# dianping
scrapy抓取数据存储至本地mysql数据库
基于python开发,采用scrapy,数据存储至本地数据库(或excel表格)
程序的主要目的是完成抓取和分析的任务同时学习爬虫相关知识,所以在细节处理上略有不足,但考虑到最终的目的是记录自己的学习,另外帮助到他人学习,所以这些细节无关紧要(毕竟不是面向用户的程序)。
程序还有建立商家-用户点评的表格还在进行中...
也许你可以在这里找到一些帮助,比如:一次返回两个,多个item,切割中文,中文转数字等问题
<br> 1)一次返回两个、多个item
在pipelines.py文件中,可以看到。如果是不同的spider返回的,直接根据spider的name来判断即可
<br> elif isinstance(item, User_shopItem):
<br> 2)而一个spider返回两个、多个item,则通过item的name来判断(item的名字可以在spider中调试并输出)
<br> if str(str1) == "<class 'dianping.items.CommentItem'>":
一次抓取
------
1.首先创建MySQl数据库
<br>在/dianping/settings.py中写定了
<br>MYSQL_DBNAME = 'dianpingshop'
<br>MYSQL_USER = 'root'
<br>MYSQL_PASSWD = 'yourpassword'
<br>当然你也可以修改
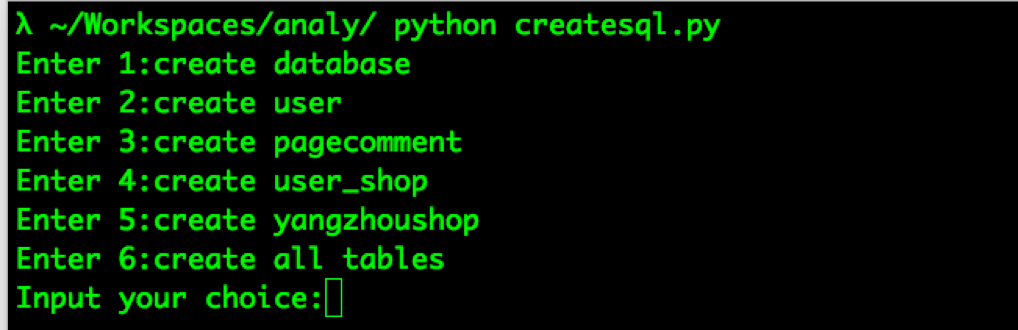
比如选择6,创建程序用的所有表格
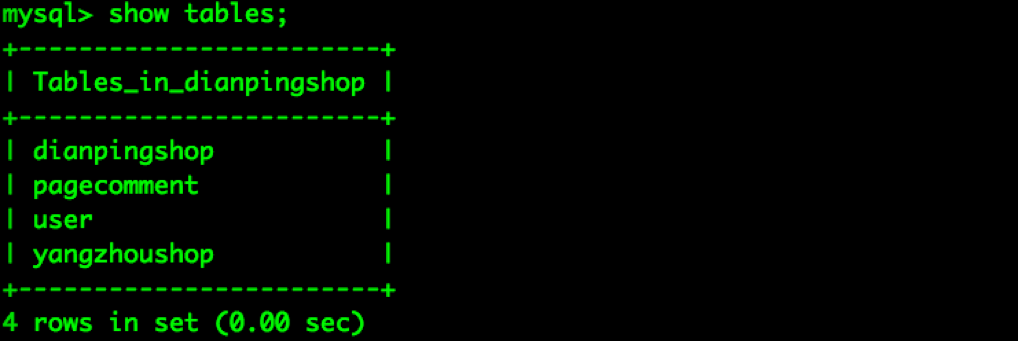
2.根据Scrapy的常用语法抓取数据
<br>
比如运行scrapy crawl dianping抓取扬州地区前50页的数据
<br>
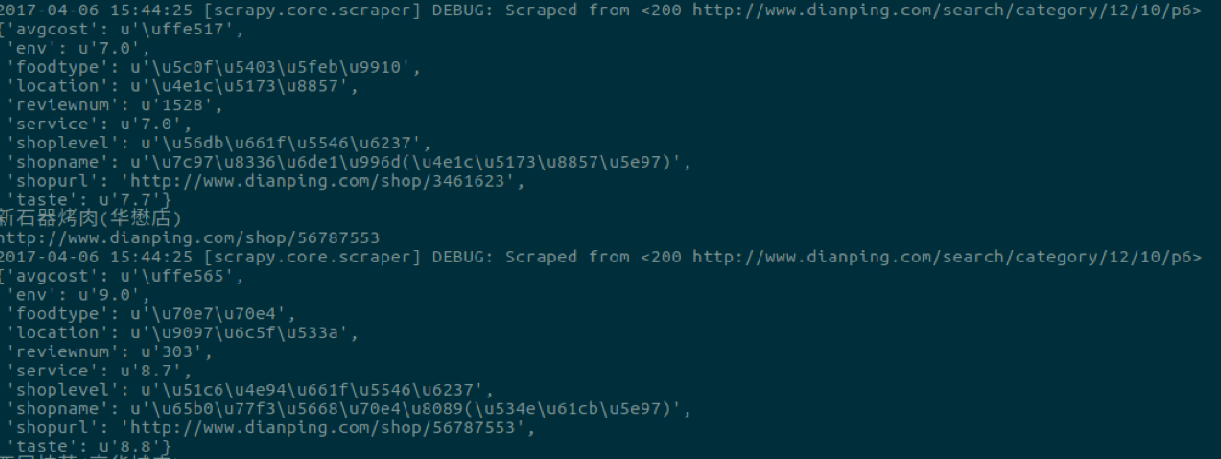
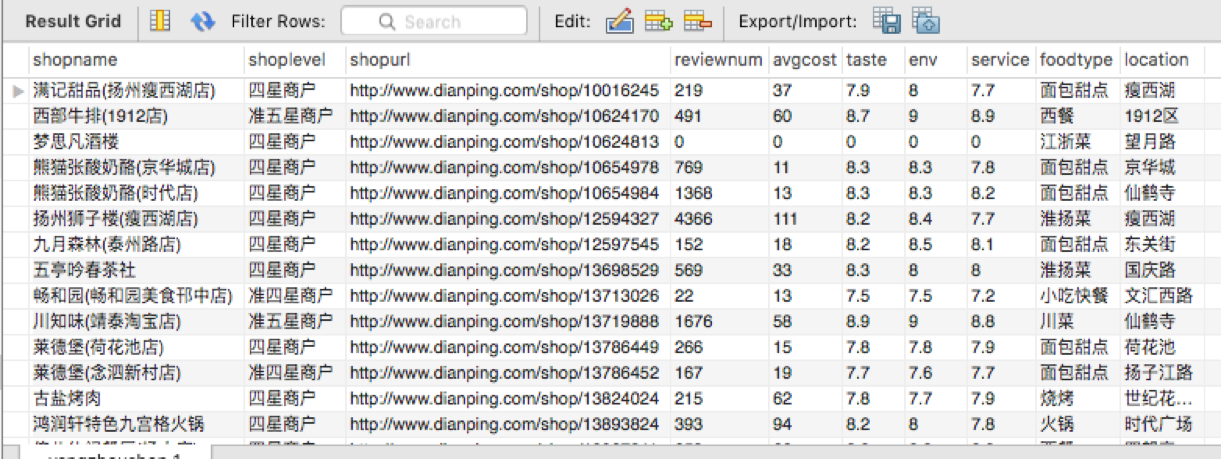
抓取的数据存储在本地MySQL数据库中,当然之后也可以转换成Excel表格
二次抓取
------
用户选择某种种类继续抓取(考虑到日常生活中,人类大多数会从某一种类中选择某一商家)
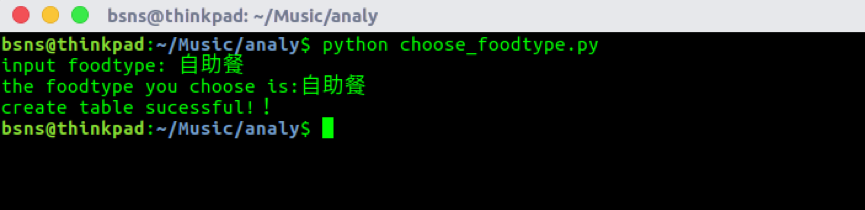
在已经抓取的yangzhoushop总选择所有种类为自助餐的数据,存入dianping表中,等待继续抓取
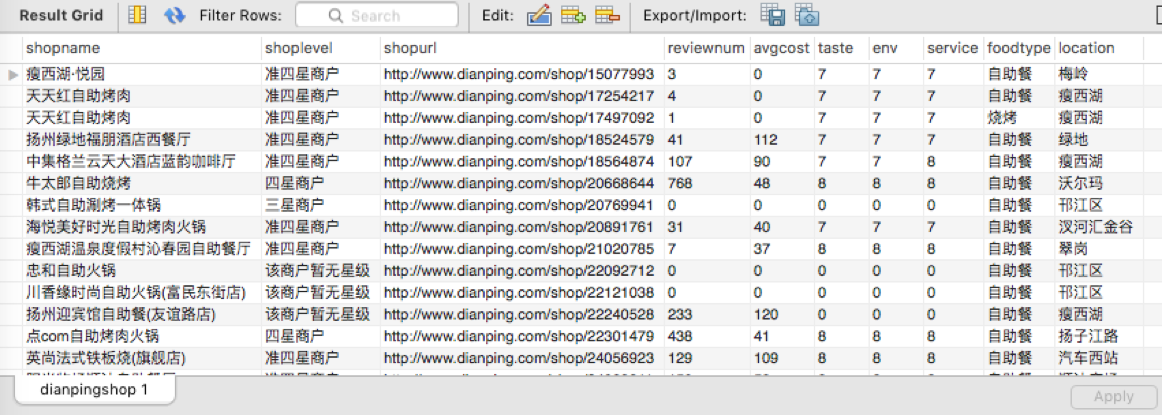
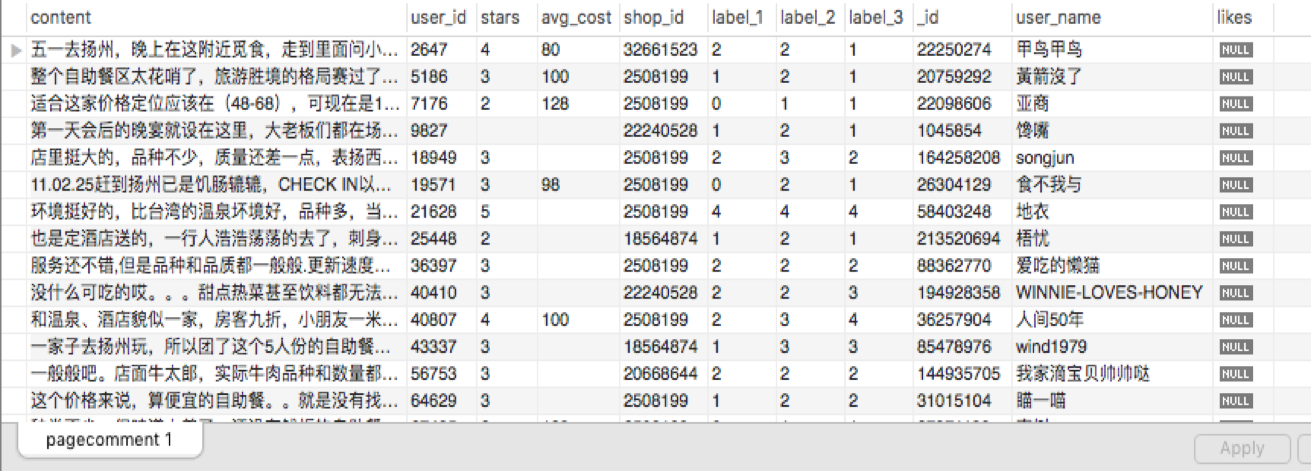
运行Scrapy crawl comment抓取点评内容,和点评人的具体信息
转格式
-----
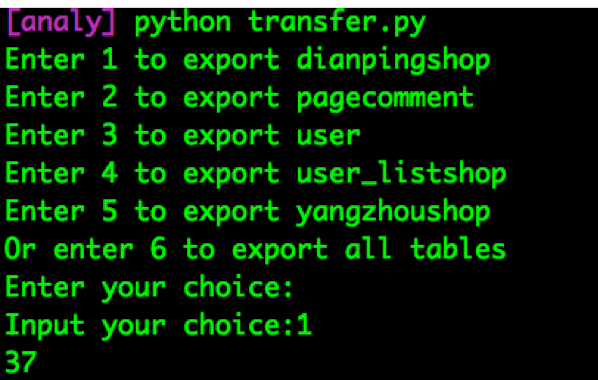
运行transfer.py把数据从MySQL中导出到Excel表格中

<br>分析<br>
---
