# Somiao Pinyin: Train your own Chinese Input Method with Seq2seq Model
### [中文Blog](http://www.crownpku.com/2017/09/10/%E6%90%9C%E5%96%B5%E8%BE%93%E5%85%A5%E6%B3%95-%E7%94%A8seq2seq%E8%AE%AD%E7%BB%83%E8%87%AA%E5%B7%B1%E7%9A%84%E6%8B%BC%E9%9F%B3%E8%BE%93%E5%85%A5%E6%B3%95.html)
Personalized Chinese Pinyin Input Method with Seq2seq model
Original code in https://github.com/Kyubyong/neural_chinese_transliterator for research purpose.
This repository intends to experiment with different training data and interactive user inputs, and possibly develop towards a real data-personalized and model-localized Pinyin Input product.
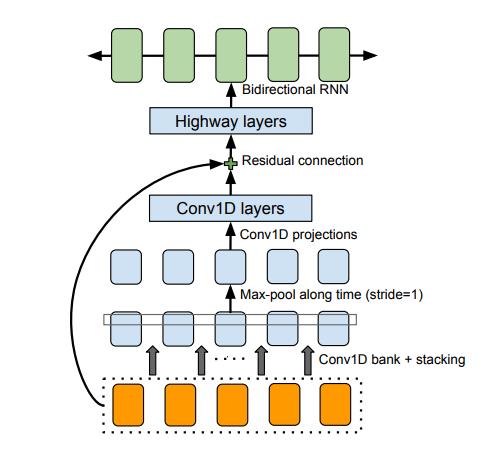
## Requrements
* Python (>=3.5)
* TensorFlow (>=r1.2)
* xpinyin (for Chinese pinyin annotation)
* distance (for calculating the similarity score between two strings)
* tqdm
## Usage
### Training:
* STEP 1. Download [Leipzig Chinese Corpus](http://wortschatz.uni-leipzig.de/en/download/)
Extract it and copy zho_news_2007-2009_1M-sentences.txt to data/ folder.
Or use your own Chinese Corpus with the same format.
* STEP 2. Build a Pinyin-Chinese parallel corpus.
```
#python3 build_corpus.py
```
* STEP 3. Run `prepro.py` to make vocabulary and training data.
```
#python3 prepro.py
```
* STEP 4. Adjust hyperparameters in `hyperparams.py` if necessary.
* STEP 5. Train the model
```
#python3 train.py
```
### Inference with command line input:
For command line input testing, run:
```
python3 eval.py
```
You may change the main function name to use the original testing data evaluation.
### Testing with pre-trained models:
Download the pre-trained model from [blog](http://www.crownpku.com/2017/09/10/%E6%90%9C%E5%96%B5%E8%BE%93%E5%85%A5%E6%B3%95-%E7%94%A8seq2seq%E8%AE%AD%E7%BB%83%E8%87%AA%E5%B7%B1%E7%9A%84%E6%8B%BC%E9%9F%B3%E8%BE%93%E5%85%A5%E6%B3%95.html), unzip it to generate /log and /data.
Remember to overwrite the pickle files in /data with the pre-trained model data.
Then run for command line input testing:
```
python3 eval.py
```
## Sample Results
Model is trained from Chinese News in 2007-2009. So many now common Chinese sayings are not learned.
```
请输入测试拼音:nihao
你好
请输入测试拼音:chenggongle
成功了
请输入测试拼音:wolegequ
我了个曲
请输入测试拼音:taibangla
太棒啦
请输入测试拼音:dacolehuizenmeyang
打破了会怎么样
请输入测试拼音:pujinghehujintaotongdianhua
普京和胡锦涛通电话
请输入测试拼音:xiangbuqilaishinianqianfashengleshenme
想不起来十年前发生了什么
请输入测试拼音:meiguohongzhawomenzainansilafudedashiguan
美国轰炸我们在南斯拉夫的大事馆
请输入测试拼音:liudehuanageshihouhaonianqing
刘德华那个时候好年轻
请输入测试拼音:shishihouxunlianyixiabilibilideyuliaole
是时候训练一下比例比例的预料了
```
## TODOLIST
* Pretrained models on different contexts
* Model selection for using different models while input different things (chatting? writing scientific papers? etc...)
* Function to record LOCALLY what user has input as personalized corpus
* User Interface
* ...
