
YOLOv4:目标检测的最佳速度和精度
摘要
有大量的特征据说可以提高卷积神经网络(CNN)的准确性。需要在大数据集
上对这些特征的组合进行实际测试,并对结果进行理论论证。有些特性仅适用于
某些模型和某些问题,或仅适用于小规模的数据集; 而一些特性,如批处理规范
化和残差连接,适用于大多数模型、任务和数据集。我们假设这些通用特征包括
加权残差连接(Weighted-Residual-Connections, WRC),跨阶段部分连接(CSP),跨
小批量标准化(CmBN)、自我对抗训练(SAT)和 mishish -activation。我们使用了新
的特征:WRC, CSP,CmBN, SAT, Mish 激活函数,Mosaic 数据增强,CmBN,
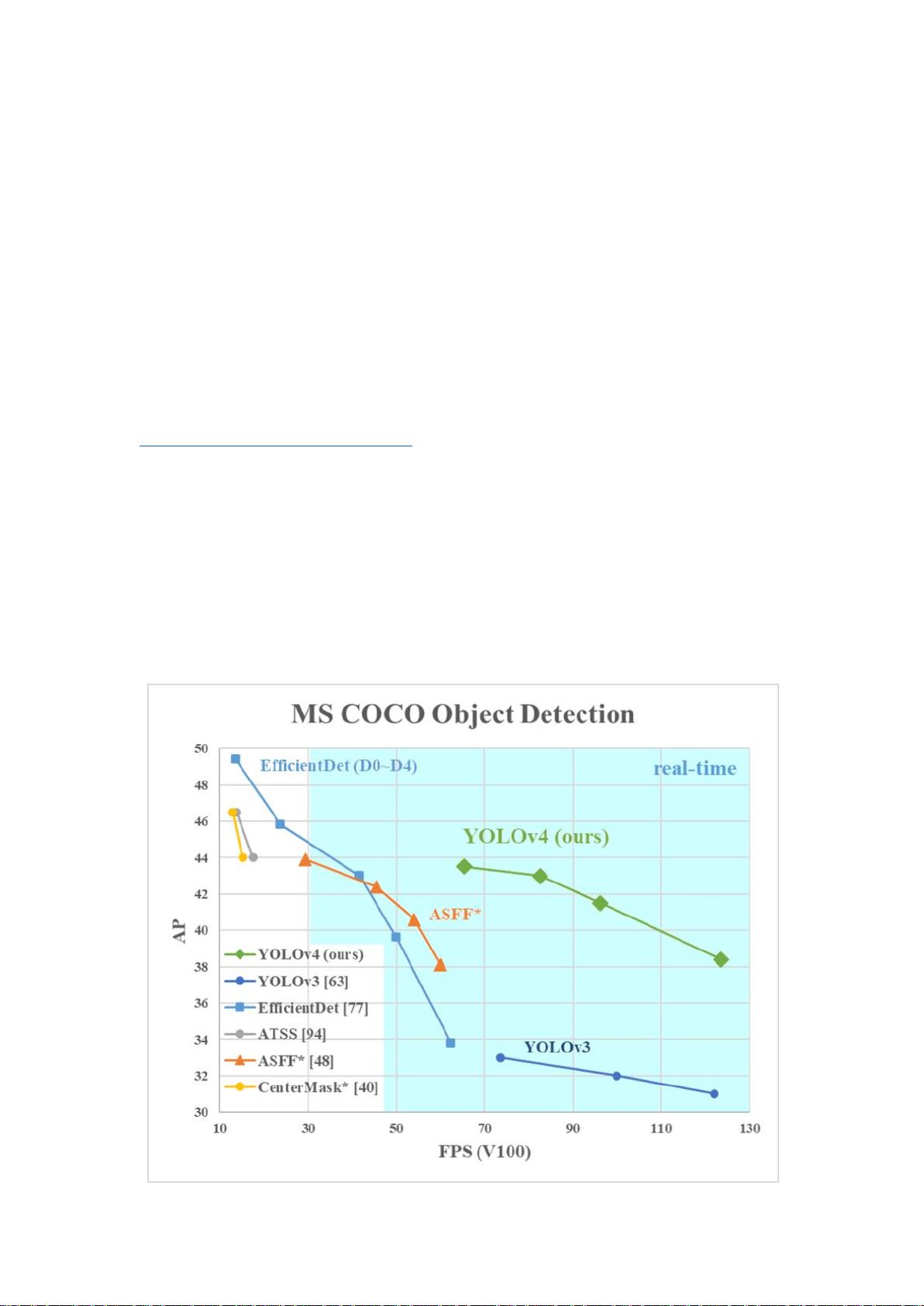
DropBlock 正则化,CIoU 损失,并结合其中一些,达到最佳的结果: 43.5% AP (65.7%
AP50) 时在 Tesla V100 上,MS COCO 数据集的实时速度为 65 FPS。源代码见
https://github.com/AlexeyAB/darknet.
1.介绍
大多数基于 cnn 的目标检测器在很大程度上只适用于推荐系统。例如,通过城市
摄像机搜索免费停车位是由慢速精确模型执行的,而汽车碰撞预警则与快速不准
确模型相关。通过提高实时对象检测器的精度,不仅可以将其用于提示生成推荐
系统,还可以用于独立流程管理和减少人工输入。实时物体检测器操作的传统图
形处理单元(GPU)允许其大规模使用在一个负担得起的价格。最精确的现代神经
网络不是实时操作的,需要大量的 GPU 来进行大规模的小批处理训练。我们通
过创建一个在传统 GPU 上实时运行的 CNN 来解决这些问题,而训练只需要一
个传统的 GPU。




剩余29页未读,继续阅读

长沙有肥鱼
- 粉丝: 1w+
- 资源: 15









最新资源
- hadoop ipc-hadoop
- bootshiro-springboot
- 微信文章爬虫 Reptile-爬虫
- AwesomeUnityTutorial-unity
- STM32多功能小车-stm32
- blog-vscode安装
- ultralytics-yolov11
- Image processing based on matlab-matlab下载
- 即用即查XML数据标记语言参考手册pdf版最新版本
- XML轻松学习教程chm版最新版本
- 《XMLHTTP对象参考手册》CHM最新版本
- 单机版锁螺丝机工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- 注册程序示例示例示例示例示例
- 网络实践2222222
- kotlin coroutine blogs
- Windchill前端测试工具class文件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0