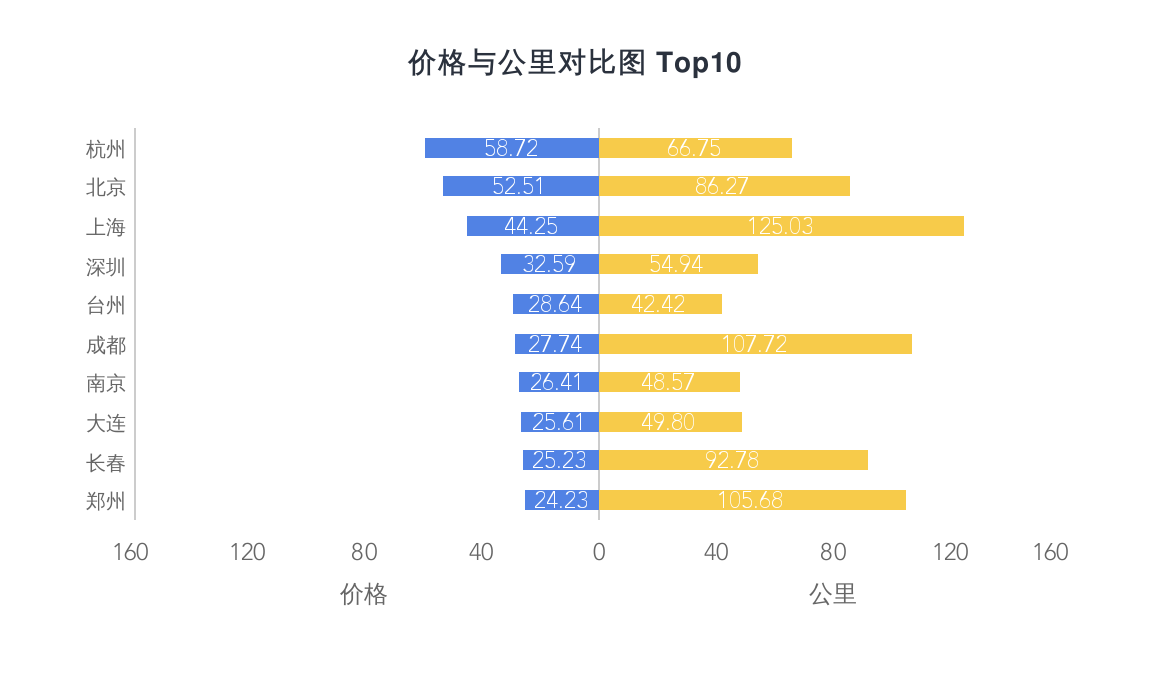
我们可以看到价格和公里数的对比,上海、成都、郑州的等比差异是有点大,感觉有需求的话可以在价格和公里数上做一个衡量
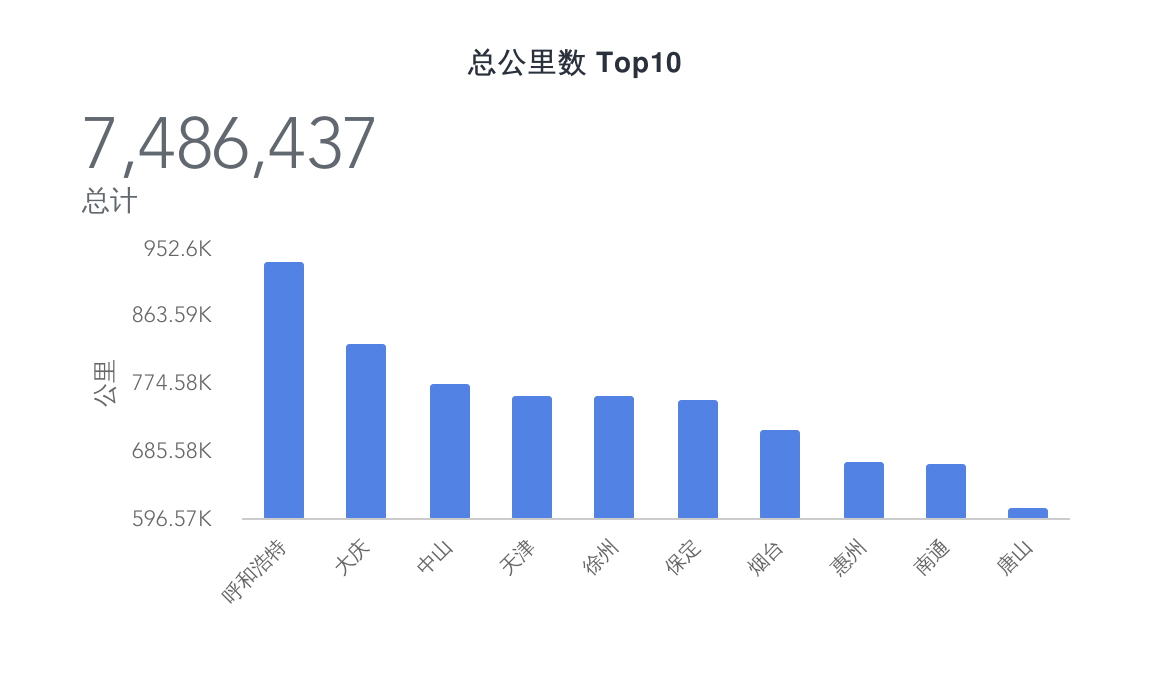
这图有点儿有趣,粗略的统计了一下总公里数。在前几张图里,平均价格排名较高的统统没有出现在这里,反倒是呼和浩特、大庆、中山等出现在了榜首
是否侧面反应了一线城市的车辆更新换代较快,而较后的城市的车辆倒是换代较慢,公里数基本都杠杠的

通过对标题的分析,可以得知车辆产品库的命名基本都是品牌名称+自动/手动+XXXX款+属性,看标题就能知道个概况了
Golang爬虫 爬取汽车之家 二手车产品库.zip

版权申诉
137 浏览量
2024-03-23
19:53:33
上传
评论
收藏 10KB ZIP 举报
 Golang爬虫 爬取汽车之家 二手车产品库.zip (10个子文件)
Golang爬虫 爬取汽车之家 二手车产品库.zip (10个子文件)  WGT-code scheduler
WGT-code scheduler  scheduler.go 241B downloader download.go 566B LICENSE 1KB docs cars.sql 446B spiders car.go 18KB model model.go 806B .gitignore 347B fake headers.go 715B README.md 4KB main.go 1KB
scheduler.go 241B downloader download.go 566B LICENSE 1KB docs cars.sql 446B spiders car.go 18KB model model.go 806B .gitignore 347B fake headers.go 715B README.md 4KB main.go 1KB资源评论


JJJ69
- 粉丝: 6033
- 资源: 5613

下载权益

C知道特权

VIP文章

课程特权
开通VIP











