无卷积步长或池化:用于低分辨率图像和小物体的新 CNN 模块SPD-Conv
需积分: 23 195 浏览量
2022-10-06
16:03:27
上传
评论 4
收藏 1.91MB PDF 举报


无卷积步长或池化:用于低分辨率图像和小
物体的新 CNN 模块 SPD-Conv
摘要
卷积神经网络(CNNs)在图像分类和目标检测等计算机视觉任务中取得了显
著的成功。然而,当图像分辨率较低或物体较小时,它们的性能会迅速下降。在
本文中,我们指出这根源为现有 CNN 常见的设计体系结构中一个有缺陷,即使
用卷积步长和/或池化层,这导致了细粒度信息的丢失和较低效的特征表示的学
习。为此,我们提出了一个名为 SPD-Conv 的新的 CNN 构建块来代替每个卷积
步长和每个池化层(因此完全消除了它们)。SPD-Conv 由一个空间到深度(SPD)层
和一个无卷积步长(Conv)层组成,可以应用于大多数 CNN 体系结构(如果不是全
部的话)。我们从两个最具代表性的计算机视觉任务:目标检测和图像分类来解释
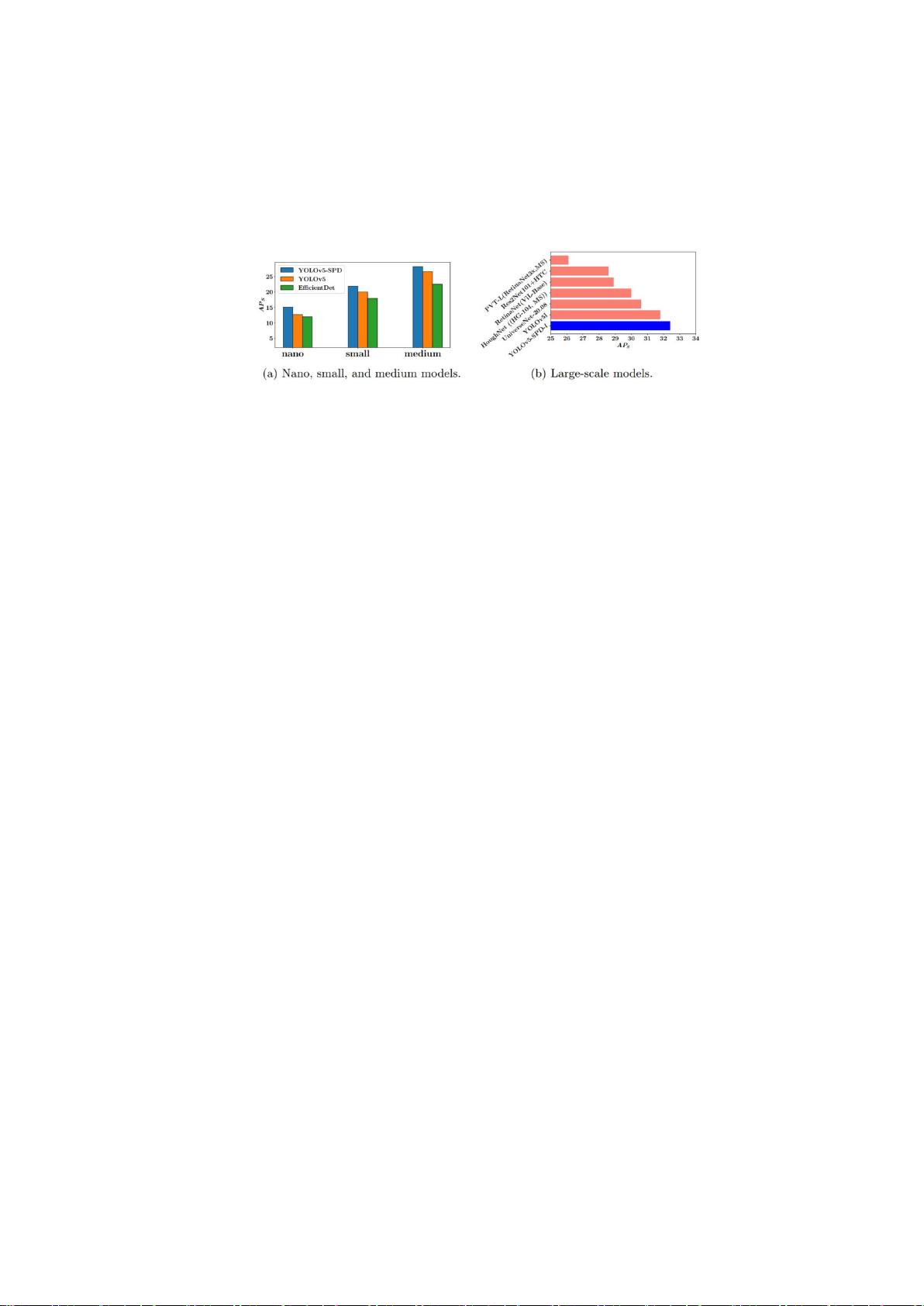
这个新设计。然后,我们将 SPD-Conv 应用于 YOLOv5 和 ResNet,创建了新的
CNN 架构,并通过经验证明,我们的方法明显优于最先进的深度学习模型,特
别 是 在 处 理 低 分 辨 率 图 像 和 小 物 体 等 更 困 难 的 任 务 时 。 我 们 在
https://github.com/LabSAINT/SPD-Conv 上开放了源代码。
1.介绍
自 AlexNet[18]以来,卷积神经网络(CNNs)在许多计算机视觉任务中表现出
色。例如在图像分类方面,CNN 的知名模型有 AlexNet、VGGNet[30]、ResNet[13]
等;在目标检测中,包括 R-CNN 系列[9,28],YOLO 系列[26,4],SSD [24],
EfficientDet [34],等等。然而,所有这样的 CNN 模型在训练和推理中都需要“高
质量”的输入(精细图像、中型到大型对象)。例如,AlexNet 最初在 227×227 清晰
图像上进行训练和推理,但在将图像分辨率降低到 1/4 和 1/8 后,其分类准确率
分别下降了 14%和 30%,[16]。VGGNet 和 ResNet too[16]上也有类似的情况。在
目标检测的情况下,SSD 在 1/4 分辨率的图像或相当于 1/4 较小尺寸的目标上受
到显著的 mAP 损失 34.1,如文献[11]所描述的那样。事实上,小物体检测是一项
非常具有挑战性的任务,因为小物体固有的分辨率较低,而且可供模型学习的背
景信息也有限。此外,它们经常(不幸地)与同一图像中的大型目标共存,而大型
目标往往会主导特征学习过程,从而使小型目标无法被检测到。


剩余15页未读,继续阅读
资源评论













