





浪潮优派 TF 项目实战总结报告
1
《链家房屋信息项目实战》
技术总结报告
年级
2020 级
班级
信息管理与信息系统二班
姓名
孟令强
教师
吴瑕
成绩
山东浪潮优派教育科技有限公司
1. 软件开发流程(
可说明软件的开发流程包括几个阶段,每个阶段
做什么任务,出什么文档
)
(1)项目要求

浪潮优派 TF 项目实战总结报告
2
了解本项目需要干什么内容,根据本项目的需求,形成一份
详细计划说明书。
(2)项目需求分析
以链家的二手房信息为爬取对象,通过使用 python 中
Scrapy 方法,分析链家二手房的房屋信息的格式,编写代码,
完成项目。
根据房屋列表页的 URL 地址构造规律,动态设置 URL 末端的
页数来获取全部房屋详情页的 URL 地址。这个获取过程涉及两个
循环:页数循环和每页的房屋列表循环;前者是循环 100 页的房
屋列表,后者获取每页房屋列表的房屋详情页 URL 地址。
房屋详情页的 URL 地址末端的一串数字代表房屋 ID,用来
标记房屋的唯一性。在房屋详细页里除了爬取房屋的基本信息之
外,还有能爬取小区详情页的 URL 地址,从而访问小区详情页爬
取小区信息。
小区详情页的 URL 地址末端的一串数字代表小区 ID,这是
标记小区的唯一性。在小区详情页爬取小区基本信息之外,还要
将小区和房屋的数据相互关联,因为会出现一个小区有多套房屋
出售的情况。
(3)创建项目
创建 Scrapy 爬虫项目,在项目中的 spiders 文件夹里创建
houseSpider.py 文件,该文件用来实现 Spider 功能,用于编写
爬 虫 规 则 ; 在 配 置 文 件 settings.py 的 同 一 目 录 下 创 建
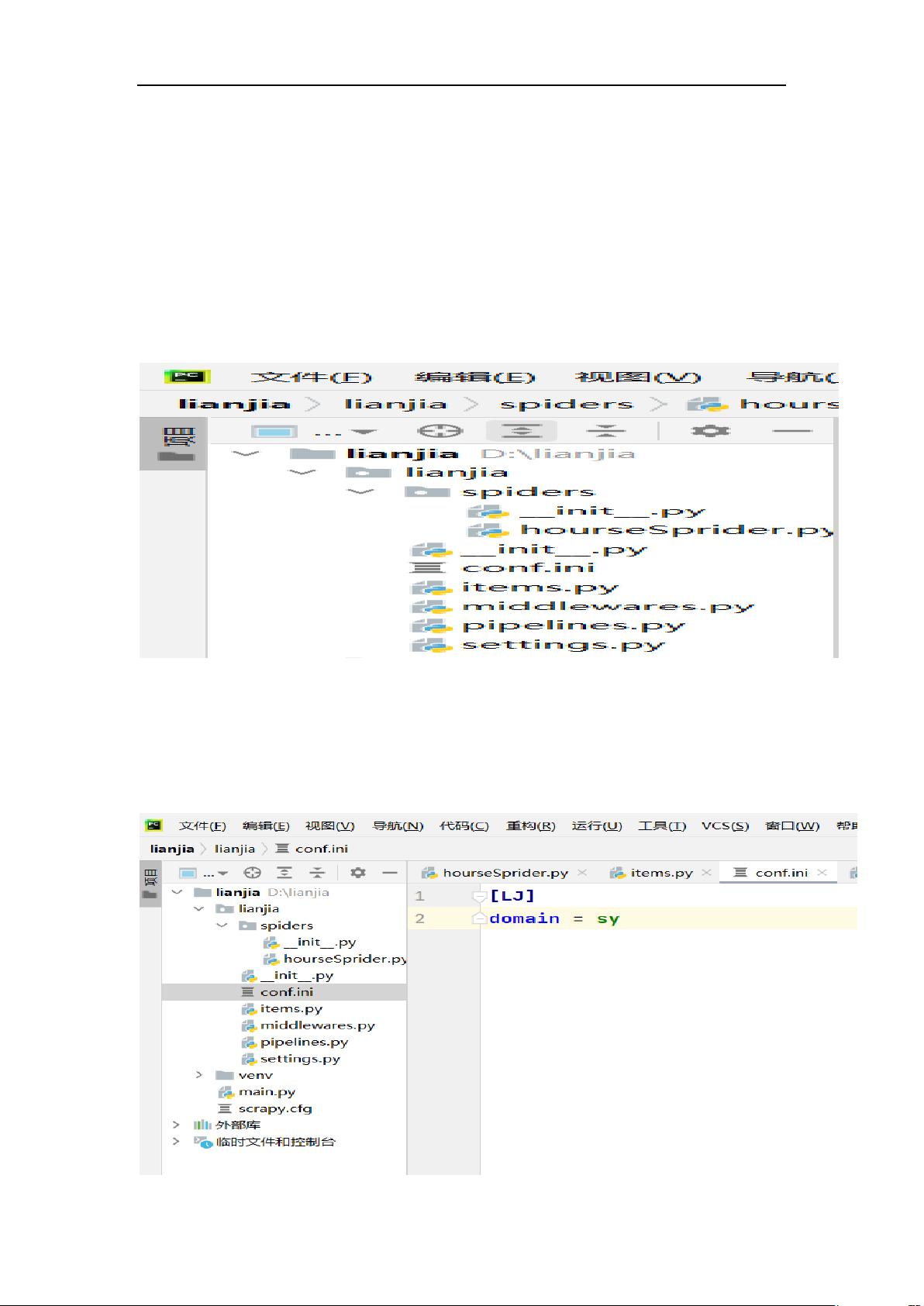
浪潮优派 TF 项目实战总结报告
3
conf.ini 配置文件,conf.ini 文件用于动态设置各个城市的域
名信息。
(4)项目配置
从网站分析结果来看,整个项目的开发难度相对较为简单,
三个页面的 URL 地址构造规律、响应内容和数据位置都一目了然。
因此,项目 lianjia 只需使用 Scrapy 的基本配置即可。
2. 项目整体功能概要
(大体说明整个项目的功能)
通 过 爬 虫 在 浏 览 器 上 爬 取 链 家 二 手 房 的 网 址
(https://gz.lianjia.com/ershoufang/pg1/),在房屋详细页里
爬取房屋的基本信息,在小区详情页,爬取小区基本信息,并且
将相关的信息存储到 MySql 数据库中。
3. 团队组成说明(
标明组长、组员及各自分担模块名
)
独立完成
4. 个人承担的开发任务说明
(标明个人模块的完成情况,所开发
的每个模块功能详细说明及界面)
(1)建立工程后可得到如下图示:

浪潮优派 TF 项目实战总结报告
4
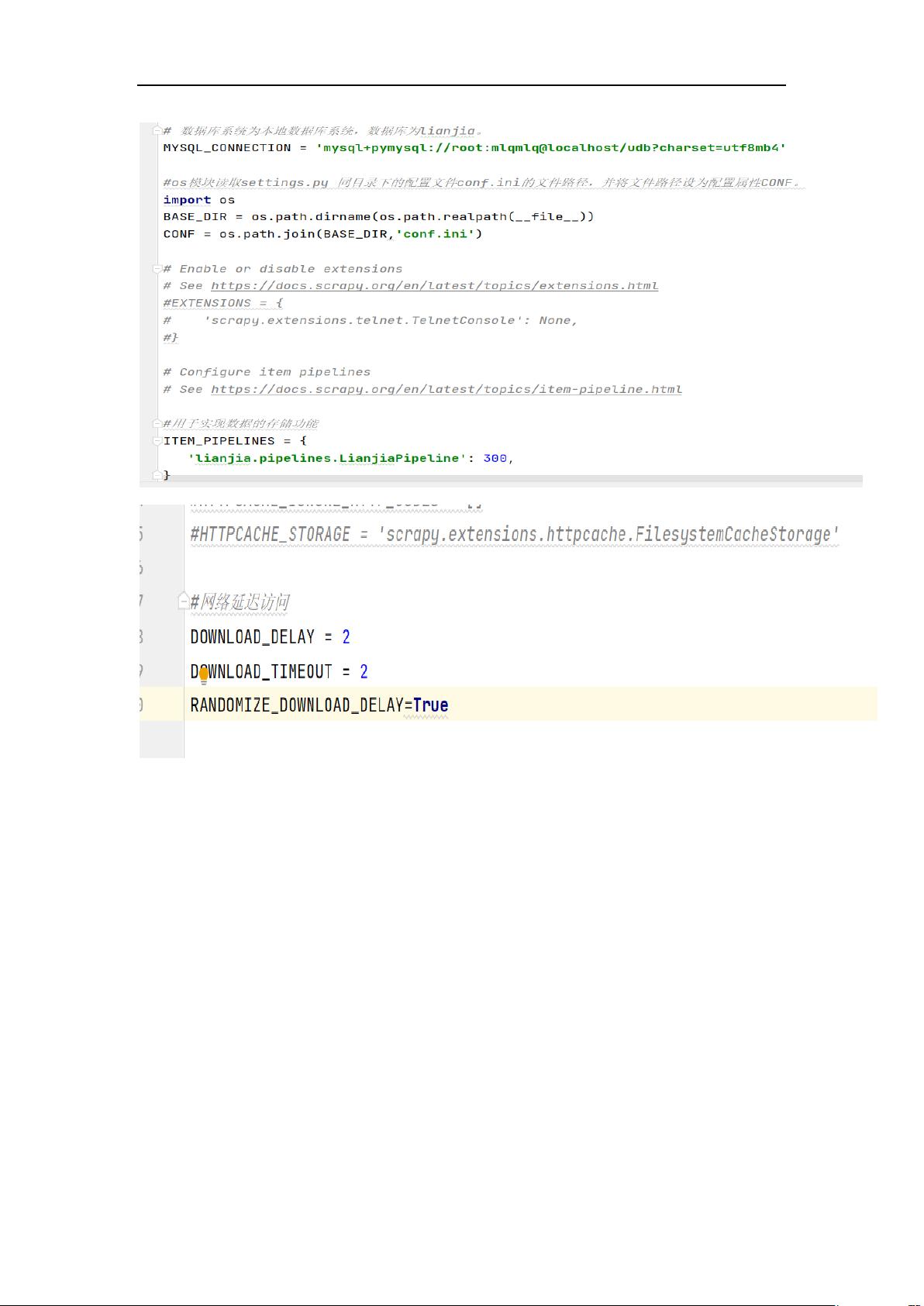
( 2 ) 在 项 目 的 配 置 文 件 settings.py 的 同 一 目 录 下 创 建
conf.ini 配置文件,conf.ini 文件用于动态设置各个城市的域
名信息。如图所示:
(3)从网站分析结果来看,整个项目的开发难度相对较为简
单,三个页面的 URL 地址构造规律、响应内容和数据位置都一目
了然。因此,项目 lianjia 只需使用 Scrapy 的基本配置即可,
配置代码如下:
浪潮优派 TF 项目实战总结报告
5