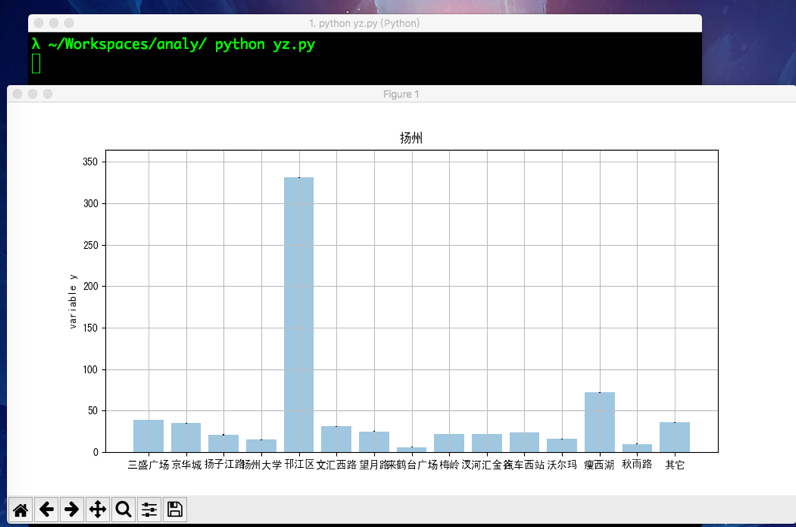
运行yz.py 生成地理位置的条形图(这一步骤是刚开始学习时编写的,所以数据是写定的)
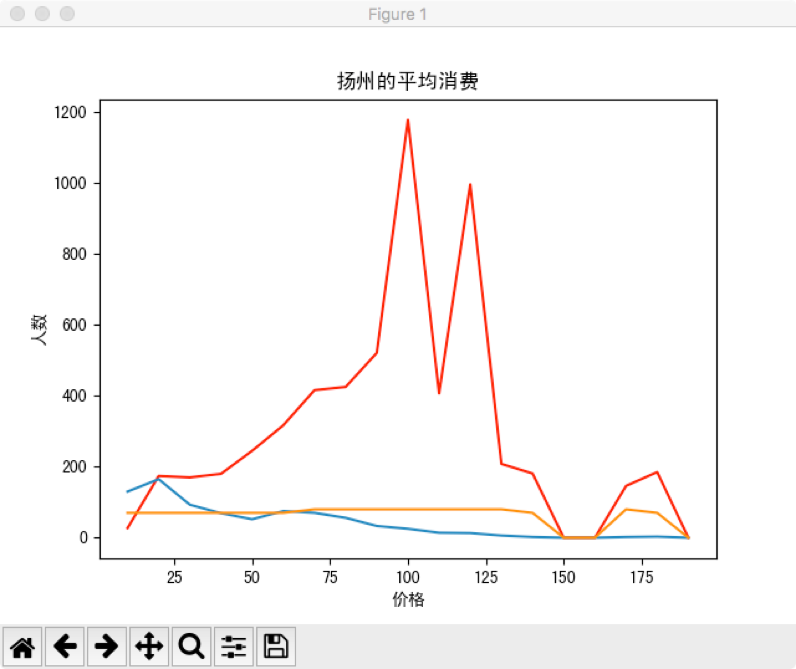
运行price.py显示价格相关的条形图
<br>
根据横轴的价格增长,三条曲线分别为
<br>1)红色:消费人数
<br>2)蓝色:商店数量
<br>3)黄色:评分
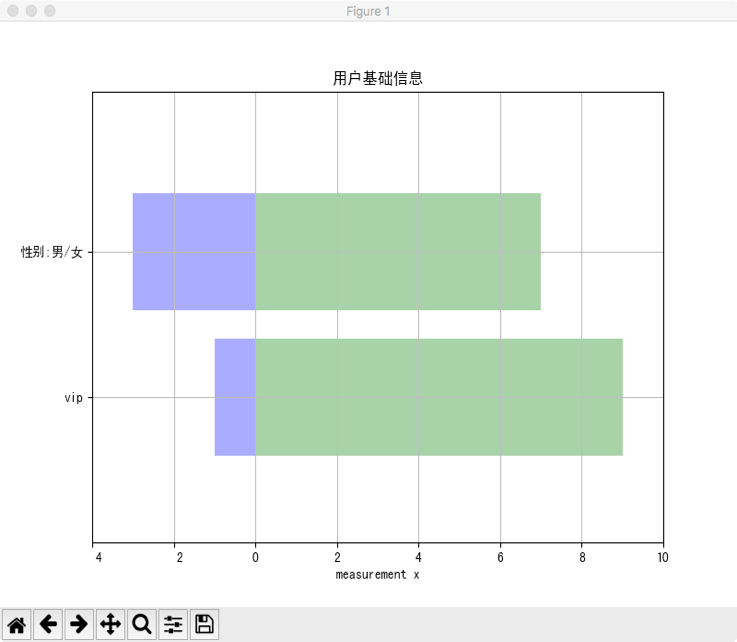
<br>运行gender.py
<br>显示男女比例,vip、非vip的比例
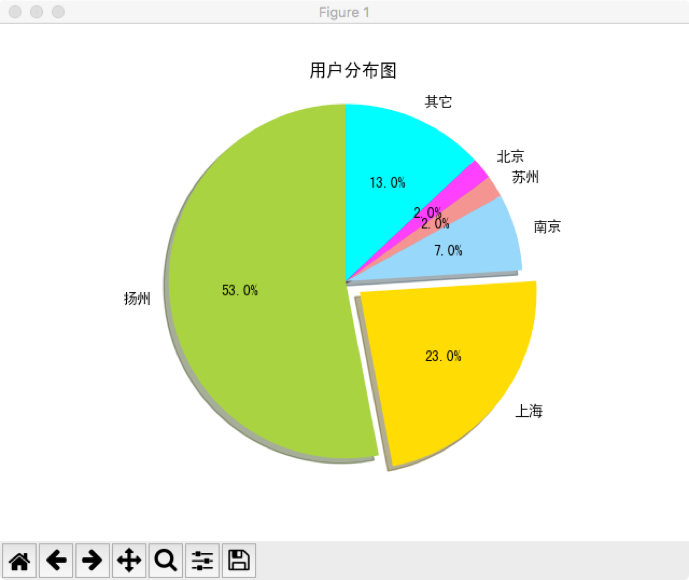
<br>运行user_location.py显示用户地理位置的分布图
<br>运行analy_shop.py分析具体商家<br>
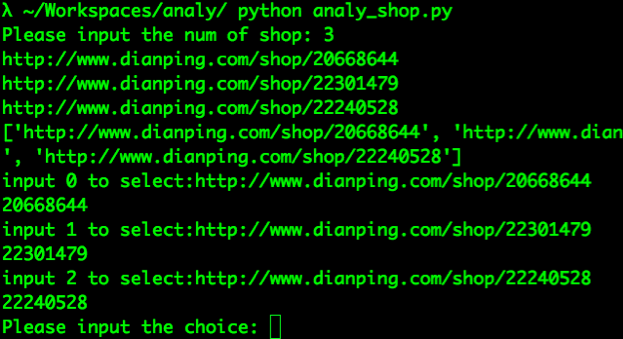
<br>程序显示几家商店,从中继续选择某一家分析
<br>生成词云<br>

scrapy抓取数据存储至本地mysql数据库-大众点评爬虫.zip

版权申诉
173 浏览量
2024-03-01
12:58:25
上传
评论
收藏 3.69MB ZIP 举报
 scrapy抓取数据存储至本地mysql数据库-大众点评爬虫.zip (56个子文件)
scrapy抓取数据存储至本地mysql数据库-大众点评爬虫.zip (56个子文件)  SJT-code
