
# hand-keras-yolo3-recognize
手语图像识别系统设计
一个基于人体姿态研究的手语图像识别系统。根据OpenPose人体姿态开源模型和YOLOv3自训练手部模型检测视频和图像,再把数字特征进行分类器模型预测,将预测结果以文本形式展现出来。
预期是通过手机移动端对视频进行采集处理并应用,详见[视频](https://www.bilibili.com/video/BV1YT4y177zy/)。
# 软硬件环境
基于人体姿态的手语图像识别系统采用了软硬件相结合的方法。硬件部分主要是用于采集手语图像的单目摄像头。软件部分主要是通过ffmpeg对视频图像进行处理,然后在Anaconda下配置Python3.6的开发环境,再结合Cmake编译OpenPose模型,最后在VScode编译器中结合OpenCV中的图像算法,实现了对手语图像识别系统所有程序的编译,通过wxFromBuilder框架整合设计了系统主界面。
## 硬件环境
手语视频图像采集主要采用的硬件设备有笔记本电脑摄像头和手机摄像头。
程序运行硬件环境详细参数如下:
(1)操作系统:Windows10家庭版,64bit
(2)GPU:Intel(R) Core(TM) i5-8300H,主频:2.30GHz
(3)内存:8G
## 软件环境
(1) 视频处理工具:ffmpeg-20181115
(2) 集成开发环境:Microsoft Visual Studio Code、Anaconda3
(3) 界面设计工具:wxFromBuilder
(4) 编程语言环境:python3.6
# 系统功能设计
一个基于人体姿态研究的手语图像识别系统。根据OpenPose人体姿态开源模型和YOLOv3自训练手部模型检测视频和图像,再把数字特征进行分类器模型预测,将预测结果以文本形式展现出来。
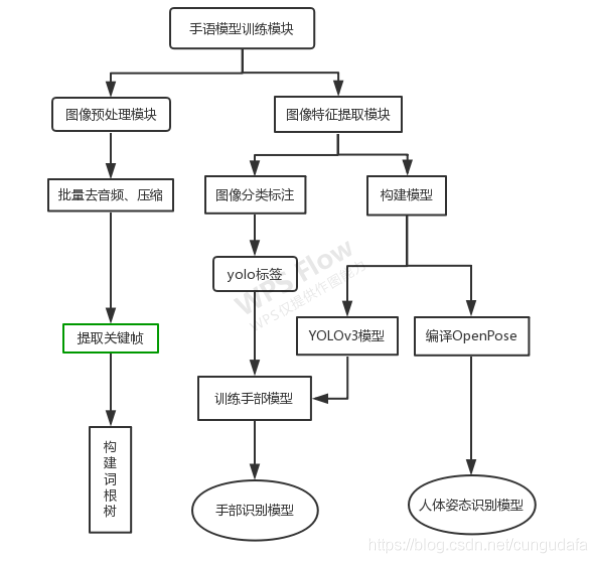
基于人体姿态的手语图像识别系统是由多模块组成的,主要分为训练模块和识别模块两个部分。