Python实现基于深度学习的中文语音识别系统源码+文档说明(毕业设计).zip

版权申诉
 基于深度学习的中文语音识别系统.zip (88个子文件)
基于深度学习的中文语音识别系统.zip (88个子文件)  主-master acoustic_model
主-master acoustic_model  gru_ctc_am.py 11KB cnn_with_full_data.py 9KB data primewords dev.wav.lst 436KB test.wav.lst 443KB train.wav.lst 3.44MB
gru_ctc_am.py 11KB cnn_with_full_data.py 9KB data primewords dev.wav.lst 436KB test.wav.lst 443KB train.wav.lst 3.44MB test.syllabel.txt 552KB dev.syllabel.txt 547KB train.syllabel.txt 4.29MB st-cmds dev.wav.lst 39KB test.wav.lst 129KB train.wav.lst 6.29MB test.syllabel.txt 145KB dev.syllabel.txt 44KB train.syllabel.txt 7.06MB thchs30 dev.wav.lst 31KB test.wav.lst 91KB train.wav.lst 371KB test.syllabel.txt 420KB dev.syllabel.txt 151KB train.syllabel.txt 1.64MB aishell dev.wav.lst 909KB test.wav.lst 463KB train.wav.lst 7.67MB test.syllabel.txt 638KB dev.syllabel.txt 1.22MB train.syllabel.txt 10.3MB cnn_ctc_am.py 12KB cnn_with_fbank.py 14KB extra_utils __init__.py 0B feature_extract.py 2KB commons.py 516B FSMNCell.py 3KB GetData.py 20KB .gitattributes 66B some_expriment lm_develop eval.py 2KB data_load.py 4KB hyperparams.py 600B build_corpus.py 3KB modules.py 13KB prepro.py 3KB train.py 4KB README.md 3KB gen_data gen_aishell_lable.py 2KB gen_thchs_lable.py 3KB linshi.py 13KB keras_test.py 2KB train.wav.lst 3.45MB my_develop.py 14KB data_process read_data_prime.py 23KB gen_dict.py 13KB aishell_pre.py 5KB datalist primewords dev.wav.lst 436KB test.wav.lst 443KB train.wav.lst 3.44MB test.syllabel.txt 552KB dev.syllabel.txt 547KB train.syllabel.txt 4.29MB read_prim_data.py 2KB st-cmds test.wav.txt 129KB train.wav.txt 6.29MB test.syllabel.txt 145KB dev.syllabel.txt 44KB dev.wav.txt 39KB train.syllabel.txt 7.06MB thchs30 dev.wav.lst 31KB test.wav.lst 91KB train.wav.lst 371KB test.syllabel.txt 423KB dev.syllabel.txt 151KB train.syllabel.txt 1.65MB .st-cmds.swp 12KB aishell dev.wav.lst 909KB test.wav.lst 463KB train.wav.lst 7.67MB test.syllabel.txt 638KB dev.syllabel.txt 1.22MB train.syllabel.txt 10.3MB read_data_aishell.py 22KB dict.txt 32KB read_prim_data.py 2KB 使用说明.txt 3KB .gitignore 433B language_model CBHG_lm.py 16KB model_layers.py 13KB hyperparams.py 600B data vocab.pkl 158KB lable.txt 11.84MB zh.tsv 23.69MB
test.syllabel.txt 552KB dev.syllabel.txt 547KB train.syllabel.txt 4.29MB st-cmds dev.wav.lst 39KB test.wav.lst 129KB train.wav.lst 6.29MB test.syllabel.txt 145KB dev.syllabel.txt 44KB train.syllabel.txt 7.06MB thchs30 dev.wav.lst 31KB test.wav.lst 91KB train.wav.lst 371KB test.syllabel.txt 420KB dev.syllabel.txt 151KB train.syllabel.txt 1.64MB aishell dev.wav.lst 909KB test.wav.lst 463KB train.wav.lst 7.67MB test.syllabel.txt 638KB dev.syllabel.txt 1.22MB train.syllabel.txt 10.3MB cnn_ctc_am.py 12KB cnn_with_fbank.py 14KB extra_utils __init__.py 0B feature_extract.py 2KB commons.py 516B FSMNCell.py 3KB GetData.py 20KB .gitattributes 66B some_expriment lm_develop eval.py 2KB data_load.py 4KB hyperparams.py 600B build_corpus.py 3KB modules.py 13KB prepro.py 3KB train.py 4KB README.md 3KB gen_data gen_aishell_lable.py 2KB gen_thchs_lable.py 3KB linshi.py 13KB keras_test.py 2KB train.wav.lst 3.45MB my_develop.py 14KB data_process read_data_prime.py 23KB gen_dict.py 13KB aishell_pre.py 5KB datalist primewords dev.wav.lst 436KB test.wav.lst 443KB train.wav.lst 3.44MB test.syllabel.txt 552KB dev.syllabel.txt 547KB train.syllabel.txt 4.29MB read_prim_data.py 2KB st-cmds test.wav.txt 129KB train.wav.txt 6.29MB test.syllabel.txt 145KB dev.syllabel.txt 44KB dev.wav.txt 39KB train.syllabel.txt 7.06MB thchs30 dev.wav.lst 31KB test.wav.lst 91KB train.wav.lst 371KB test.syllabel.txt 423KB dev.syllabel.txt 151KB train.syllabel.txt 1.65MB .st-cmds.swp 12KB aishell dev.wav.lst 909KB test.wav.lst 463KB train.wav.lst 7.67MB test.syllabel.txt 638KB dev.syllabel.txt 1.22MB train.syllabel.txt 10.3MB read_data_aishell.py 22KB dict.txt 32KB read_prim_data.py 2KB 使用说明.txt 3KB .gitignore 433B language_model CBHG_lm.py 16KB model_layers.py 13KB hyperparams.py 600B data vocab.pkl 158KB lable.txt 11.84MB zh.tsv 23.69MB资源评论

 weixin_545217122024-03-25实在是宝藏资源、宝藏分享者!感谢大佬~
weixin_545217122024-03-25实在是宝藏资源、宝藏分享者!感谢大佬~ qq_354164322024-05-15内容与描述一致,超赞的资源,值得借鉴的内容很多,支持!
qq_354164322024-05-15内容与描述一致,超赞的资源,值得借鉴的内容很多,支持!- m0_663717622024-05-04发现一个宝藏资源,赶紧冲冲冲!支持大佬~
- 2301_763185822024-05-13感谢资源主的分享,这个资源对我来说很有用,内容描述详尽,值得借鉴。