SJT-code  scrapy.cfg 260B analy
scrapy.cfg 260B analy  out.png 37KB user_location.py 1KB price.py 1KB
out.png 37KB user_location.py 1KB price.py 1KB keywords.txt 51KB yz.py 896B analy_shop.py 4KB shop_clouword.py 2KB gender.py 2KB transfer.py 2KB createsql.py 4KB user_table_shop.py 2KB table_content.py 2KB choose_foodtype.py 922B BosonNLP_sentiment_score.txt 2.41MB .idea dianping.iml 284B vcs.xml 180B misc.xml 202B inspectionProfiles profiles_settings.xml 174B modules.xml 268B .gitignore 176B dianping __init__.py 0B info.json 228KB pipelines.py 6KB settings.pyc 867B spiders __init__.py 161B dianpingspider.py 3KB user.pyc 3KB user.py 3KB comment.py 8KB __init__.pyc 141B comment.pyc 6KB dianpingspider.pyc 3KB items.py 1KB __init__.pyc 133B pipelines.pyc 5KB dbhelper.py 4KB settings.py 4KB middlewares.py 2KB items.pyc 2KB images 10.png 86KB 9.png 286KB 3.png 228KB 12.png 31KB 15.png 204KB 1.png 78KB 11.png 79KB 13.png 65KB 6.png 417KB 5.png 52KB 4.png 534KB 8.png 80KB 7.png 492KB 2.png 48KB 14.png 105KB README.md 4KB
keywords.txt 51KB yz.py 896B analy_shop.py 4KB shop_clouword.py 2KB gender.py 2KB transfer.py 2KB createsql.py 4KB user_table_shop.py 2KB table_content.py 2KB choose_foodtype.py 922B BosonNLP_sentiment_score.txt 2.41MB .idea dianping.iml 284B vcs.xml 180B misc.xml 202B inspectionProfiles profiles_settings.xml 174B modules.xml 268B .gitignore 176B dianping __init__.py 0B info.json 228KB pipelines.py 6KB settings.pyc 867B spiders __init__.py 161B dianpingspider.py 3KB user.pyc 3KB user.py 3KB comment.py 8KB __init__.pyc 141B comment.pyc 6KB dianpingspider.pyc 3KB items.py 1KB __init__.pyc 133B pipelines.pyc 5KB dbhelper.py 4KB settings.py 4KB middlewares.py 2KB items.pyc 2KB images 10.png 86KB 9.png 286KB 3.png 228KB 12.png 31KB 15.png 204KB 1.png 78KB 11.png 79KB 13.png 65KB 6.png 417KB 5.png 52KB 4.png 534KB 8.png 80KB 7.png 492KB 2.png 48KB 14.png 105KB README.md 4KB资源评论


JJJ69
- 粉丝: 6000
- 资源: 5593

下载权益

C知道特权

VIP文章

课程特权
开通VIP