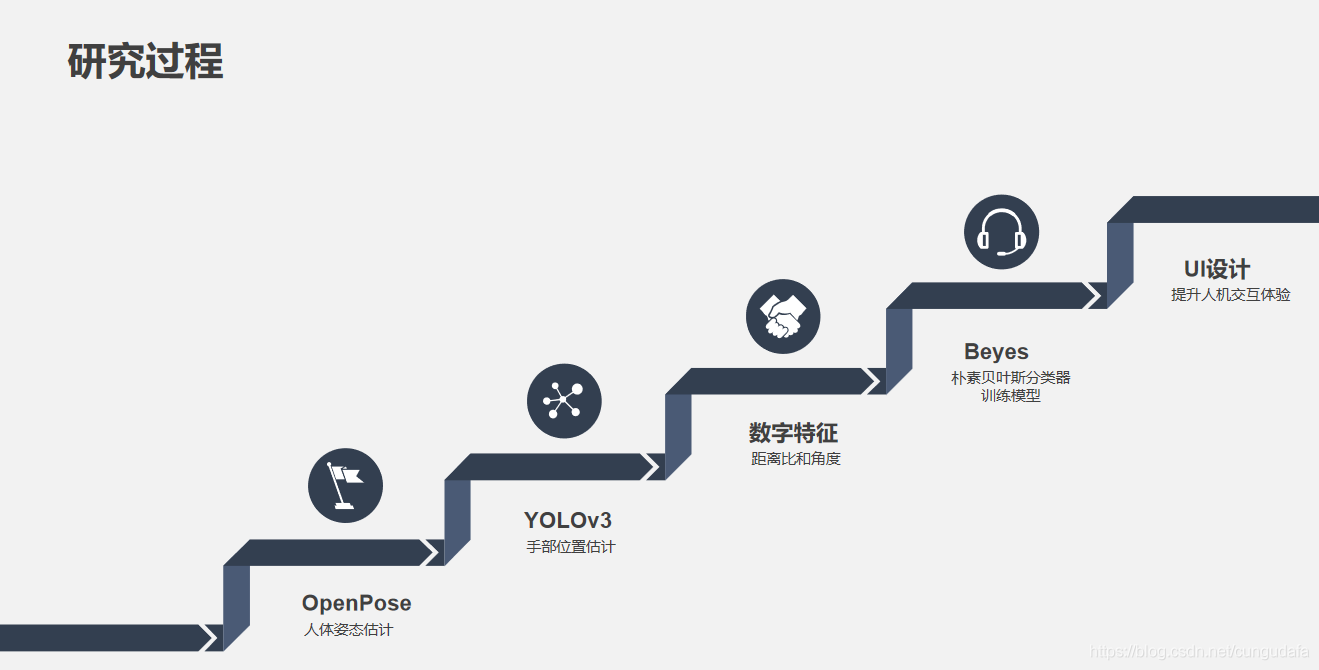
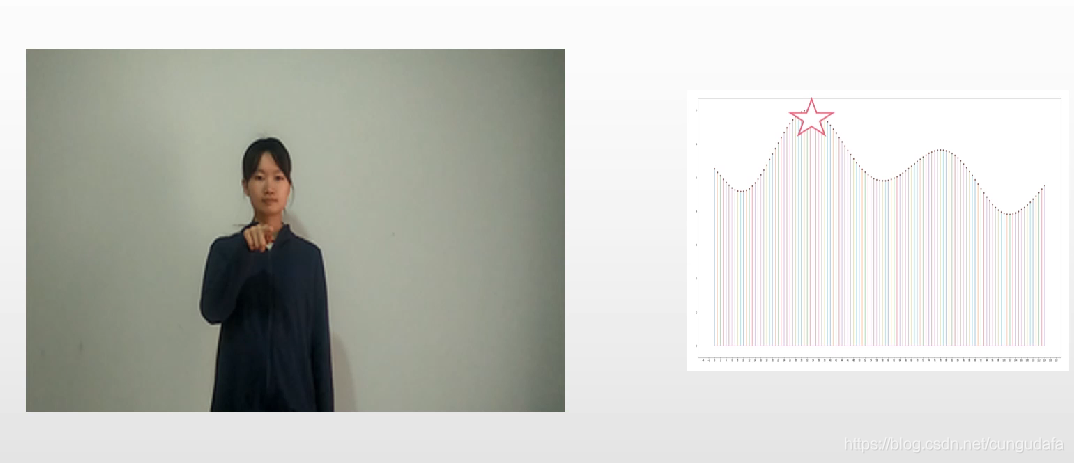
## 1. 视频帧处理
>[Python+Opencv2(三)保存视频关键帧](https://cungudafa.blog.csdn.net/article/details/104919405)

## 2. OpenPose人体姿态识别
>[Openpose人体骨骼、手势--静态图像标记及分类(附源码)](https://cungudafa.blog.csdn.net/article/details/104826071)
>
>[Openpose人体骨骼、手势--静态图像标记及分类2(附源码)](https://cungudafa.blog.csdn.net/article/details/104862703)
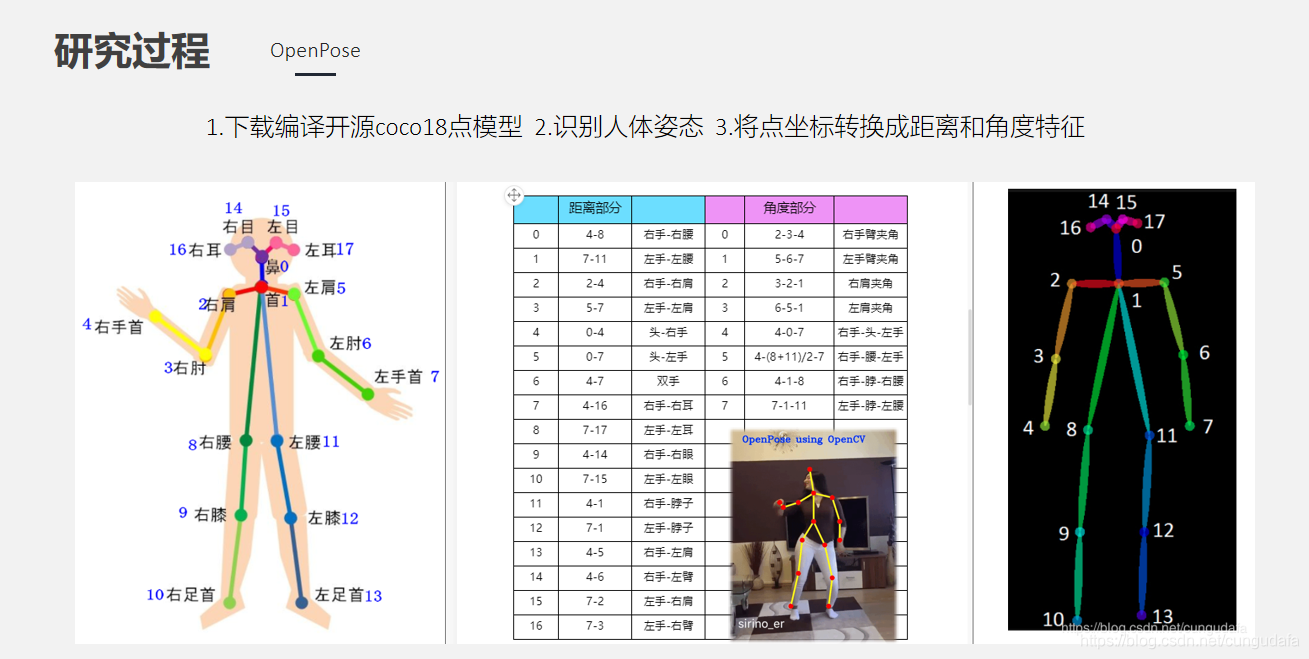
由于仅靠人体姿态4和7关键点不足以识别手部位置,容易误判,因此在最终设计中引入了yolo手部识别。

## 3. yolov3手部模型训练
项目结构主要分为两大部分:YOLOv3深度模型训练部分和YOLOv3和OpenPose手语姿态识别部分。
训练模型思路:
>环境:[【GPU】win10 (1050Ti)+anaconda3+python3.6+CUDA10.0+tensorflow-gpu2.1.0](https://blog.csdn.net/cungudafa/article/details/105089003)
>
>训练模型:[【Keras+TensorFlow+Yolo3】一文掌握图像标注、训练、识别(tf2填坑)](https://cungudafa.blog.csdn.net/article/details/105074825)
>
