Searching for MobileNetV3
需积分: 10 68 浏览量
2022-11-01
16:20:41
上传
评论
收藏 2.27MB PDF 举报

探索 MobileNetV3
摘要
我们提出了基于互补搜索技术下一代 MobileNet,并设计了新的网络结构。
通过结合硬件网络架构搜索(NAS)和 NetAdapt 算法,MobileNetV3 被调优为移动
电话 CPU,然后通过新的架构进行改进。本文开始探索自动搜索算法和网络设计
如何协同工作,以利用互补的方法改善整体技术水平。通过这个过程,我们为发
布了两个新的 MobileNet 模型:MobileNetV3-Large 和 MobileNetV3-Small,它们针
对高和低质量资源的使用。然后将这些模型应用到目标检测和语义分割任务中。
针对语义分割(或任何密集像素预测)的任务,我们提出了一种新的高效 分割解
码器 Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP)。我们实现了移动分类、
检测和分割的最新成果。与 MobileNetV2 相比,MobileNetV3-Large 在 ImageNet
分类上的准确率提高了 3.2%,同时减少了 20%的延迟。MobileNetV3-Small 是与
具有相同延迟的 MobileNetV2 模型相比,精度提高了 6.6%。MobileNetV3-Large
检测速度比 MobileNetV2 COCO 检测的准确率快 25%以上。MobileNetV3-Large
LRASPP 比 MobileNetV2 R-ASPP 快 34%,在城市景观分割的精度相似。
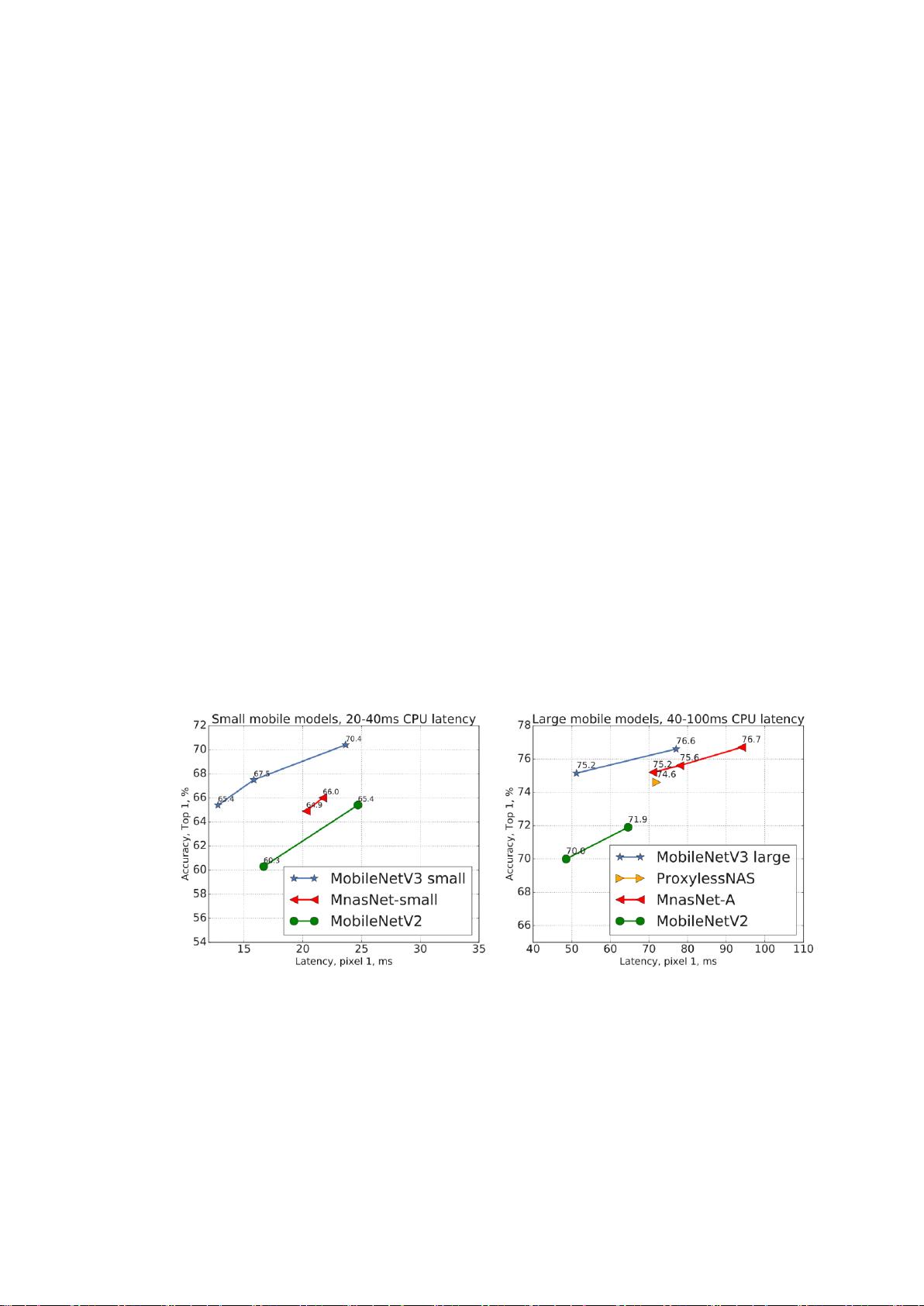
图 1.Pixel 1 延迟和 top-1 ImageNet 精度之间的权衡。所有型号均使用输入分
辨率 224。V3 大和 V3 小使用乘数 0.75,1 和 1.25 来表示最优边界。使用 TFLite[1]
在同一设备的单个大核上测量所有延迟。MobileNetV3-Small 和 Large 是我们提
出的下一代移动模型。



剩余17页未读,继续阅读
资源评论


长沙有肥鱼
- 粉丝: 1w+
- 资源: 15









最新资源
- 三维装箱问题(Three-Dimensional Bin Packing Problem,3D-BPP)是一个经典的组合优化问题
- 以下是一些关于Linux线程同步的基本概念和方法.txt
- 以下是一个简化的示例,它使用pygame库来模拟烟花动画的框架.txt
- Linux线程同步机制深度解析与实用指南.zip
- PTA题库C语言解题策略与实战.rar
- SVPWM控制技术的simulink建模与仿真【包括simulink模型,参考文献,操作步骤】
- AI高清修复图片画质易语言易语言源码易语言填表
- 映射窗口.ec易语言易语言模块CPU占用0%游戏监控窗口监控
- 易语言 361窗口模块高效、便捷、自封装、自用
- 易语言 窗口排列 模块 ,简单、高效、体积小
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