>识别:[【Keras+TensorFlow+Yolo3】教你如何识别影视剧模型](https://cungudafa.blog.csdn.net/article/details/105137889)
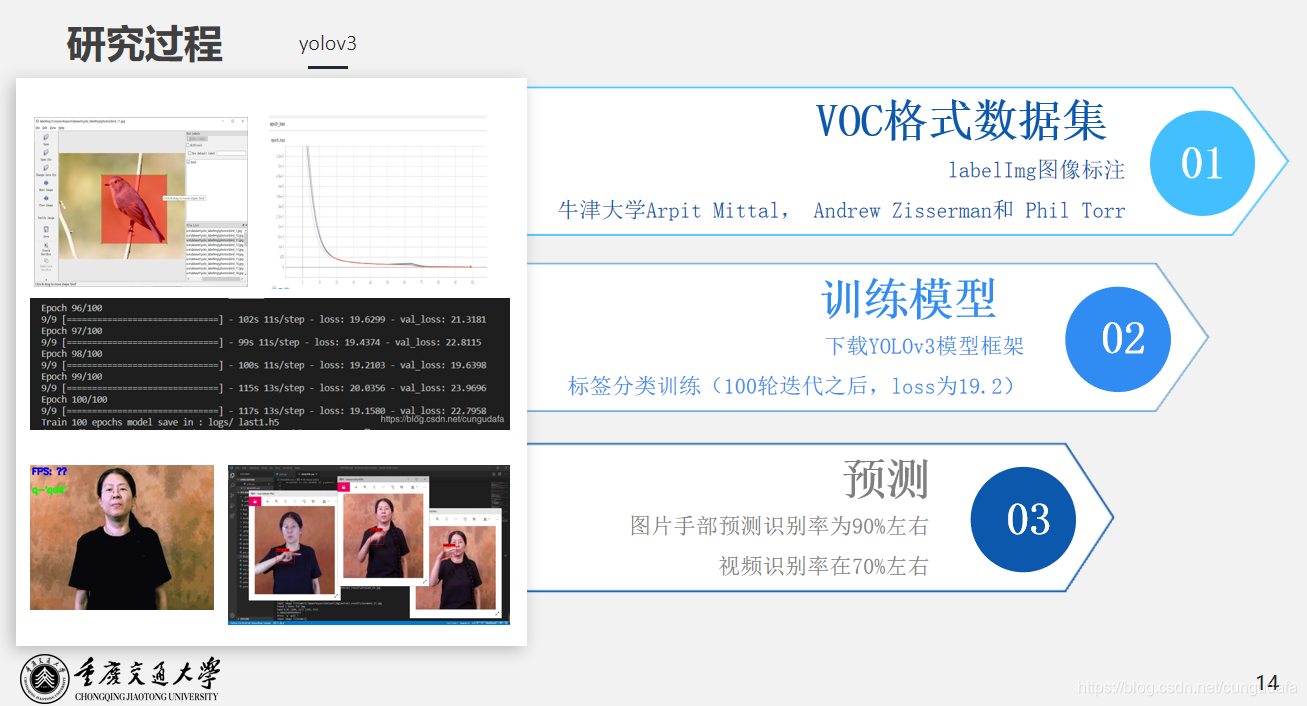
>模型训练参考代码:[https://gitee.com/cungudafa/keras-yolo3](https://gitee.com/cungudafa/keras-yolo3)
>
>yolo3识别这里参考于:[https://github.com/AaronJny/tf2-keras-yolo3](https://github.com/AaronJny/tf2-keras-yolo3)
## 4. 人体姿态数字特征提取
识别完整过程思路:
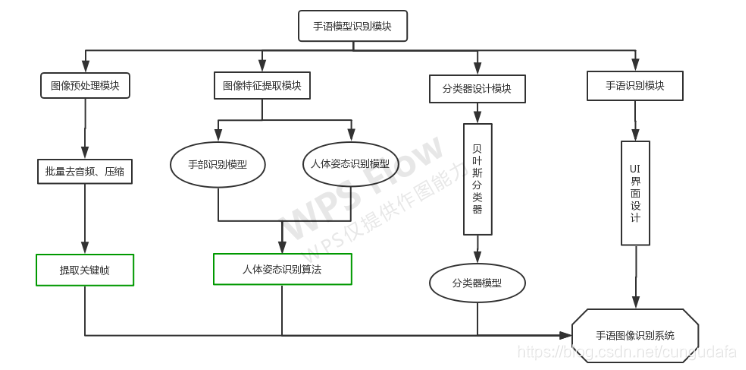
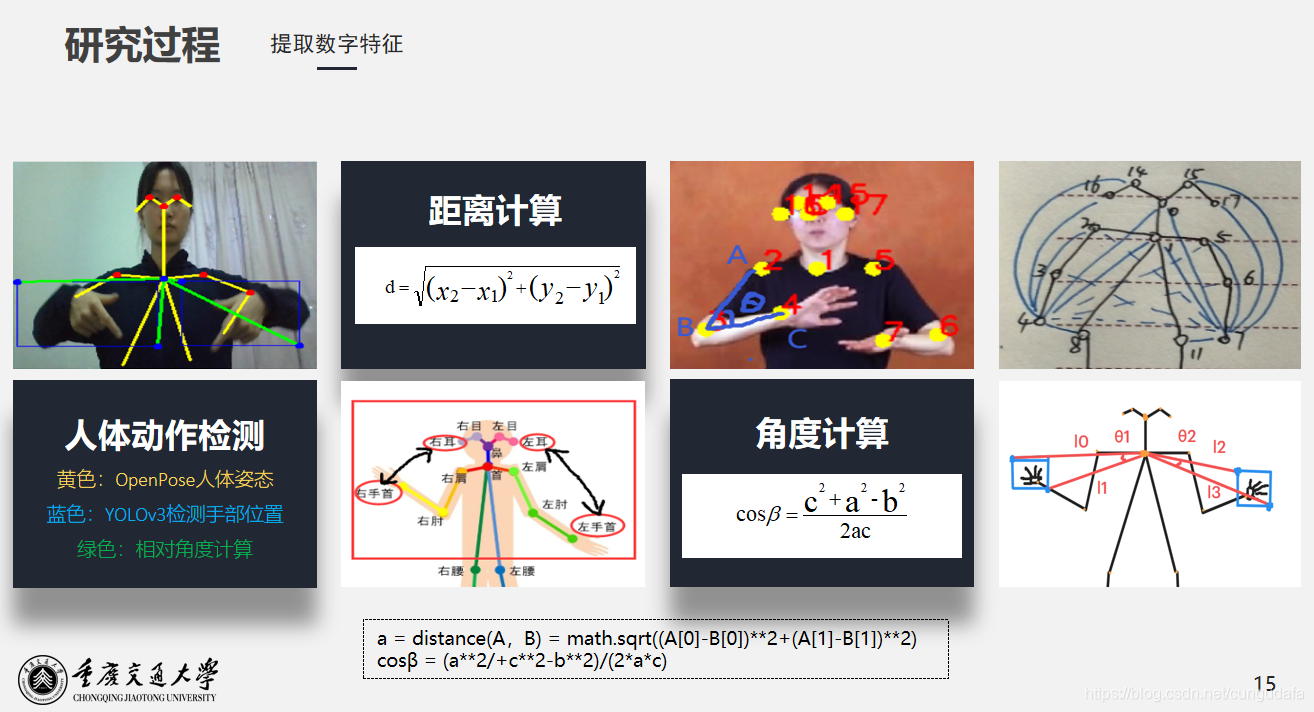
在OpenPose设计中阐述过求解距离和角度的公式及方法,最终因为个体差异每个人的骨骼可能不同,目前优化为距离比(即小臂3-4关键点的距离与脖子长度0-1关键点距离之比)。
基于 keras的yolo3训练部分项目结构如下表所示:
keras-yolo3训练项目结构:
名称 |类型 |内容
|--|--|--|
yolov3.weights |配置文件| 权重文件
yolov3.cfg |配置文件| 配置文件
convert.py| 函数| 模型格式转换
train.py| 函数 |模型训练
voc_annotation.py |函数 |voc格式标签
yolo_annotations.py |函数| yolo格式标签
yolo.py |函数 |yolo方法接口
model_data |文件夹 |参数配置
nets |文件夹 |yolo网络
utils |文件夹 |图片加载工具类
VOCdevkit |文件夹 |VOC格式数据集
logs |文件夹| h5训练的模型生成目录
其中logs文件夹用于存放训练好的模型,VOCdevkit用于存放图片和标注信息。
model_data文件夹内容:
名称 |类型| 内容
|--|--|--|
test.txt |文本| 测试图片信息
train.txt |文本 |训练图片信息
val.txt |文本| 训练测试图片信息
voc_class.txt| 文本 |标签样本名称
yolo_anchors.txt |文本| 先验参数
yolo_weights.h5| 模型 |权重文件
nets文件夹内容:
名称 |类型 |内容
|--|--|--|
darknet53.py |函数| 卷积神经网络结构
loss.py |函数| 计算图像检测效果
yolo3.py |函数 |Yolov3网络识别算法
>openpose和yolov3相结合参考:
>
>[《手语图像识别系统设计--人体动作识别》设计与实现](https://cungudafa.blog.csdn.net/article/details/106865623)
## 5.beyes分类识别
>[【Sklearn】入门花卉数据集实验--理解朴素贝叶斯分类器](https://blog.csdn.net/cungudafa/article/details/104890498)
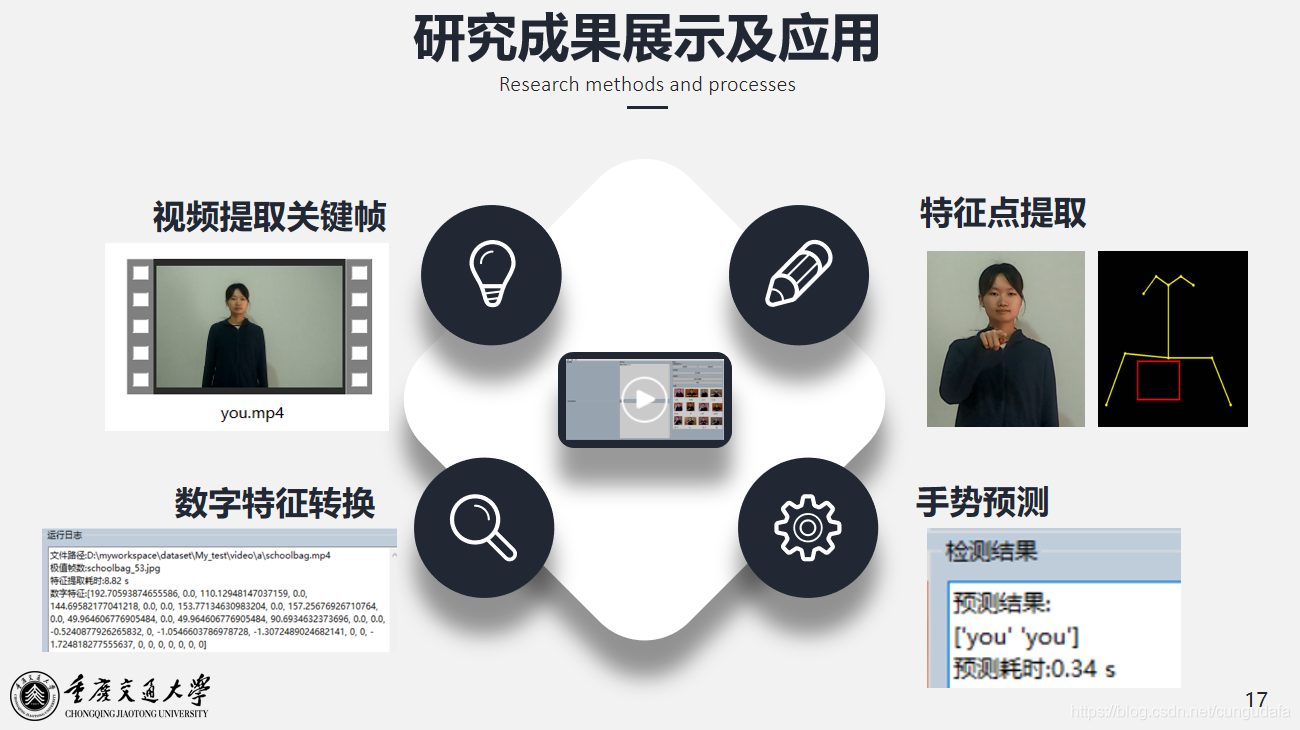
识别部分代码结构:
名称| 类型 |内容
--|--|--
filesUtils |文件夹| 文件批量处理
model| 文件夹| 模型
pose |文件夹 人体姿态识别相关算法
ui |文件夹 |界面设计
yolo3 |文件夹 |Yolov3手部识别相关算法
beyes.py |函数| 分类模型算法
getKeyFrame.py| 函数| 提取视频关键帧
pose_hand.py |函数 |人姿和手部识别综合接口
UI.py |函数| 可视化界面
yolo.py| 函数 |�
 OpenPose+YOLOv3实现的基于图像的手语识别系统研究人体动作识别.zip (44个子文件)
OpenPose+YOLOv3实现的基于图像的手语识别系统研究人体动作识别.zip (44个子文件)  hand-keras-yolo3recognize-master
hand-keras-yolo3recognize-master  yolo_video.py 2KB get_features.py 2KB LICENSE 11KB SaveImg_graphviz.py 1KB predict.py 1KB pose_hand.py 11KB
yolo_video.py 2KB get_features.py 2KB LICENSE 11KB SaveImg_graphviz.py 1KB predict.py 1KB pose_hand.py 11KB basic.png 171KB saveImg.py 3KB predict_beyes.py 1022B UI_main.py 16KB docs font FiraMono-Medium.otf 124KB
basic.png 171KB saveImg.py 3KB predict_beyes.py 1022B UI_main.py 16KB docs font FiraMono-Medium.otf 124KB SIL Open Font License.txt 4KB requirements.txt 3KB images yolov3.png 270KB iou.png 743KB darknet53.png 50KB levio.jpeg 43KB yolo_GraphvizOutput.png 58KB model_summary.txt 105KB ui
SIL Open Font License.txt 4KB requirements.txt 3KB images yolov3.png 270KB iou.png 743KB darknet53.png 50KB levio.jpeg 43KB yolo_GraphvizOutput.png 58KB model_summary.txt 105KB ui  demo.jpg 51KB favicon.ico 66KB camera.png 9KB beyes.py 5KB getKeyFrame.py 7KB model train_model.pkl 4KB pose coco.py 8KB hand_fD.py 11KB hand.py 7KB data_process.py 8KB .gitignore 1KB test.py 1KB ui signUI.fbp 104KB noname.py 7KB yolo3 utils.py 4KB __init__.py 0B model.py 17KB README.md 10KB filesUtils videoConv.bat 2KB Image_classification.py 732B removevideo.py 623B resizevideos.py 1KB resizefiles.py 2KB renamefiles.py 681B yolo.py 15KB
demo.jpg 51KB favicon.ico 66KB camera.png 9KB beyes.py 5KB getKeyFrame.py 7KB model train_model.pkl 4KB pose coco.py 8KB hand_fD.py 11KB hand.py 7KB data_process.py 8KB .gitignore 1KB test.py 1KB ui signUI.fbp 104KB noname.py 7KB yolo3 utils.py 4KB __init__.py 0B model.py 17KB README.md 10KB filesUtils videoConv.bat 2KB Image_classification.py 732B removevideo.py 623B resizevideos.py 1KB resizefiles.py 2KB renamefiles.py 681B yolo.py 15KB资源评论

 liou4567892024-11-09总算找到了想要的资源,搞定遇到的大问题,赞赞赞!
liou4567892024-11-09总算找到了想要的资源,搞定遇到的大问题,赞赞赞!- 2301_781783692024-06-09资源使用价值高,内容详实,给了我很多新想法,感谢大佬分享~

程序员张小妍
- 粉丝: 1w+
- 资源: 3474









最新资源
- 基于flink的实时数仓详细文档+全部资料.zip
- 基于Flink的数据同步工具详细文档+全部资料.zip
- 基于Flink的数据流业务处理平台详细文档+全部资料.zip
- 基于flink的物流业务数据实时数仓建设详细文档+全部资料.zip
- 外卖时间数据,食品配送时间数据集,外卖影响因素数据集(千条数据)
- 基于flink的异构数据源同步详细文档+全部资料.zip
- 基于flink的营销系统详细文档+全部资料.zip
- 基于Flink对用户行为数据的实时分析详细文档+全部资料.zip
- 基于Flink分析用户行为详细文档+全部资料.zip
- 基于flink可以创建物理表的catalog详细文档+全部资料.zip
- 基于Flink流批一体数据处理快速集成开发框架、快速构建基于Java的Flink流批一体应用程序,实现异构数据库实时同步和ETL,还可以让Flink SQL变得
- 太和-圣德西实施—部门负责人以上宣贯培训大纲.doc
- 太和-圣德西实施—部门负责人非HR的HRM培训.pptx
- 太和-圣德西实施—宣贯培训大纲.docx
- 基于Flink流处理的动态实时亿级全端用户画像系统可视化界面详细文档+全部资料.zip
- 基于Flink全端用户画像商品推荐系统详细文档+全部资料.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


